 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgefairadapt: Causal Reasoning for Fair Data Pre-processing
Oct 19, 2021
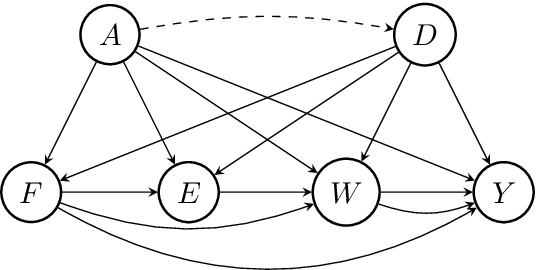
Machine learning algorithms are useful for various predictions tasks, but they can also learn how to discriminate, based on gender, race or other sensitive attributes. This realization gave rise to the field of fair machine learning, which aims to measure and mitigate such algorithmic bias. This manuscript describes the R-package fairadapt, which implements a causal inference pre-processing method. By making use of a causal graphical model and the observed data, the method can be used to address hypothetical questions of the form "What would my salary have been, had I been of a different gender/race?". Such individual level counterfactual reasoning can help eliminate discrimination and help justify fair decisions. We also discuss appropriate relaxations which assume certain causal pathways from the sensitive attribute to the outcome are not discriminatory.
Fair Data Adaptation with Quantile Preservation
Nov 15, 2019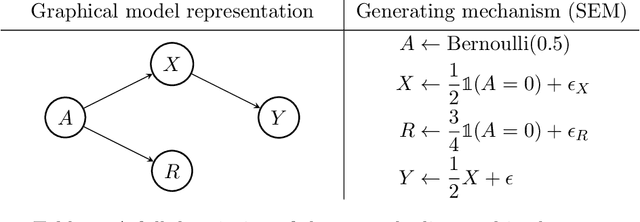
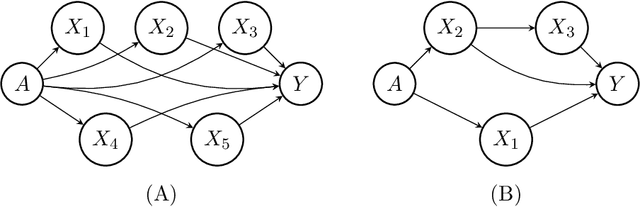
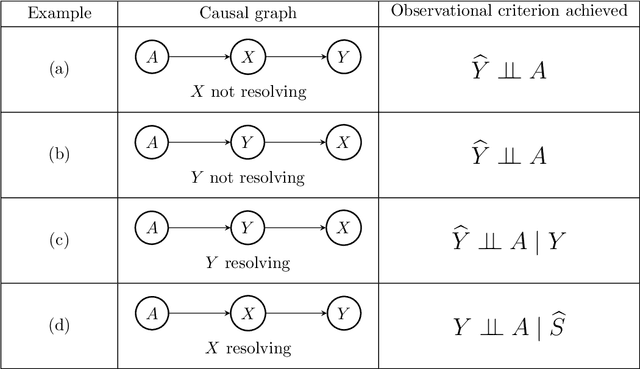
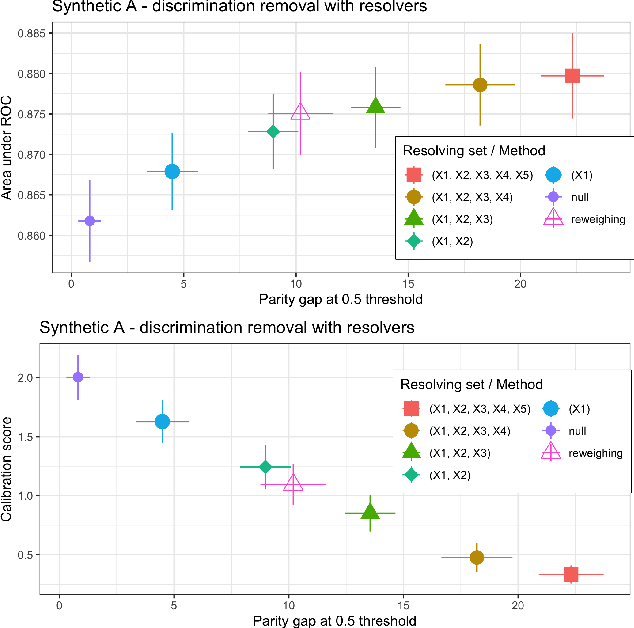
Fairness of classification and regression has received much attention recently and various, partially non-compatible, criteria have been proposed. The fairness criteria can be enforced for a given classifier or, alternatively, the data can be adapated to ensure that every classifier trained on the data will adhere to desired fairness criteria. We present a practical data adaption method based on quantile preservation in causal structural equation models. The data adaptation is based on a presumed counterfactual model for the data. While the counterfactual model itself cannot be verified experimentally, we show that certain population notions of fairness are still guaranteed even if the counterfactual model is misspecified. The precise nature of the fulfilled non-causal fairness notion (such as demographic parity, separation or sufficiency) depends on the structure of the underlying causal model and the choice of resolving variables. We describe an implementation of the proposed data adaptation procedure based on Random Forests and demonstrate its practical use on simulated and real-world data.