 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImportant Molecular Descriptors Selection Using Self Tuned Reweighted Sampling Method for Prediction of Antituberculosis Activity
Feb 21, 2014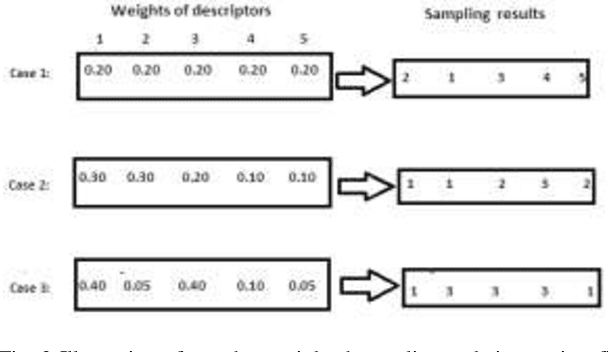
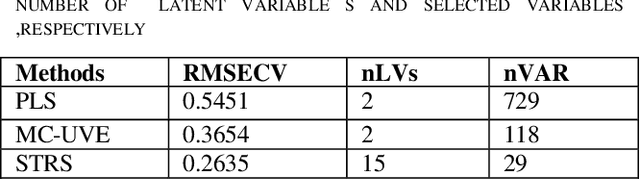
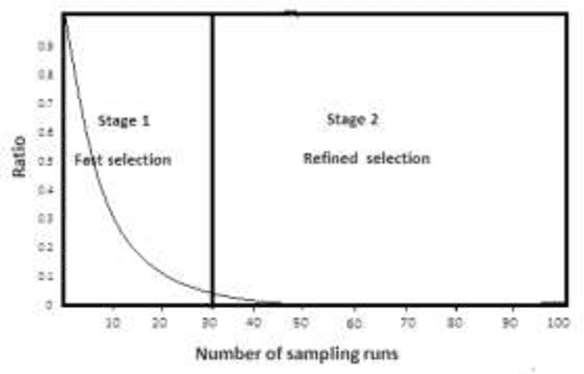
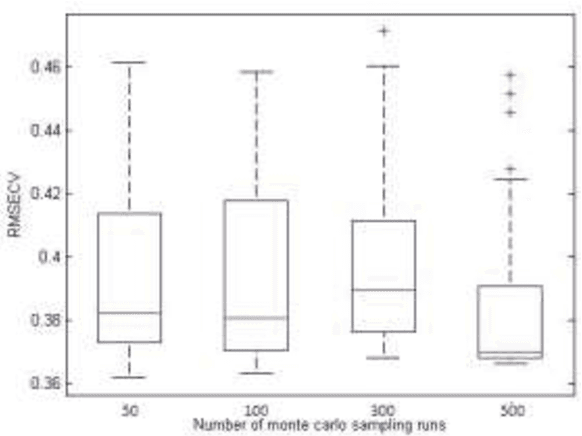
In this paper, a new descriptor selection method for selecting an optimal combination of important descriptors of sulfonamide derivatives data, named self tuned reweighted sampling (STRS), is developed. descriptors are defined as the descriptors with large absolute coefficients in a multivariate linear regression model such as partial least squares(PLS). In this study, the absolute values of regression coefficients of PLS model are used as an index for evaluating the importance of each descriptor Then, based on the importance level of each descriptor, STRS sequentially selects N subsets of descriptors from N Monte Carlo (MC) sampling runs in an iterative and competitive manner. In each sampling run, a fixed ratio (e.g. 80%) of samples is first randomly selected to establish a regresson model. Next, based on the regression coefficients, a two-step procedure including rapidly decreasing function (RDF) based enforced descriptor selection and self tuned sampling (STS) based competitive descriptor selection is adopted to select the important descriptorss. After running the loops, a number of subsets of descriptors are obtained and root mean squared error of cross validation (RMSECV) of PLS models established with subsets of descriptors is computed. The subset of descriptors with the lowest RMSECV is considered as the optimal descriptor subset. The performance of the proposed algorithm is evaluated by sulfanomide derivative dataset. The results reveal an good characteristic of STRS that it can usually locate an optimal combination of some important descriptors which are interpretable to the biologically of interest. Additionally, our study shows that better prediction is obtained by STRS when compared to full descriptor set PLS modeling, Monte Carlo uninformative variable elimination (MC-UVE).
Performance Analysis Of Neural Network Models For Oxazolines And Oxazoles Derivatives Descriptor Dataset
Dec 10, 2013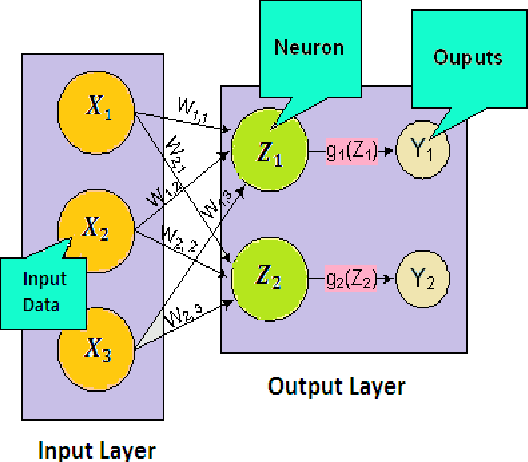
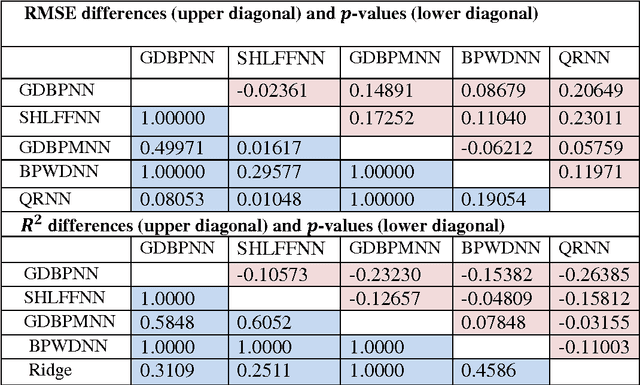
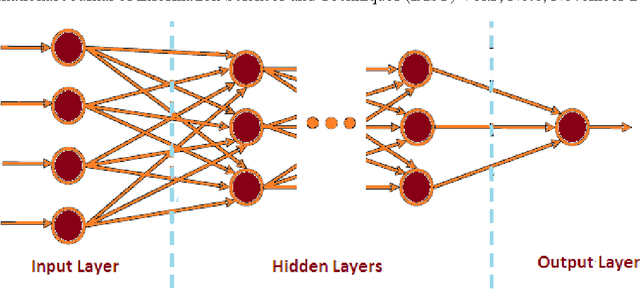
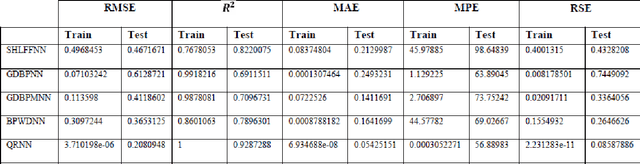
Neural networks have been used successfully to a broad range of areas such as business, data mining, drug discovery and biology. In medicine, neural networks have been applied widely in medical diagnosis, detection and evaluation of new drugs and treatment cost estimation. In addition, neural networks have begin practice in data mining strategies for the aim of prediction, knowledge discovery. This paper will present the application of neural networks for the prediction and analysis of antitubercular activity of Oxazolines and Oxazoles derivatives. This study presents techniques based on the development of Single hidden layer neural network (SHLFFNN), Gradient Descent Back propagation neural network (GDBPNN), Gradient Descent Back propagation with momentum neural network (GDBPMNN), Back propagation with Weight decay neural network (BPWDNN) and Quantile regression neural network (QRNN) of artificial neural network (ANN) models Here, we comparatively evaluate the performance of five neural network techniques. The evaluation of the efficiency of each model by ways of benchmark experiments is an accepted application. Cross-validation and resampling techniques are commonly used to derive point estimates of the performances which are compared to identify methods with good properties. Predictive accuracy was evaluated using the root mean squared error (RMSE), Coefficient determination(???), mean absolute error(MAE), mean percentage error(MPE) and relative square error(RSE). We found that all five neural network models were able to produce feasible models. QRNN model is outperforms with all statistical tests amongst other four models.
Performance Analysis Of Regularized Linear Regression Models For Oxazolines And Oxazoles Derivitive Descriptor Dataset
Dec 10, 2013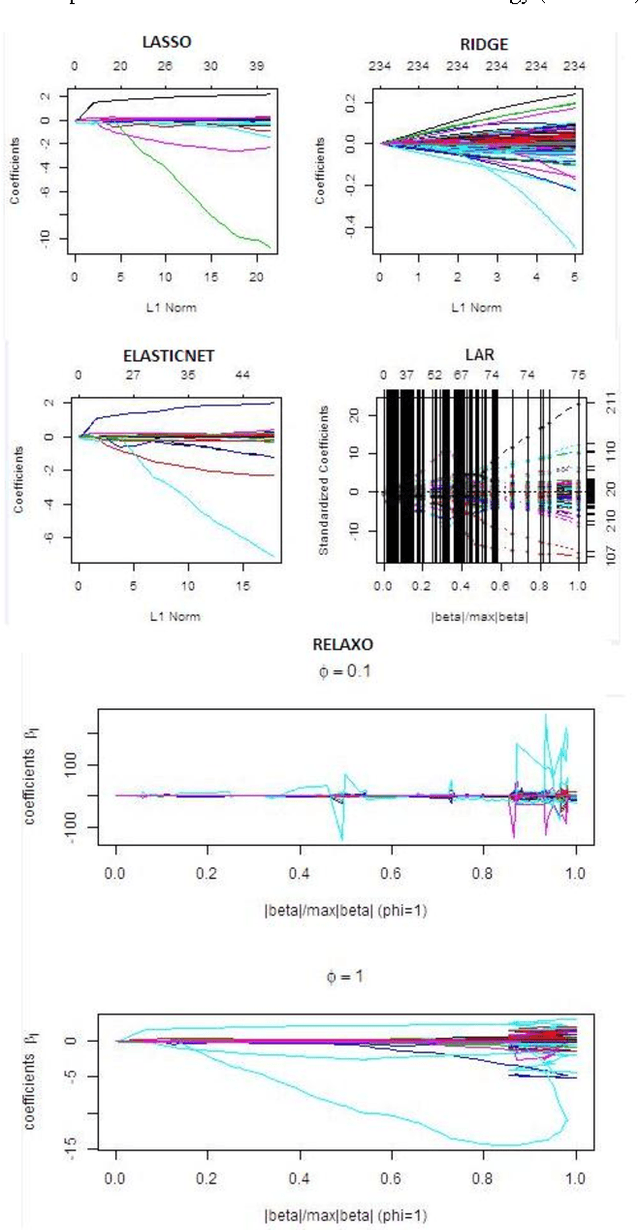
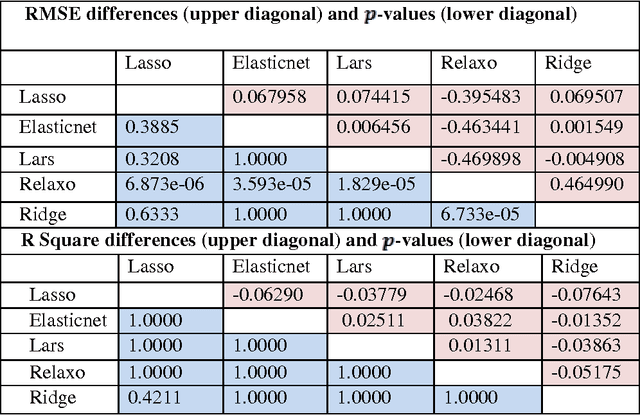
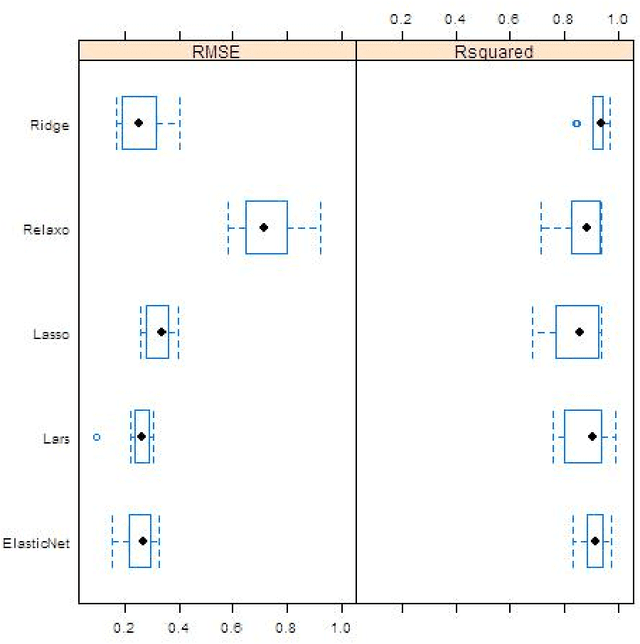
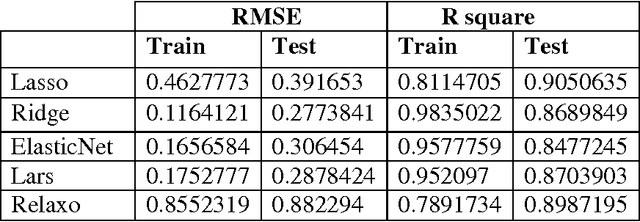
Regularized regression techniques for linear regression have been created the last few ten years to reduce the flaws of ordinary least squares regression with regard to prediction accuracy. In this paper, new methods for using regularized regression in model choice are introduced, and we distinguish the conditions in which regularized regression develops our ability to discriminate models. We applied all the five methods that use penalty-based (regularization) shrinkage to handle Oxazolines and Oxazoles derivatives descriptor dataset with far more predictors than observations. The lasso, ridge, elasticnet, lars and relaxed lasso further possess the desirable property that they simultaneously select relevant predictive descriptors and optimally estimate their effects. Here, we comparatively evaluate the performance of five regularized linear regression methods The assessment of the performance of each model by means of benchmark experiments is an established exercise. Cross-validation and resampling methods are generally used to arrive point evaluates the efficiencies which are compared to recognize methods with acceptable features. Predictive accuracy was evaluated using the root mean squared error (RMSE) and Square of usual correlation between predictors and observed mean inhibitory concentration of antitubercular activity (R square). We found that all five regularized regression models were able to produce feasible models and efficient capturing the linearity in the data. The elastic net and lars had similar accuracies as well as lasso and relaxed lasso had similar accuracies but outperformed ridge regression in terms of the RMSE and R square metrics.
A Novel Design Specification Distance Based K-Mean Clustering Performace Evluation on Engineering Materials Database
Jan 02, 2013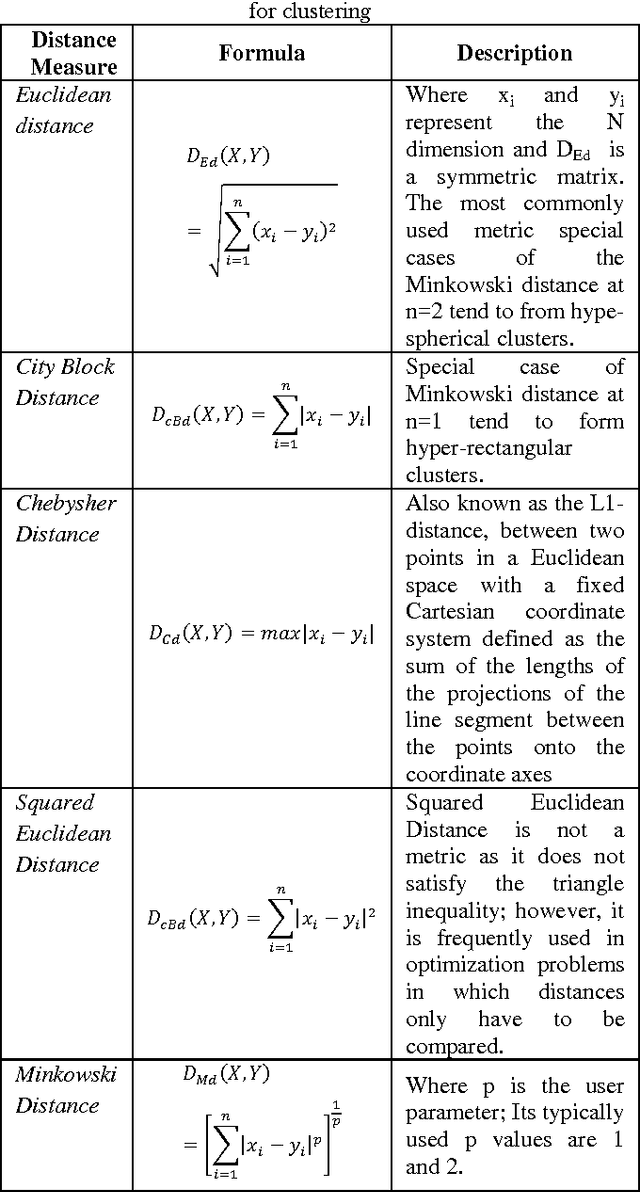
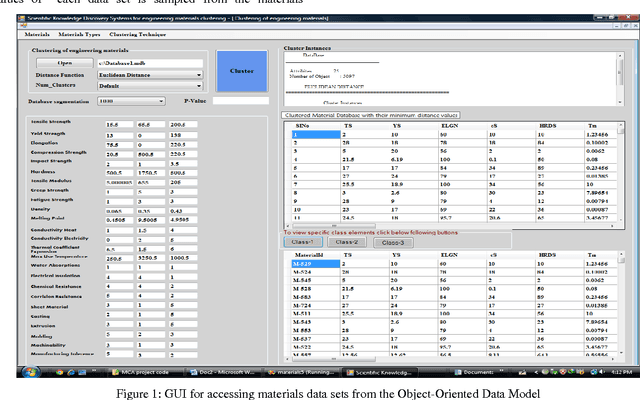
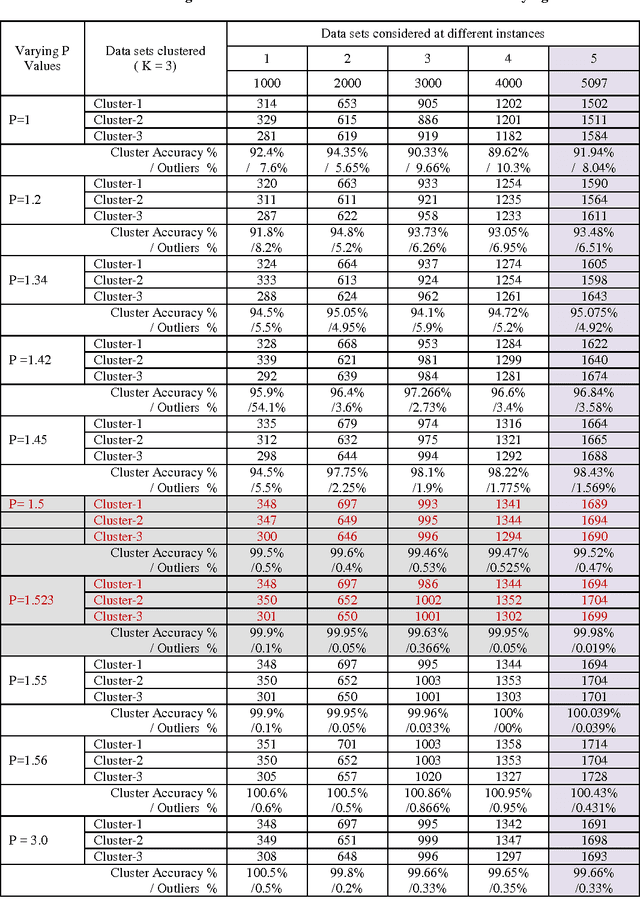
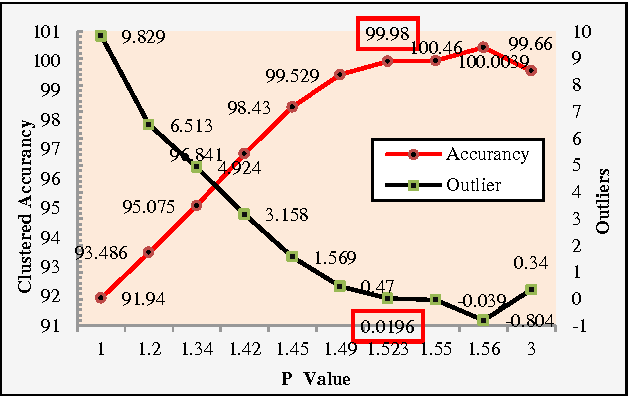
Organizing data into semantically more meaningful is one of the fundamental modes of understanding and learning. Cluster analysis is a formal study of methods for understanding and algorithm for learning. K-mean clustering algorithm is one of the most fundamental and simple clustering algorithms. When there is no prior knowledge about the distribution of data sets, K-mean is the first choice for clustering with an initial number of clusters. In this paper a novel distance metric called Design Specification (DS) distance measure function is integrated with K-mean clustering algorithm to improve cluster accuracy. The K-means algorithm with proposed distance measure maximizes the cluster accuracy to 99.98% at P = 1.525, which is determined through the iterative procedure. The performance of Design Specification (DS) distance measure function with K - mean algorithm is compared with the performances of other standard distance functions such as Euclidian, squared Euclidean, City Block, and Chebshew similarity measures deployed with K-mean algorithm.The proposed method is evaluated on the engineering materials database. The experiments on cluster analysis and the outlier profiling show that these is an excellent improvement in the performance of the proposed method.
Similarity Measuring Approuch for Engineering Materials Selection
Jan 02, 2013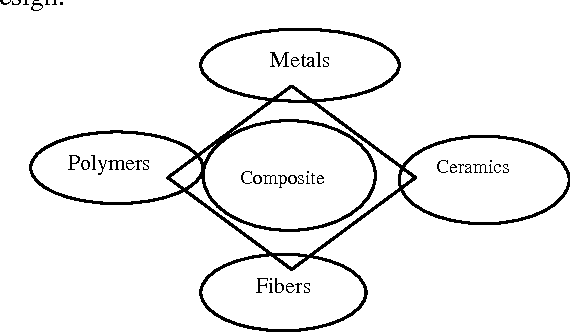

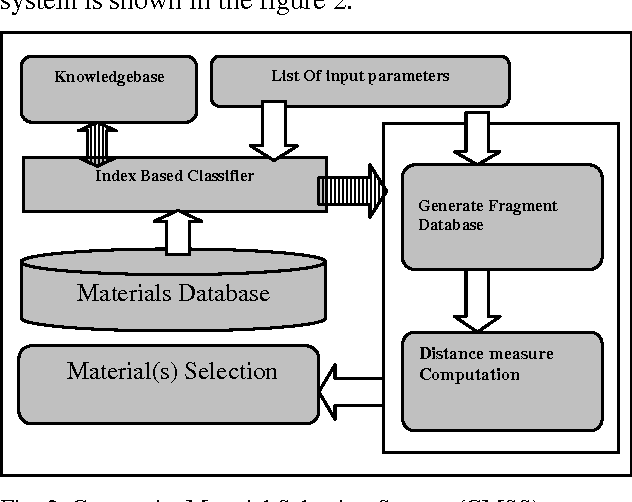
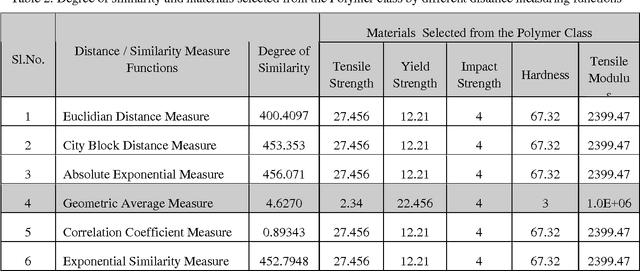
Advanced engineering materials design involves the exploration of massive multidimensional feature spaces, the correlation of materials properties and the processing parameters derived from disparate sources. The search for alternative materials or processing property strategies, whether through analytical, experimental or simulation approaches, has been a slow and arduous task, punctuated by infrequent and often expected discoveries. A few systematic efforts have been made to analyze the trends in data as a basis for classifications and predictions. This is particularly due to the lack of large amounts of organized data and more importantly the challenging of shifting through them in a timely and efficient manner. The application of recent advances in Data Mining on materials informatics is the state of art of computational and experimental approaches for materials discovery. In this paper similarity based engineering materials selection model is proposed and implemented to select engineering materials based on the composite materials constraints. The result reviewed from this model is sustainable for effective decision making in advanced engineering materials design applications.
Knowledge Discovery System For Fiber Reinforced Polymer Matrix Composite Laminate
Jan 02, 2013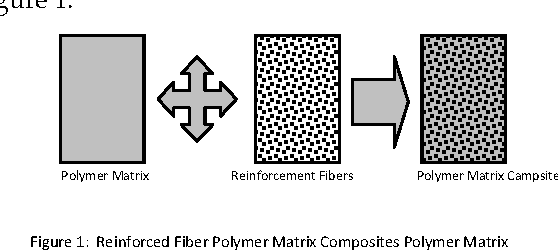
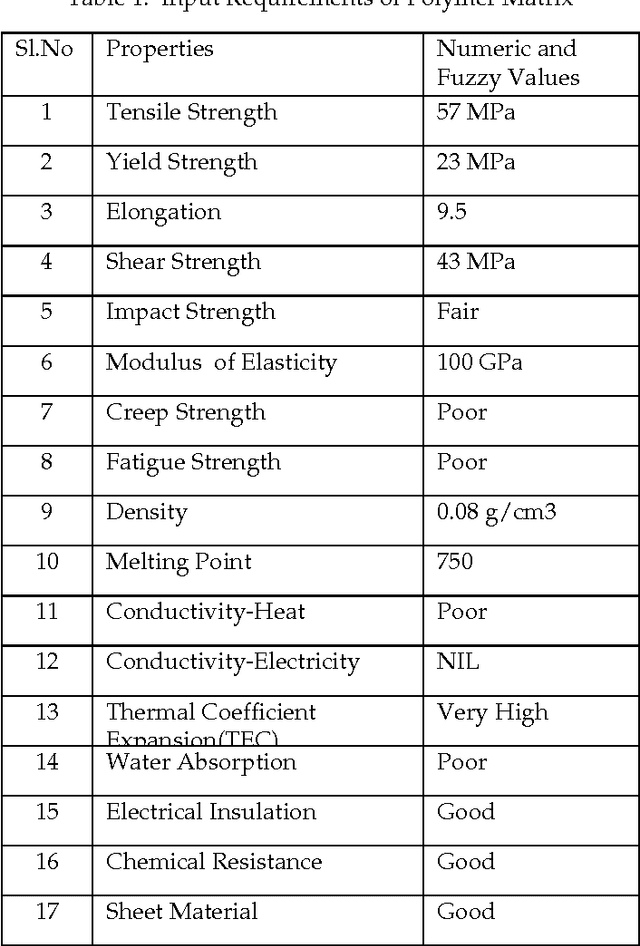
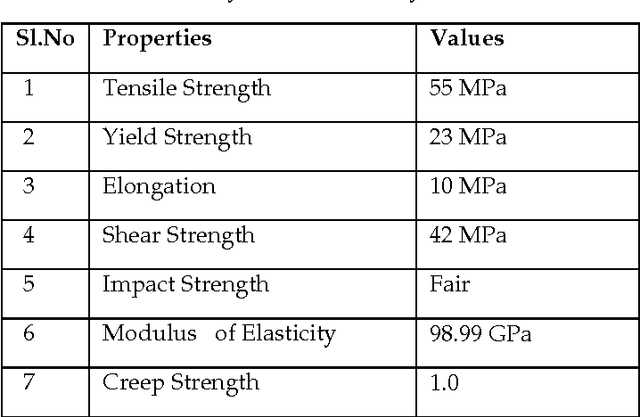
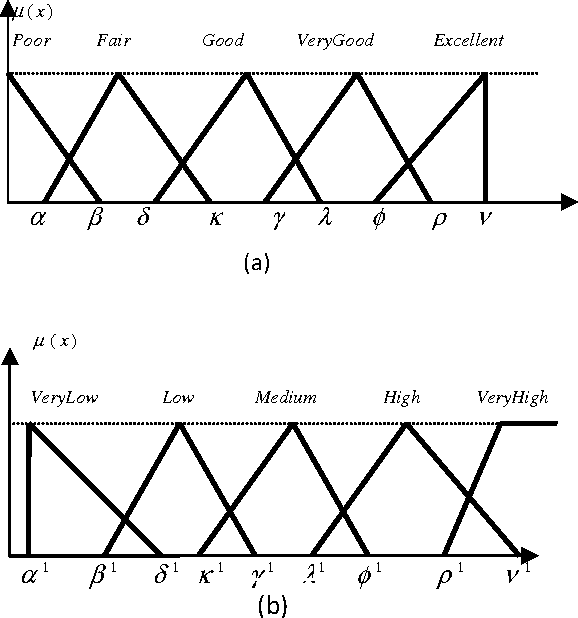
In this paper Knowledge Discovery System (KDS) is proposed and implemented for the extraction of knowledge-mean stiffness of a polymer composite material in which when fibers are placed at different orientations. Cosine amplitude method is implemented for retrieving compatible polymer matrix and reinforcement fiber which is coming under predicted fiber class, from the polymer and reinforcement database respectively, based on the design requirements. Fuzzy classification rules to classify fibers into short, medium and long fiber classes are derived based on the fiber length and the computed or derive critical length of fiber. Longitudinal and Transverse module of Polymer Matrix Composite consisting of seven layers with different fiber volume fractions and different fibers orientations at 0,15,30,45,60,75 and 90 degrees are analyzed through Rule-of Mixture material design model. The analysis results are represented in different graphical steps and have been measured with statistical parameters. This data mining application implemented here has focused the mechanical problems of material design and analysis. Therefore, this system is an expert decision support system for optimizing the materials performance for designing light-weight and strong, and cost effective polymer composite materials.