 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGM-VAE: Representation Learning with VAE on Gaussian Manifold
Sep 30, 2022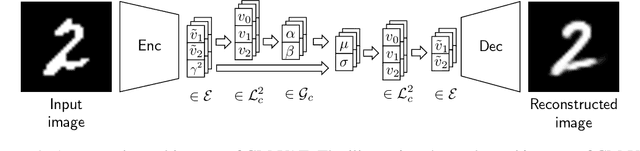

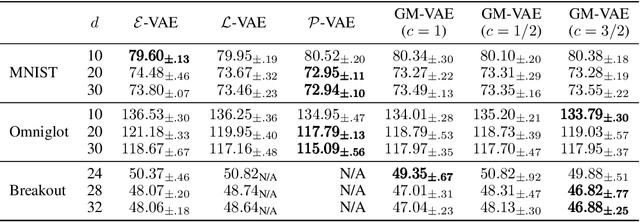
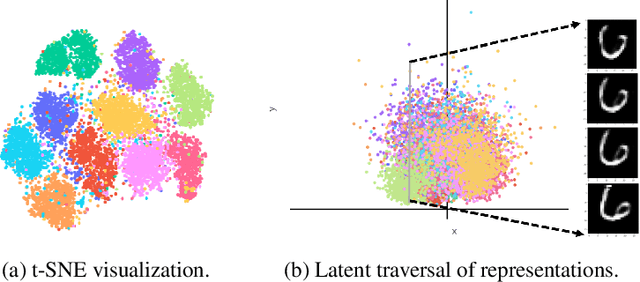
We propose a Gaussian manifold variational auto-encoder (GM-VAE) whose latent space consists of a set of diagonal Gaussian distributions. It is known that the set of the diagonal Gaussian distributions with the Fisher information metric forms a product hyperbolic space, which we call a Gaussian manifold. To learn the VAE endowed with the Gaussian manifold, we first propose a pseudo Gaussian manifold normal distribution based on the Kullback-Leibler divergence, a local approximation of the squared Fisher-Rao distance, to define a density over the latent space. With the newly proposed distribution, we introduce geometric transformations at the last and the first of the encoder and the decoder of VAE, respectively to help the transition between the Euclidean and Gaussian manifolds. Through the empirical experiments, we show competitive generalization performance of GM-VAE against other variants of hyperbolic- and Euclidean-VAEs. Our model achieves strong numerical stability, which is a common limitation reported with previous hyperbolic-VAEs.
Restructuring Graph for Higher Homophily via Learnable Spectral Clustering
Jun 06, 2022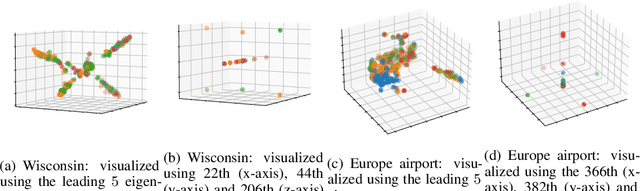
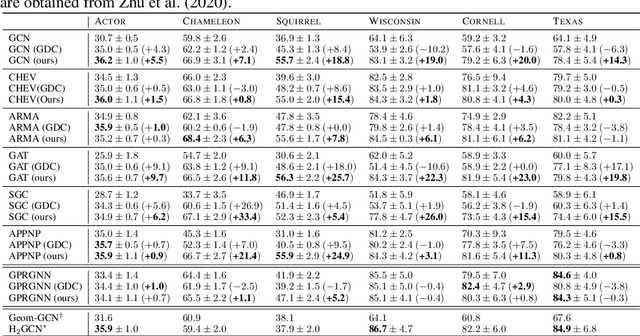
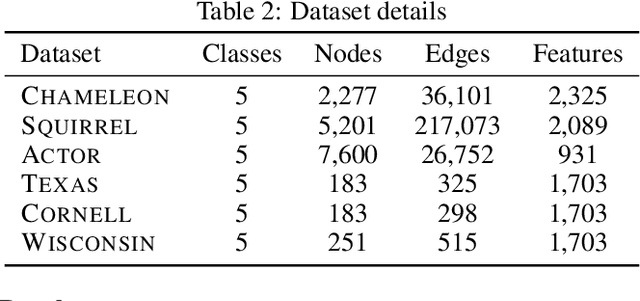
While a growing body of literature has been studying new Graph Neural Networks (GNNs) that work on both homophilic and heterophilic graphs, little work has been done on adapting classical GNNs to less-homophilic graphs. Although lacking the ability to work with less-homophilic graphs, classical GNNs still stand out in some properties such as efficiency, simplicity and explainability. We propose a novel graph restructuring method to maximize the benefit of prevalent GNNs with the homophilic assumption. Our contribution is threefold: a) learning the weight of pseudo-eigenvectors for an adaptive spectral clustering that aligns well with known node labels, b) proposing a new homophilic metric that measures how two nodes with the same label are likely to be connected, and c) reconstructing the adjacency matrix based on the result of adaptive spectral clustering to maximize the homophilic scores. The experimental results show that our graph restructuring method can significantly boost the performance of six classical GNNs by an average of 25% on less-homophilic graphs. The boosted performance is comparable to state-of-the-art methods.
Strengthening Skeletal Action Recognizers via Leveraging Temporal Patterns
Jun 04, 2022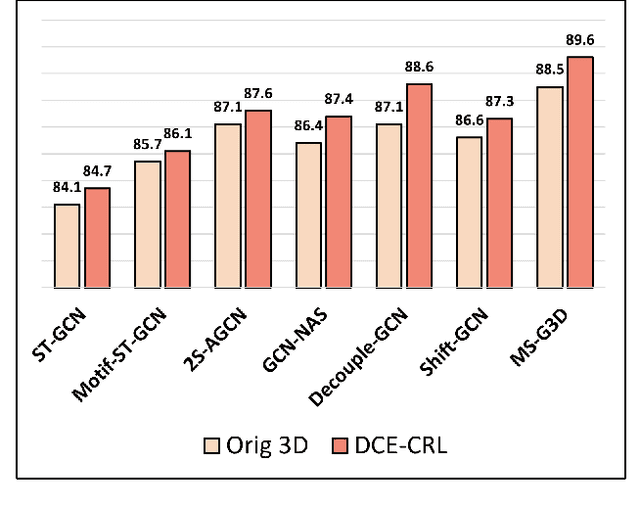
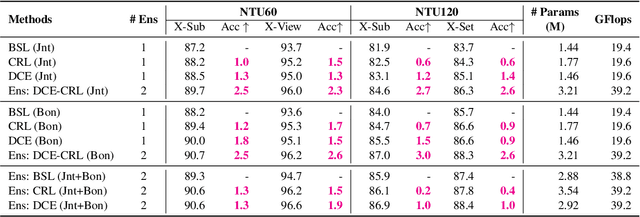
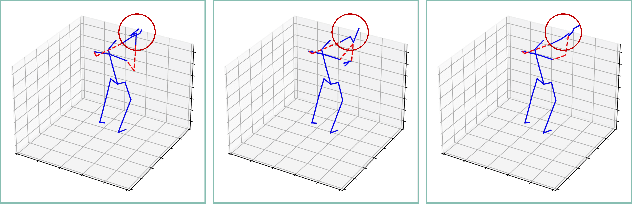
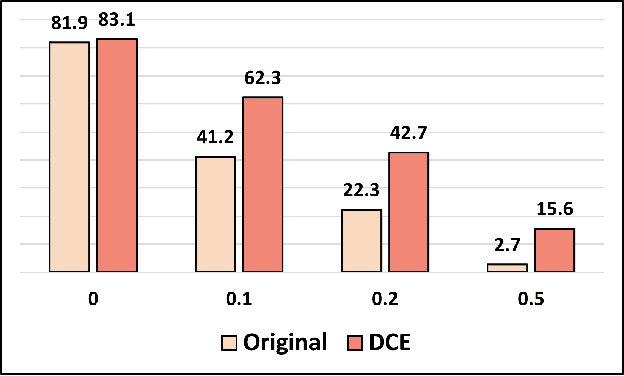
Skeleton sequences are compact and lightweight. Numerous skeleton-based action recognizers have been proposed to classify human behaviors. In this work, we aim to incorporate components that are compatible with existing models and further improve their accuracy. To this end, we design two temporal accessories: discrete cosine encoding (DCE) and chronological loss (CRL). DCE facilitates models to analyze motion patterns from the frequency domain and meanwhile alleviates the influence of signal noise. CRL guides networks to explicitly capture the sequence's chronological order. These two components consistently endow many recently-proposed action recognizers with accuracy boosts, achieving new state-of-the-art (SOTA) accuracy on two large benchmark datasets (NTU60 and NTU120).
Few-Shot Unlearning by Model Inversion
May 31, 2022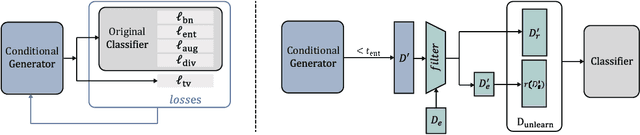

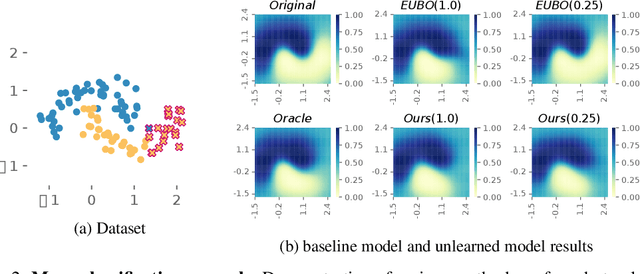
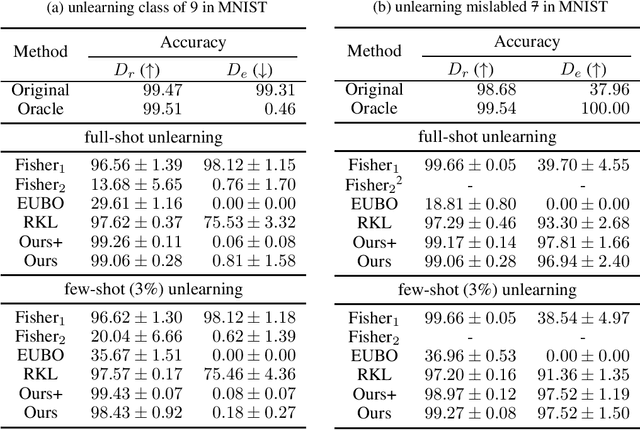
We consider the problem of machine unlearning to erase a target dataset, which causes an unwanted behavior, from the trained model when the training dataset is not given. Previous works have assumed that the target dataset indicates all the training data imposing the unwanted behavior. However, it is often infeasible to obtain such a complete indication. We hence address a practical scenario of unlearning provided a few samples of target data, so-called few-shot unlearning. To this end, we devise a straightforward framework, including a new model inversion technique to retrieve the training data from the model, followed by filtering out samples similar to the target samples and then relearning. We demonstrate that our method using only a subset of target data can outperform the state-of-the-art methods with a full indication of target data.
MetaSSD: Meta-Learned Self-Supervised Detection
May 30, 2022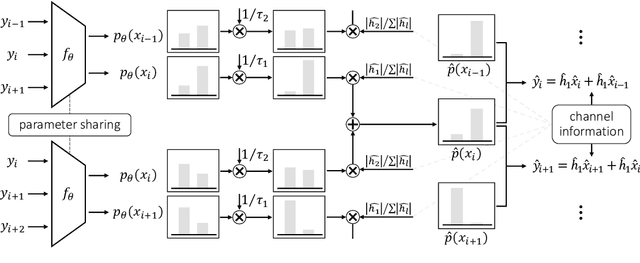
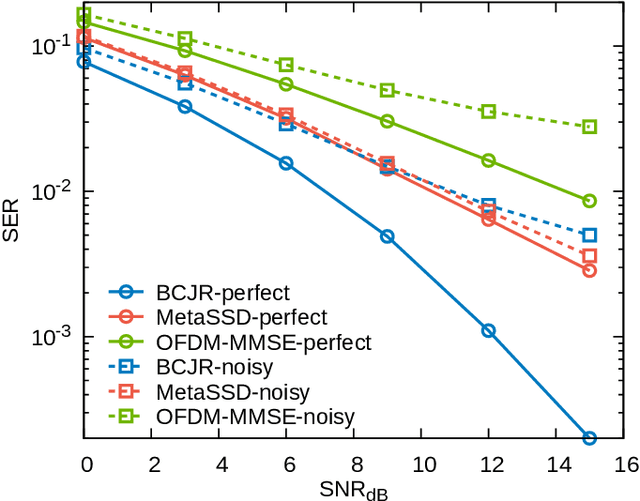
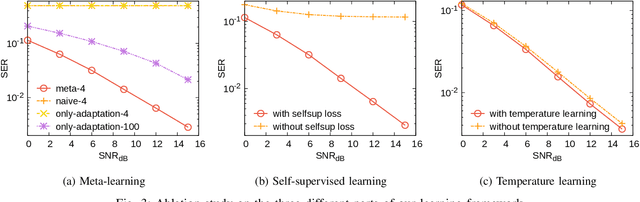
Deep learning-based symbol detector gains increasing attention due to the simple algorithm design than the traditional model-based algorithms such as Viterbi and BCJR. The supervised learning framework is often employed to predict the input symbols, where training symbols are used to train the model. There are two major limitations in the supervised approaches: a) a model needs to be retrained from scratch when new train symbols come to adapt to a new channel status, and b) the length of the training symbols needs to be longer than a certain threshold to make the model generalize well on unseen symbols. To overcome these challenges, we propose a meta-learning-based self-supervised symbol detector named MetaSSD. Our contribution is two-fold: a) meta-learning helps the model adapt to a new channel environment based on experience with various meta-training environments, and b) self-supervised learning helps the model to use relatively less supervision than the previously suggested learning-based detectors. In experiments, MetaSSD outperforms OFDM-MMSE with noisy channel information and shows comparable results with BCJR. Further ablation studies show the necessity of each component in our framework.
A Rotated Hyperbolic Wrapped Normal Distribution for Hierarchical Representation Learning
May 25, 2022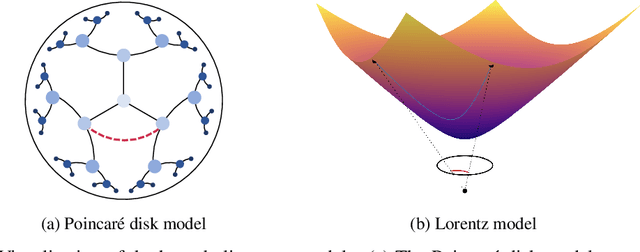
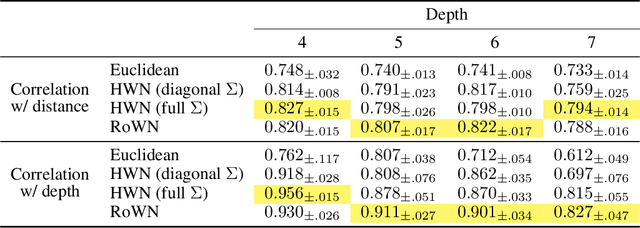
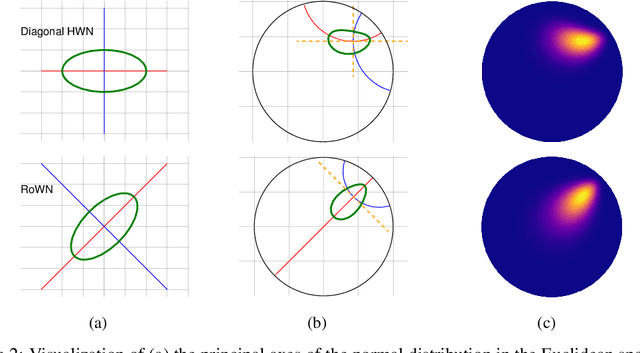
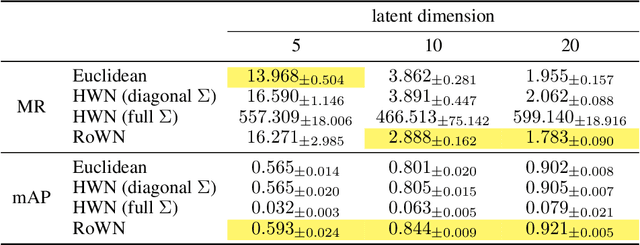
We present a rotated hyperbolic wrapped normal distribution (RoWN), a simple yet effective alteration of a hyperbolic wrapped normal distribution (HWN). The HWN expands the domain of probabilistic modeling from Euclidean to hyperbolic space, where a tree can be embedded with arbitrary low distortion in theory. In this work, we analyze the geometric properties of the diagonal HWN, a standard choice of distribution in probabilistic modeling. The analysis shows that the distribution is inappropriate to represent the data points at the same hierarchy level through their angular distance with the same norm in the Poincar\'e disk model. We then empirically verify the presence of limitations of HWN, and show how RoWN, the newly proposed distribution, can alleviate the limitations on various hierarchical datasets, including noisy synthetic binary tree, WordNet, and Atari 2600 Breakout.
ANUBIS: Skeleton Action Recognition Dataset, Review, and Benchmark
May 08, 2022
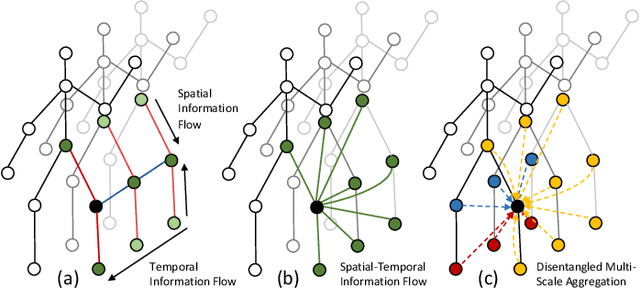
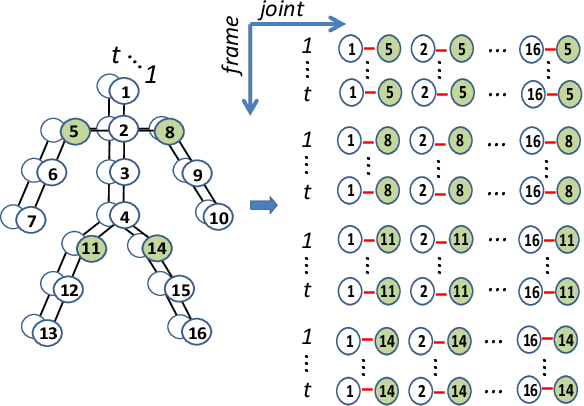
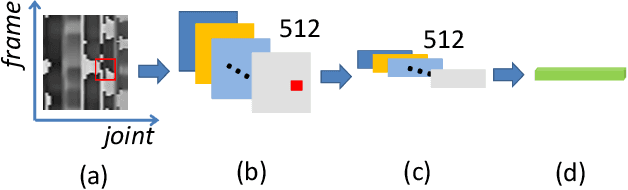
Skeleton-based action recognition, as a subarea of action recognition, is swiftly accumulating attention and popularity. The task is to recognize actions performed by human articulation points. Compared with other data modalities, 3D human skeleton representations have extensive unique desirable characteristics, including succinctness, robustness, racial-impartiality, and many more. We aim to provide a roadmap for new and existing researchers a on the landscapes of skeleton-based action recognition for new and existing researchers. To this end, we present a review in the form of a taxonomy on existing works of skeleton-based action recognition. We partition them into four major categories: (1) datasets; (2) extracting spatial features; (3) capturing temporal patterns; (4) improving signal quality. For each method, we provide concise yet informatively-sufficient descriptions. To promote more fair and comprehensive evaluation on existing approaches of skeleton-based action recognition, we collect ANUBIS, a large-scale human skeleton dataset. Compared with previously collected dataset, ANUBIS are advantageous in the following four aspects: (1) employing more recently released sensors; (2) containing novel back view; (3) encouraging high enthusiasm of subjects; (4) including actions of the COVID pandemic era. Using ANUBIS, we comparably benchmark performance of current skeleton-based action recognizers. At the end of this paper, we outlook future development of skeleton-based action recognition by listing several new technical problems. We believe they are valuable to solve in order to commercialize skeleton-based action recognition in the near future. The dataset of ANUBIS is available at: http://hcc-workshop.anu.edu.au/webs/anu101/home.
Anonymization for Skeleton Action Recognition
Nov 30, 2021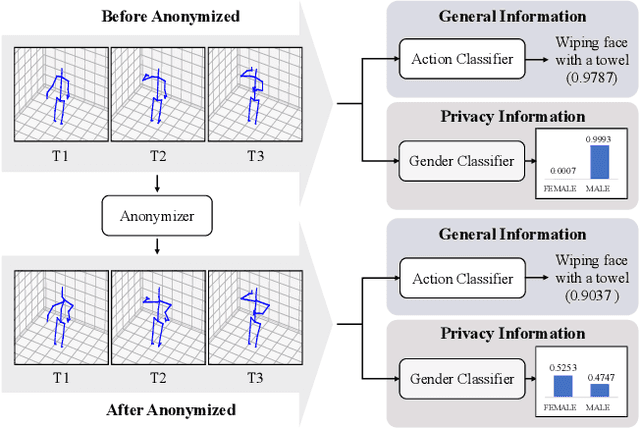
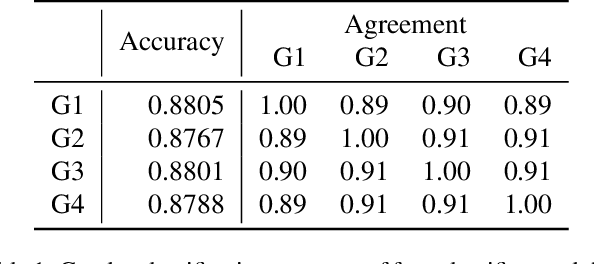
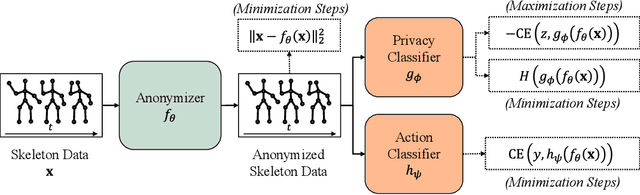
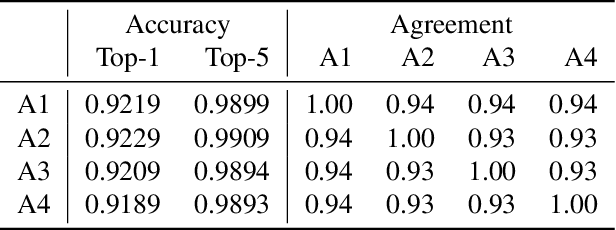
The skeleton-based action recognition attracts practitioners and researchers due to the lightweight, compact nature of datasets. Compared with RGB-video-based action recognition, skeleton-based action recognition is a safer way to protect the privacy of subjects while having competitive recognition performance. However, due to the improvements of skeleton estimation algorithms as well as motion- and depth-sensors, more details of motion characteristics can be preserved in the skeleton dataset, leading to a potential privacy leakage from the dataset. To investigate the potential privacy leakage from the skeleton datasets, we first train a classifier to categorize sensitive private information from a trajectory of joints. Experiments show the model trained to classify gender can predict with 88% accuracy and re-identify a person with 82% accuracy. We propose two variants of anonymization algorithms to protect the potential privacy leakage from the skeleton dataset. Experimental results show that the anonymized dataset can reduce the risk of privacy leakage while having marginal effects on the action recognition performance.
Robust Deep Learning from Crowds with Belief Propagation
Nov 01, 2021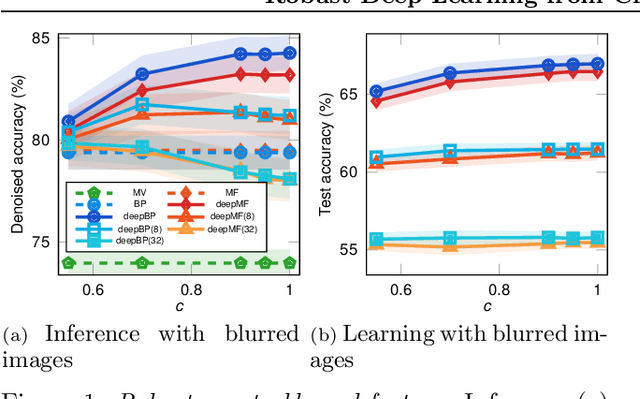

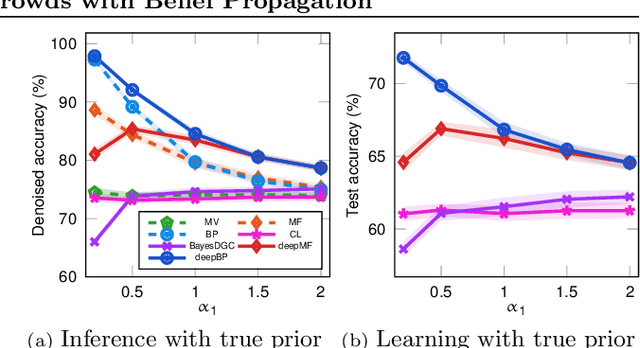
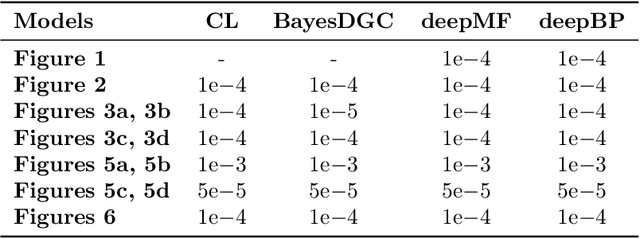
Crowdsourcing systems enable us to collect noisy labels from crowd workers. A graphical model representing local dependencies between workers and tasks provides a principled way of reasoning over the true labels from the noisy answers. However, one needs a predictive model working on unseen data directly from crowdsourced datasets instead of the true labels in many cases. To infer true labels and learn a predictive model simultaneously, we propose a new data-generating process, where a neural network generates the true labels from task features. We devise an EM framework alternating variational inference and deep learning to infer the true labels and to update the neural network, respectively. Experimental results with synthetic and real datasets show a belief-propagation-based EM algorithm is robust to i) corruption in task features, ii) multi-modal or mismatched worker prior, and iii) few spammers submitting noises to many tasks.
Informative Class Activation Maps
Jun 19, 2021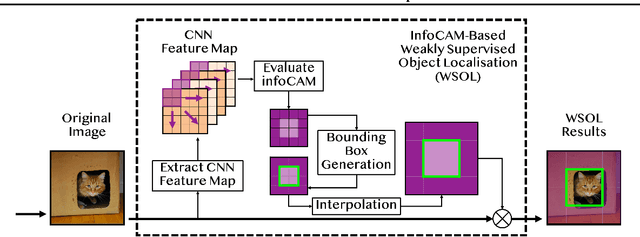
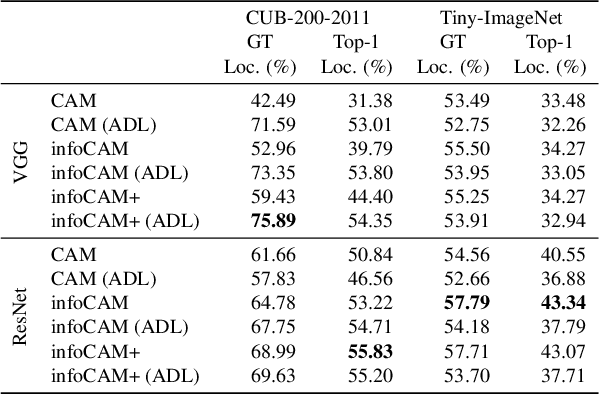

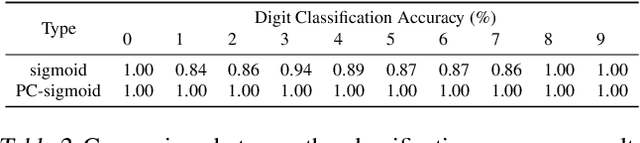
We study how to evaluate the quantitative information content of a region within an image for a particular label. To this end, we bridge class activation maps with information theory. We develop an informative class activation map (infoCAM). Given a classification task, infoCAM depict how to accumulate information of partial regions to that of the entire image toward a label. Thus, we can utilise infoCAM to locate the most informative features for a label. When applied to an image classification task, infoCAM performs better than the traditional classification map in the weakly supervised object localisation task. We achieve state-of-the-art results on Tiny-ImageNet.