 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReFineVLA: Reasoning-Aware Teacher-Guided Transfer Fine-Tuning
May 25, 2025



Vision-Language-Action (VLA) models have gained much attention from the research community thanks to their strength in translating multimodal observations with linguistic instructions into robotic actions. Despite their recent advancements, VLAs often overlook the explicit reasoning and only learn the functional input-action mappings, omitting these crucial logical steps for interpretability and generalization for complex, long-horizon manipulation tasks. In this work, we propose \textit{ReFineVLA}, a multimodal reasoning-aware framework that fine-tunes VLAs with teacher-guided reasons. We first augment robotic datasets with reasoning rationales generated by an expert teacher model, guiding VLA models to learn to reason about their actions. Then, we use \textit{ReFineVLA} to fine-tune pre-trained VLAs with the reasoning-enriched datasets, while maintaining their inherent generalization abilities and boosting reasoning capabilities. In addition, we conduct an attention map visualization to analyze the alignment among visual attention, linguistic prompts, and to-be-executed actions of \textit{ReFineVLA}, showcasing its ability to focus on relevant tasks and actions. Through the latter step, we explore that \textit{ReFineVLA}-trained models exhibit a meaningful attention shift towards relevant objects, highlighting the enhanced multimodal understanding and improved generalization. Evaluated across manipulation tasks, \textit{ReFineVLA} outperforms the state-of-the-art baselines. Specifically, it achieves an average increase of $5.0\%$ success rate on SimplerEnv WidowX Robot tasks, improves by an average of $8.6\%$ in variant aggregation settings, and by $1.7\%$ in visual matching settings for SimplerEnv Google Robot tasks. The source code will be publicly available.
DPER: Efficient Parameter Estimation for Randomly Missing Data
Jun 06, 2021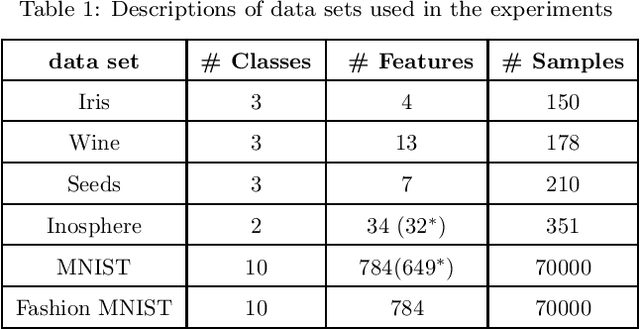
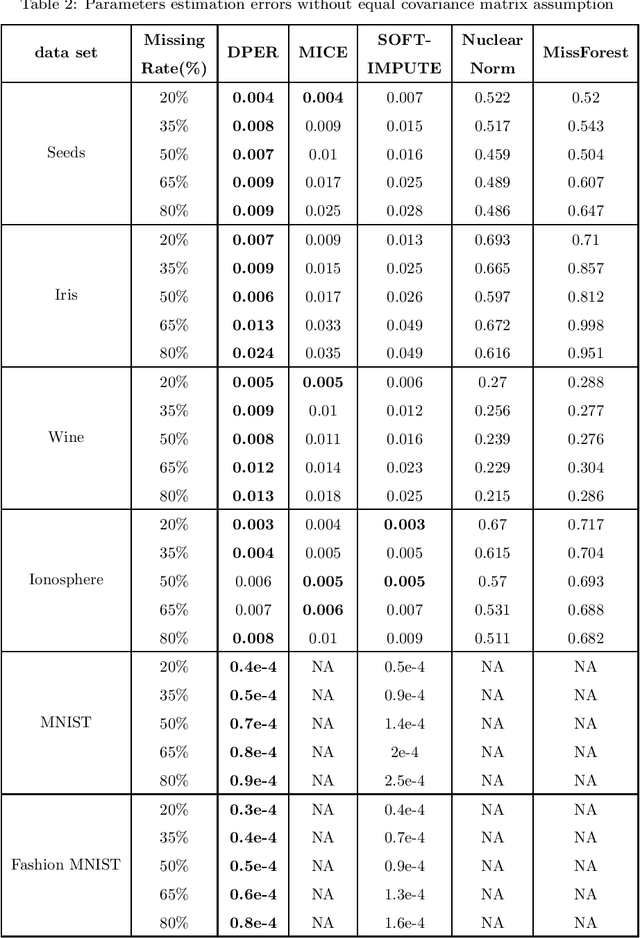
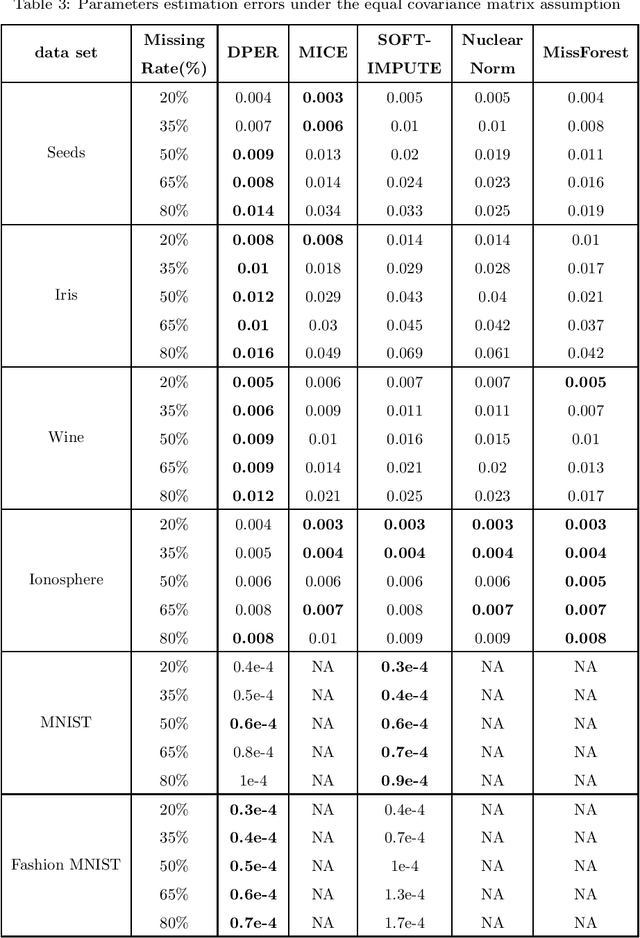
The missing data problem has been broadly studied in the last few decades and has various applications in different areas such as statistics or bioinformatics. Even though many methods have been developed to tackle this challenge, most of those are imputation techniques that require multiple iterations through the data before yielding convergence. In addition, such approaches may introduce extra biases and noises to the estimated parameters. In this work, we propose novel algorithms to find the maximum likelihood estimates (MLEs) for a one-class/multiple-class randomly missing data set under some mild assumptions. As the computation is direct without any imputation, our algorithms do not require multiple iterations through the data, thus promising to be less time-consuming than other methods while maintaining superior estimation performance. We validate these claims by empirical results on various data sets of different sizes and release all codes in a GitHub repository to contribute to the research community related to this problem.