 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiGnature: Explicit Motion Diffusion for Stylized Semantic Gesture
Jun 14, 2026While recent advances in co-speech gesture generation have achieved impressive rhythmic synchronization, synthesizing gestures that are both semantically meaningful and faithful to a speaker's unique non-verbal style remains an open challenge. Semantic gestures, such as iconic shapes or deictic pointing, are statistically sparse, making them difficult to learn effectively within standard generative models. We present SiGnature, a framework for Stylized and Semantic Gesture generation that reconciles precise semantic control with high-fidelity style preservation. Unlike prevalent methods that rely on entangled latent representations, SiGnature operates in an explicit joint-rotation space. This design enables our core contribution, Joint Motion Integration (JMI), a training-free inference mechanism capable of injecting any external motion sequence, particularly in-the-wild semantic gestures, directly into the diffusion process. JMI automatically identifies the specific ``active joints'' conveying a semantic action and injects them into the generation, while relying on the diffusion backbone to synthesize the remaining body dynamics, including posture and flow, in accordance with the pre-learned style of the target speaker. This allows for the plug-and-play integration of arbitrary motions, including complex semantic gestures, without retraining or introducing the ``Frankenstein'' artifacts typical of cut-and-paste methods. Extensive experiments and perceptual studies demonstrate that SiGnature offers superior semantic motion control while maintaining smooth and natural co-speech gesture generation and preserving the distinct characteristics of the speaker, thereby outperforming state-of-the-art baselines.
Recurrent Neural Networks for P300-based BCI
Jan 30, 2019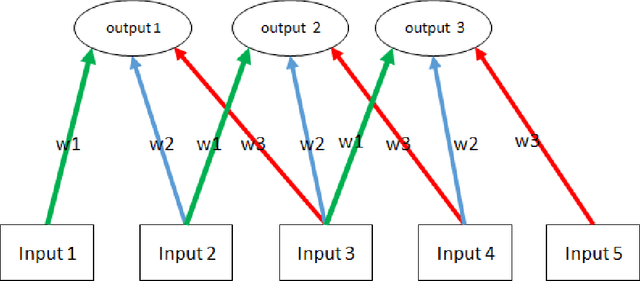
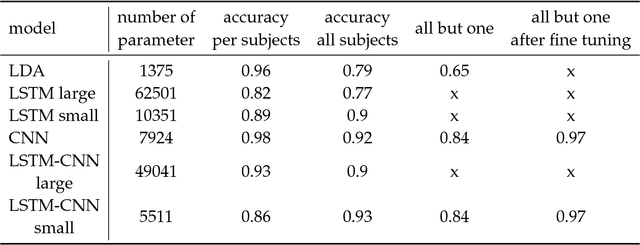
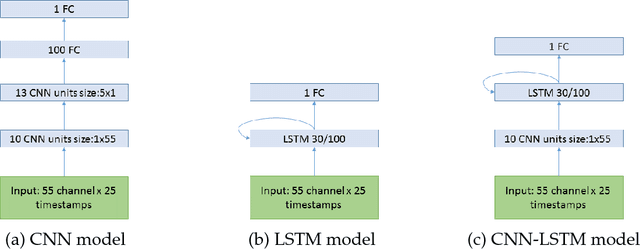
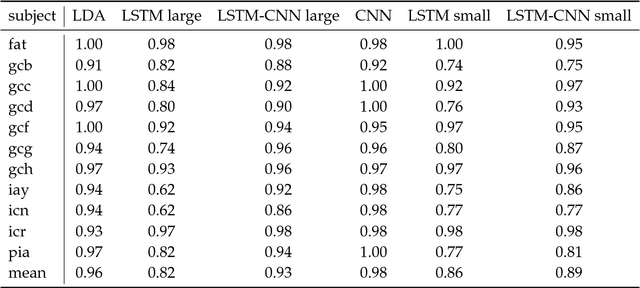
P300-based spellers are one of the main methods for EEG-based brain-computer interface, and the detection of the P300 target event with high accuracy is an important prerequisite. The rapid serial visual presentation (RSVP) protocol is of high interest because it can be used by patients who have lost control over their eyes. In this study we wish to explore the suitability of recurrent neural networks (RNNs) as a machine learning method for identifying the P300 signal in RSVP data. We systematically compare RNN with alternative methods such as linear discriminant analysis (LDA) and convolutional neural network (CNN). Our results indicate that LDA performs as well as the neural network models or better on single subject data, but a network combining CNN and RNN has advantages when transferring learning among subejcts, and is significantly more resilient to temporal noise than other methods.
A computer program for simulating time travel and a possible 'solution' for the grandfather paradox
Sep 26, 2016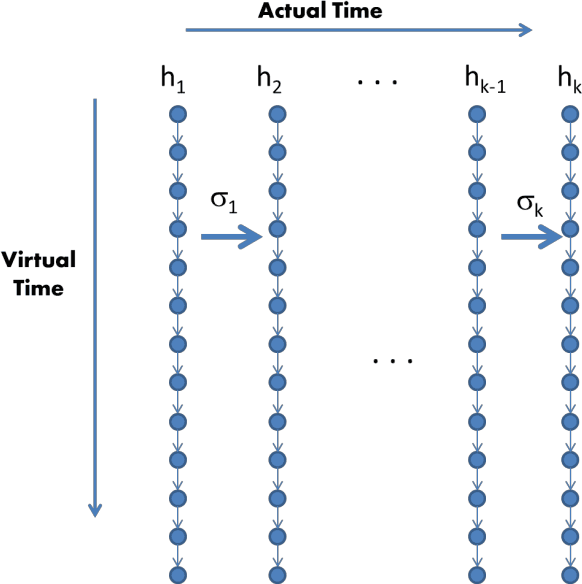
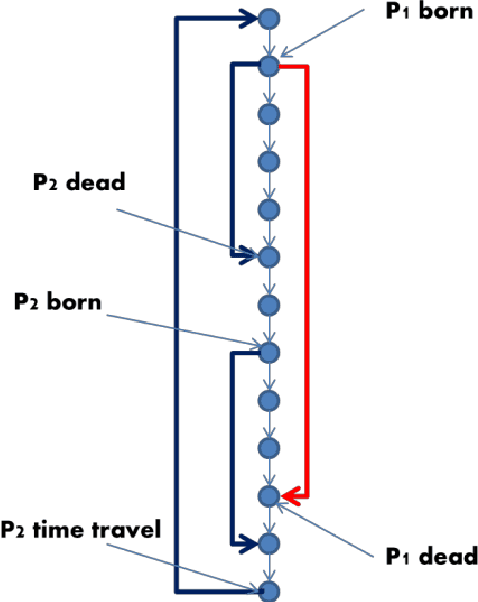
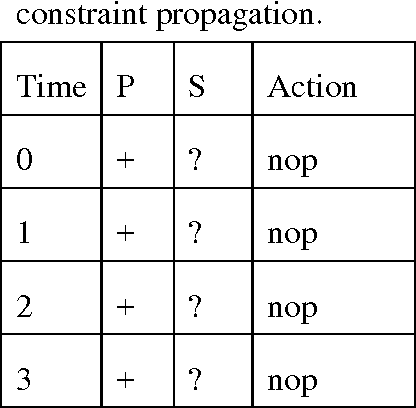

While the possibility of time travel in physics is still debated, the explosive growth of virtual-reality simulations opens up new possibilities to rigorously explore such time travel and its consequences in the digital domain. Here we provide a computational model of time travel and a computer program that allows exploring digital time travel. In order to explain our method we formalize a simplified version of the famous grandfather paradox, show how the system can allow the participant to go back in time, try to kill their ancestors before they were born, and experience the consequences. The system has even come up with scenarios that can be considered consistent "solutions" of the grandfather paradox. We discuss the conditions for digital time travel, which indicate that it has a large number of practical applications.