 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Generalization through Spatial Relation Induction over Visual Primitives
May 07, 2026Domain generalization requires identifying stable representations that support reliable classification across domains. Most existing methods seek such stability through improving the training process, for example, through model selection strategies, data augmentation, or feature-alignment objectives. Although these strategies can be effective, they leave the representation learning of structural composition implicit, which may limit performance on compositional domain generalization benchmarks. In this work, we propose Primitive-Aware Relational Structure for domain gEneralization (PARSE), an image classification framework that factors visual recognition into visual primitives and their relational composition. We represent these compositions using soft binary, ternary, and quaternary predicates over primitive locations, yielding differentiable measures of spatial alignment that can be learned end-to-end. To learn primitives and relational structures jointly, we design an end-to-end architecture with three components: (1) a convolutional neural network (CNN) backbone that extracts general visual features, (2) a concept bottleneck layer that maps these features to primitive heatmaps with differentiable spatial coordinates, and (3) a structural scoring layer that evaluates candidate spatial relations among the detected primitives. We then compute class probability from the joint evidence of its class-specific relational compositions. Across CUB-DG and the DomainBed benchmark suite,PARSE improves accuracy by over 4.5 percentage points on CUB-DG and remains competitive with existing DG methods on DomainBed.
The Parallel Meaning Bank: Towards a Multilingual Corpus of Translations Annotated with Compositional Meaning Representations
Feb 13, 2017
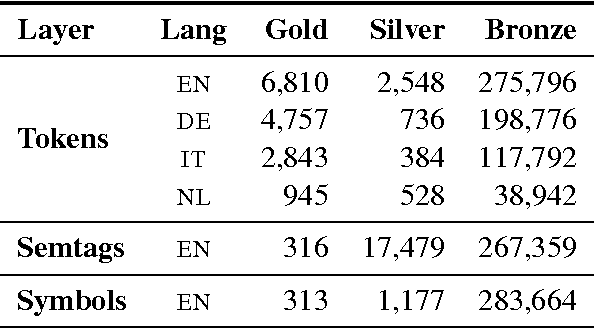
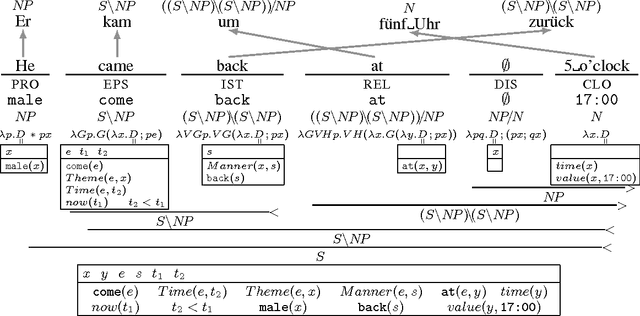
The Parallel Meaning Bank is a corpus of translations annotated with shared, formal meaning representations comprising over 11 million words divided over four languages (English, German, Italian, and Dutch). Our approach is based on cross-lingual projection: automatically produced (and manually corrected) semantic annotations for English sentences are mapped onto their word-aligned translations, assuming that the translations are meaning-preserving. The semantic annotation consists of five main steps: (i) segmentation of the text in sentences and lexical items; (ii) syntactic parsing with Combinatory Categorial Grammar; (iii) universal semantic tagging; (iv) symbolization; and (v) compositional semantic analysis based on Discourse Representation Theory. These steps are performed using statistical models trained in a semi-supervised manner. The employed annotation models are all language-neutral. Our first results are promising.