 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtecting Privacy of Users in Brain-Computer Interface Applications
Jul 02, 2019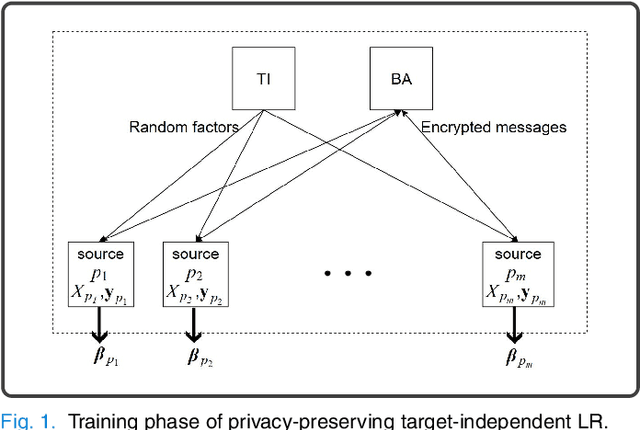
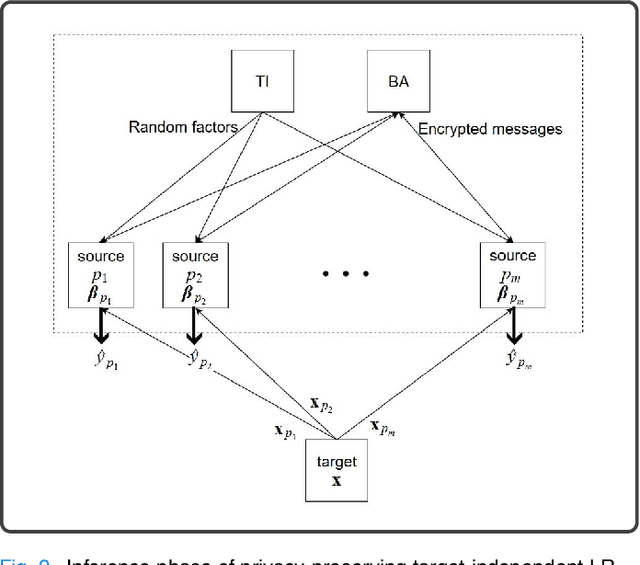
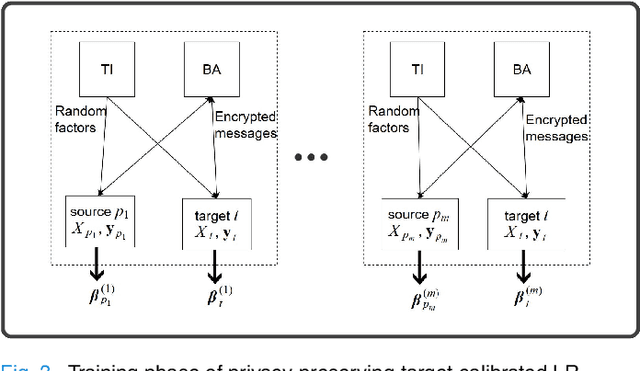
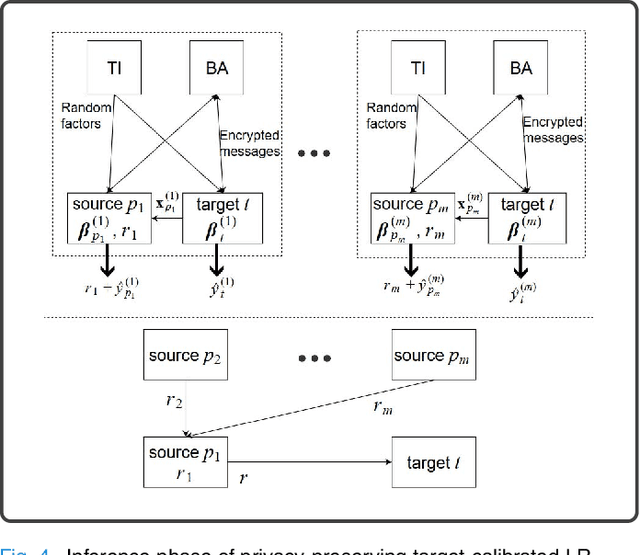
Machine learning (ML) is revolutionizing research and industry. Many ML applications rely on the use of large amounts of personal data for training and inference. Among the most intimate exploited data sources is electroencephalogram (EEG) data, a kind of data that is so rich with information that application developers can easily gain knowledge beyond the professed scope from unprotected EEG signals, including passwords, ATM PINs, and other intimate data. The challenge we address is how to engage in meaningful ML with EEG data while protecting the privacy of users. Hence, we propose cryptographic protocols based on Secure Multiparty Computation (SMC) to perform linear regression over EEG signals from many users in a fully privacy-preserving (PP) fashion, i.e.~such that each individual's EEG signals are not revealed to anyone else. To illustrate the potential of our secure framework, we show how it allows estimating the drowsiness of drivers from their EEG signals as would be possible in the unencrypted case, and at a very reasonable computational cost. Our solution is the first application of commodity-based SMC to EEG data, as well as the largest documented experiment of secret sharing based SMC in general, namely with 15 players involved in all the computations.
Patch Learning
Jun 01, 2019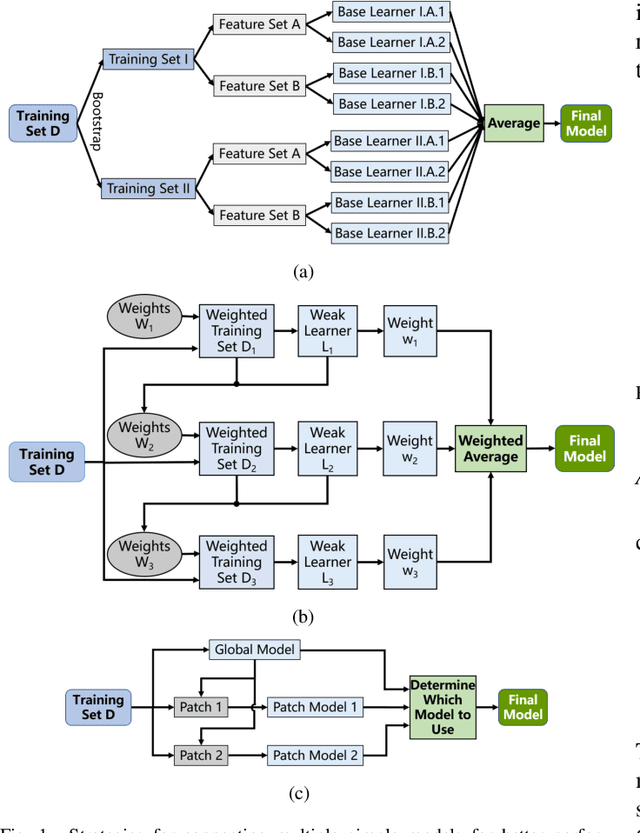

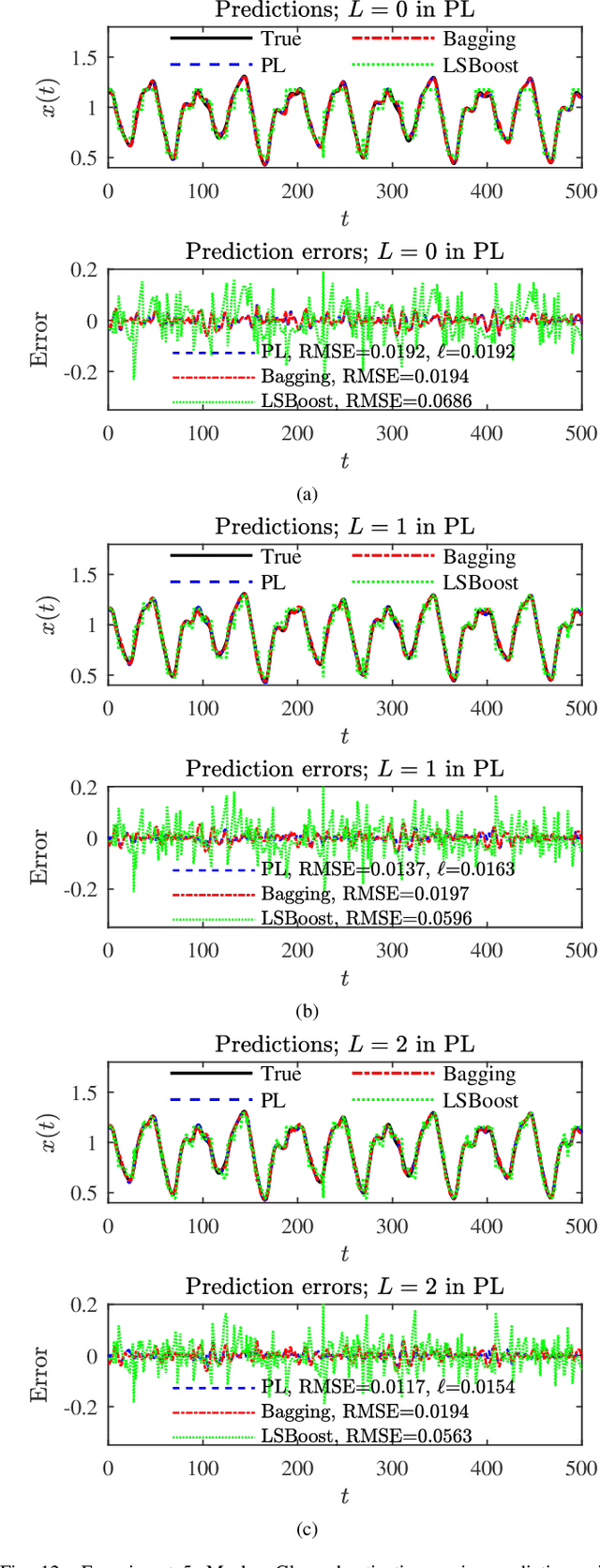
There have been different strategies to improve the performance of a machine learning model, e.g., increasing the depth, width, and/or nonlinearity of the model, and using ensemble learning to aggregate multiple base/weak learners in parallel or in series. This paper proposes a novel strategy called patch learning (PL) for this problem. It consists of three steps: 1) train an initial global model using all training data; 2) identify from the initial global model the patches which contribute the most to the learning error, and train a (local) patch model for each such patch; and, 3) update the global model using training data that do not fall into any patch. To use a PL model, we first determine if the input falls into any patch. If yes, then the corresponding patch model is used to compute the output. Otherwise, the global model is used. We explain in detail how PL can be implemented using fuzzy systems. Five regression problems on 1D/2D/3D curve fitting, nonlinear system identification, and chaotic time-series prediction, verified its effectiveness. To our knowledge, the PL idea has not appeared in the literature before, and it opens up a promising new line of research in machine learning.
On the Vulnerability of CNN Classifiers in EEG-Based BCIs
Mar 31, 2019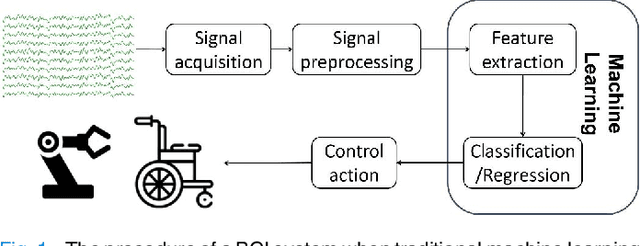
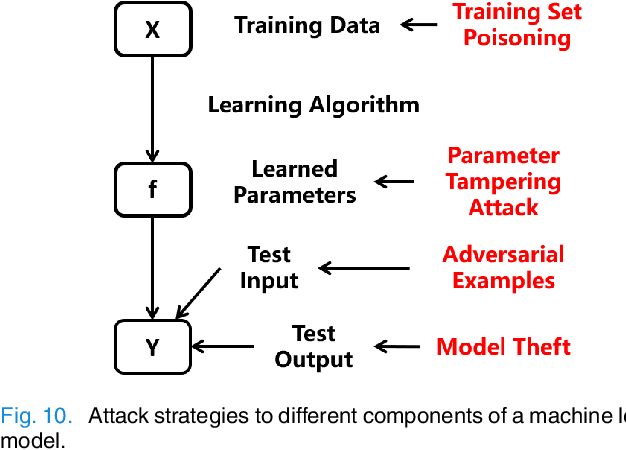
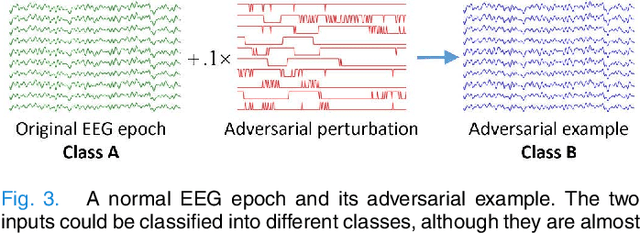
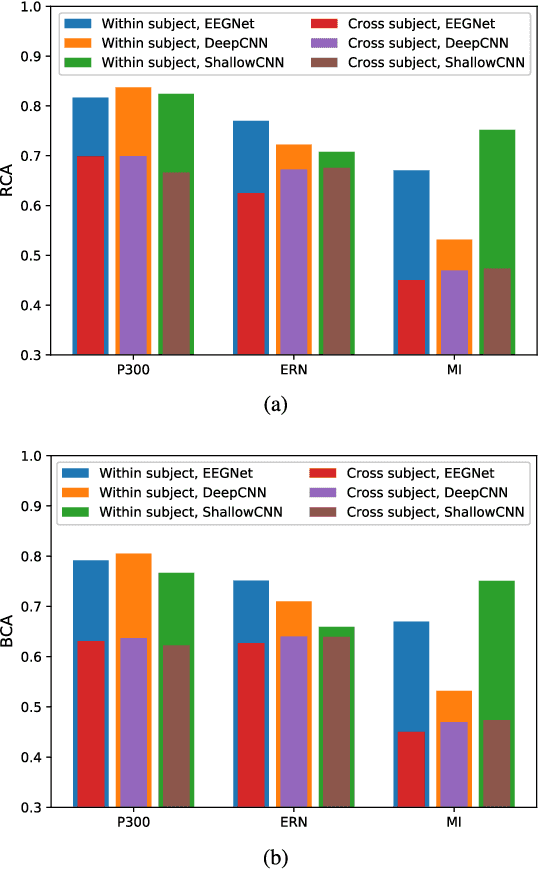
Deep learning has been successfully used in numerous applications because of its outstanding performance and the ability to avoid manual feature engineering. One such application is electroencephalogram (EEG) based brain-computer interface (BCI), where multiple convolutional neural network (CNN) models have been proposed for EEG classification. However, it has been found that deep learning models can be easily fooled with adversarial examples, which are normal examples with small deliberate perturbations. This paper proposes an unsupervised fast gradient sign method (UFGSM) to attack three popular CNN classifiers in BCIs, and demonstrates its effectiveness. We also verify the transferability of adversarial examples in BCIs, which means we can perform attacks even without knowing the architecture and parameters of the target models, or the datasets they were trained on. To our knowledge, this is the first study on the vulnerability of CNN classifiers in EEG-based BCIs, and hopefully will trigger more attention on the security of BCI systems.
Optimize TSK Fuzzy Systems for Big Data Regression Problems: Mini-Batch Gradient Descent with Regularization, DropRule and AdaBound
Mar 26, 2019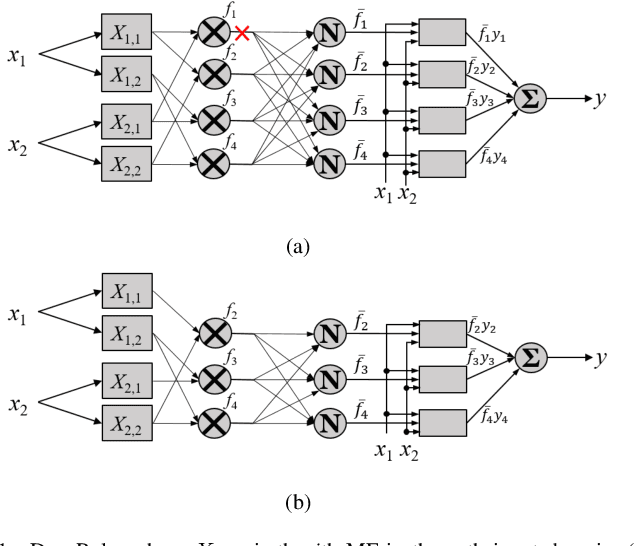
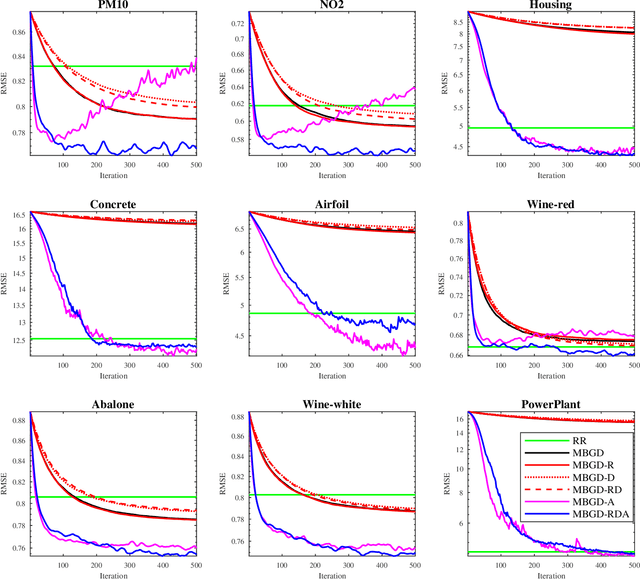
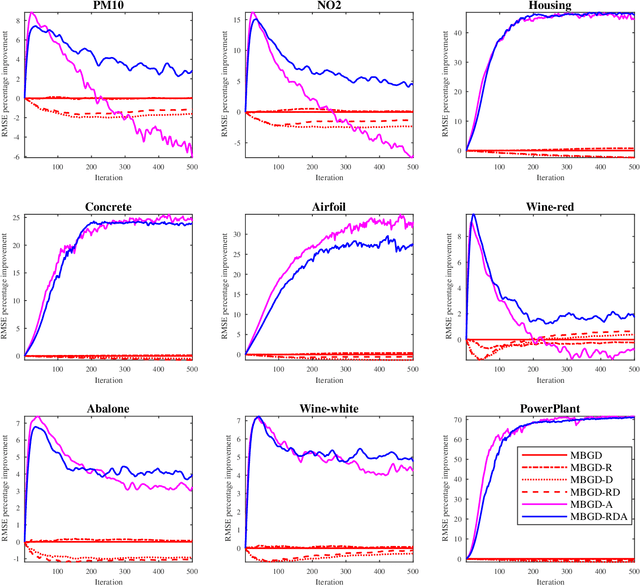
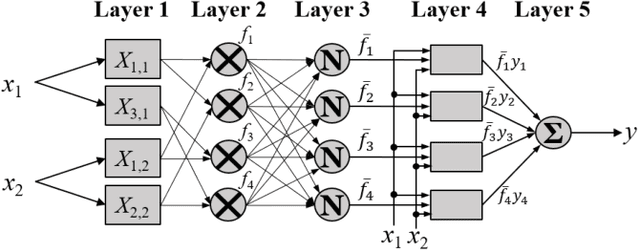
Takagi-Sugeno-Kang (TSK) fuzzy systems are very useful machine learning models for regression problems. However, to our knowledge, there has not existed an efficient and effective training algorithm that enables them to deal with big data. Inspired by the connections between TSK fuzzy systems and neural networks, we extend three powerful neural network optimization techniques, i.e., mini-batch gradient descent, regularization, and AdaBound, to TSK fuzzy systems, and also propose a novel DropRule technique specifically for training TSK fuzzy systems. Our final algorithm, mini-batch gradient descent with regularization, DropRule and AdaBound (MBGD-RDA), can achieve fast convergence in training TSK fuzzy systems, and also superior generalization performance in testing. It can be used for training TSK fuzzy systems on datasets of any size; however, it is particularly useful for big datasets, on which currently no other efficient training algorithms exist.
Active Stacking for Heart Rate Estimation
Mar 26, 2019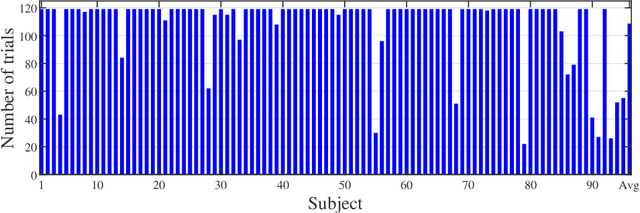
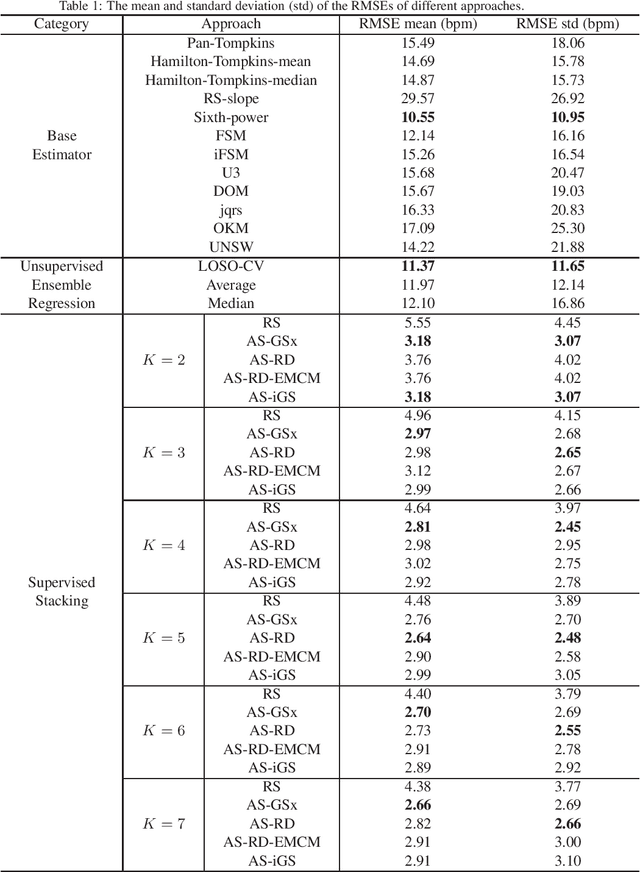
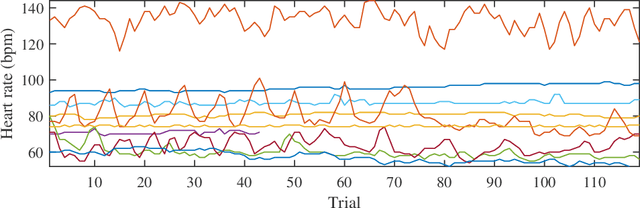
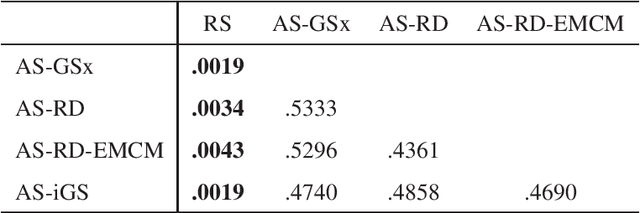
Heart rate estimation from electrocardiogram signals is very important for the early detection of cardiovascular diseases. However, due to large individual differences and varying electrocardiogram signal quality, there does not exist a single reliable estimation algorithm that works well on all subjects. Every algorithm may break down on certain subjects, resulting in a significant estimation error. Ensemble regression, which aggregates the outputs of multiple base estimators for more reliable and stable estimates, can be used to remedy this problem. Moreover, active learning can be used to optimally select a few trials from a new subject to label, based on which a stacking ensemble regression model can be trained to aggregate the base estimators. This paper proposes four active stacking approaches, and demonstrates that they all significantly outperform three common unsupervised ensemble regression approaches, and a supervised stacking approach which randomly selects some trials to label. Remarkably, our active stacking approaches only need three or four labeled trials from each subject to achieve an average root mean squared estimation error below three beats per minute, making them very convenient for real-world applications. To our knowledge, this is the first research on active stacking, and its application to heart rate estimation.
On the Functional Equivalence of TSK Fuzzy Systems to Neural Networks, Mixture of Experts, CART, and Stacking Ensemble Regression
Mar 25, 2019
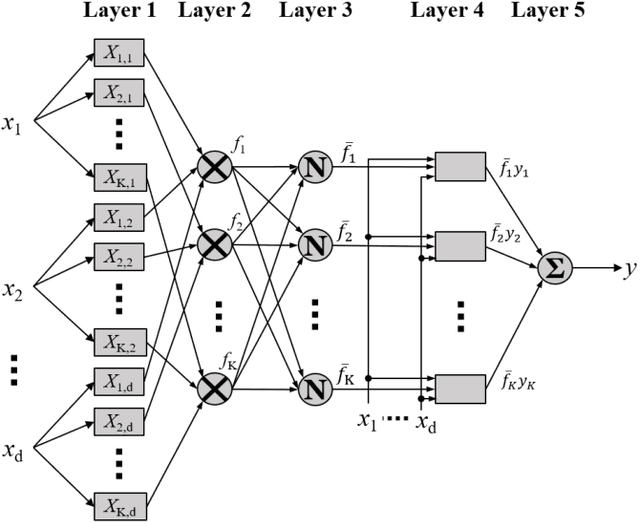
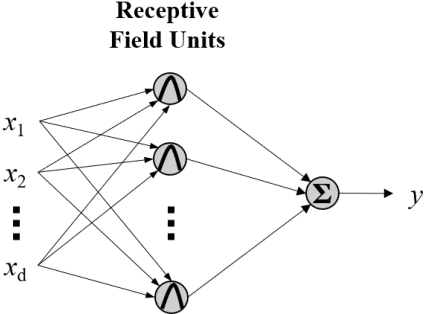
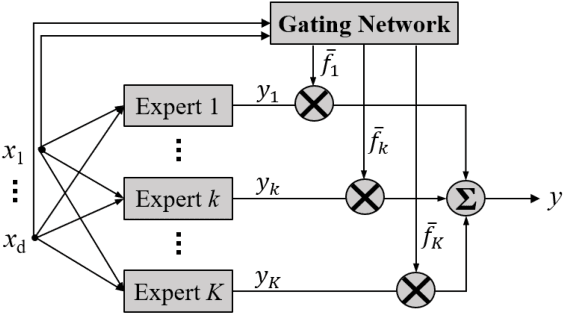
Fuzzy systems have achieved great success in numerous applications. However, there are still many challenges in designing an optimal fuzzy system, e.g., how to efficiently train its parameters, how to improve its performance without adding too many parameters, how to balance the trade-off between cooperations and competitions among the rules, how to overcome the curse of dimensionality, etc. Literature has shown that by making appropriate connections between fuzzy systems and other machine learning approaches, good practices from other domains may be used to improve the fuzzy systems, and vice versa. This paper gives an overview on the functional equivalence between Takagi-Sugeno-Kang fuzzy systems and four classic machine learning approaches -- neural networks, mixture of experts, classification and regression trees, and stacking ensemble regression -- for regression problems. We also point out some promising new research directions, inspired by the functional equivalence, that could lead to solutions to the aforementioned problems. To our knowledge, this is so far the most comprehensive overview on the connections between fuzzy systems and other popular machine learning approaches, and hopefully will stimulate more hybridization between different machine learning algorithms.
Wasserstein Distance based Deep Adversarial Transfer Learning for Intelligent Fault Diagnosis
Mar 02, 2019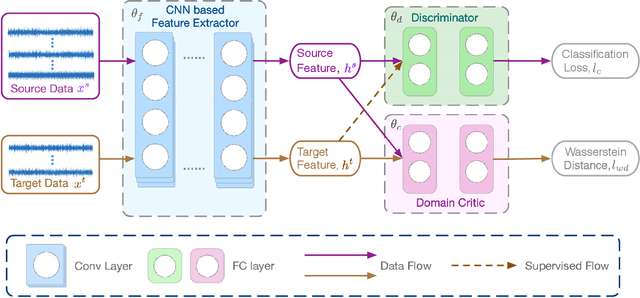

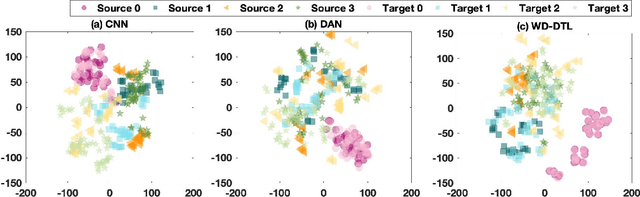
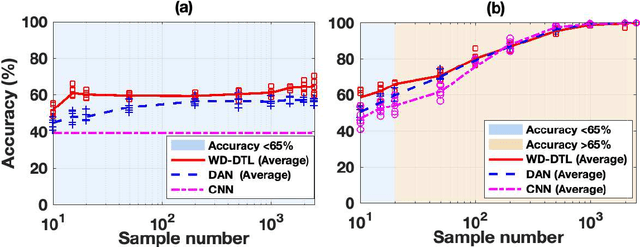
The demand of artificial intelligent adoption for condition-based maintenance strategy is astonishingly increased over the past few years. Intelligent fault diagnosis is one critical topic of maintenance solution for mechanical systems. Deep learning models, such as convolutional neural networks (CNNs), have been successfully applied to fault diagnosis tasks for mechanical systems and achieved promising results. However, for diverse working conditions in the industry, deep learning suffers two difficulties: one is that the well-defined (source domain) and new (target domain) datasets are with different feature distributions; another one is the fact that insufficient or no labelled data in target domain significantly reduce the accuracy of fault diagnosis. As a novel idea, deep transfer learning (DTL) is created to perform learning in the target domain by leveraging information from the relevant source domain. Inspired by Wasserstein distance of optimal transport, in this paper, we propose a novel DTL approach to intelligent fault diagnosis, namely Wasserstein Distance based Deep Transfer Learning (WD-DTL), to learn domain feature representations (generated by a CNN based feature extractor) and to minimize the distributions between the source and target domains through adversarial training. The effectiveness of the proposed WD-DTL is verified through 3 transfer scenarios and 16 transfer fault diagnosis experiments of both unsupervised and supervised (with insufficient labelled data) learning. We also provide a comprehensive analysis of the network visualization of those transfer tasks.
Multi-Tasking Evolutionary Algorithm (MTEA) for Single-Objective Continuous Optimization
Dec 15, 2018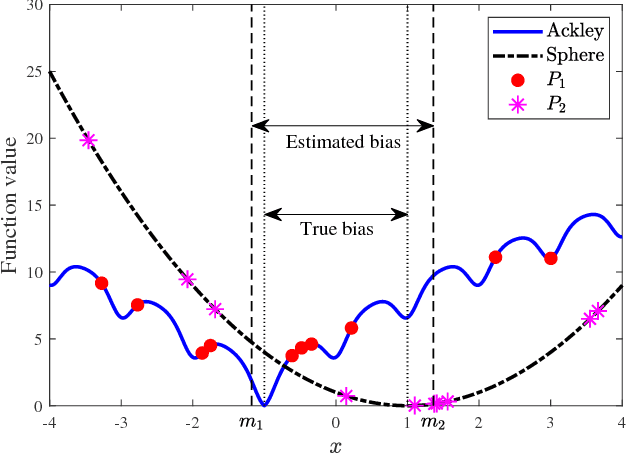
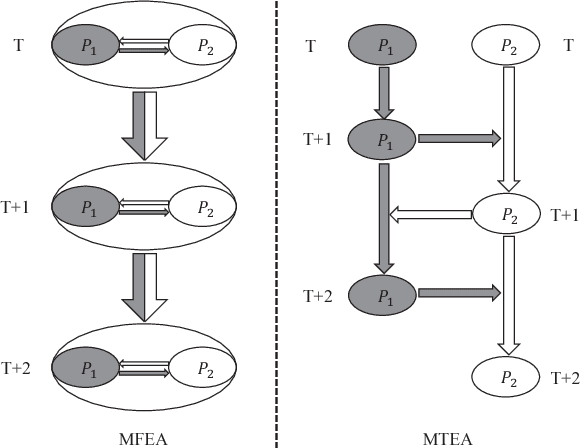
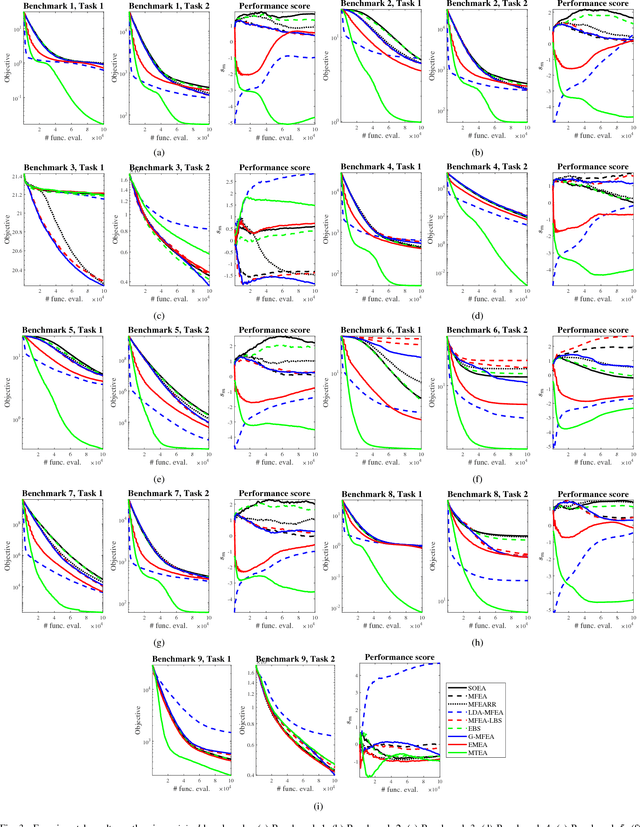
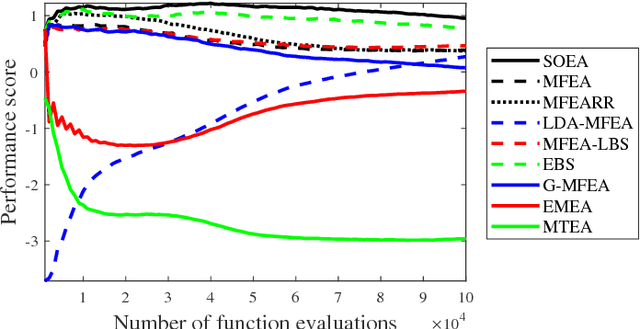
Multi-task learning uses auxiliary data or knowledge from relevant tasks to facilitate the learning in a new task. Multi-task optimization applies multi-task learning to optimization to study how to effectively and efficiently tackle multiple optimization problems simultaneously. Evolutionary multi-tasking, or multi-factorial optimization, is an emerging subfield of multi-task optimization, which integrates evolutionary computation and multi-task learning. This paper proposes a novel easy-to-implement multi-tasking evolutionary algorithm (MTEA), which copes well with significantly different optimization tasks by estimating and using the bias among them. Comparative studies with eight state-of-the-art single- and multi-task approaches in the literature on nine benchmarks demonstrated that on average the MTEA outperformed all of them, and has lower computational cost than six of them. Particularly, unlike other multi-task algorithms, the performance of the MTEA is consistently good whether the tasks are similar or significantly different, making it ideal for real-world applications.
Transfer Learning for Brain-Computer Interfaces: An Euclidean Space Data Alignment Approach
Aug 08, 2018
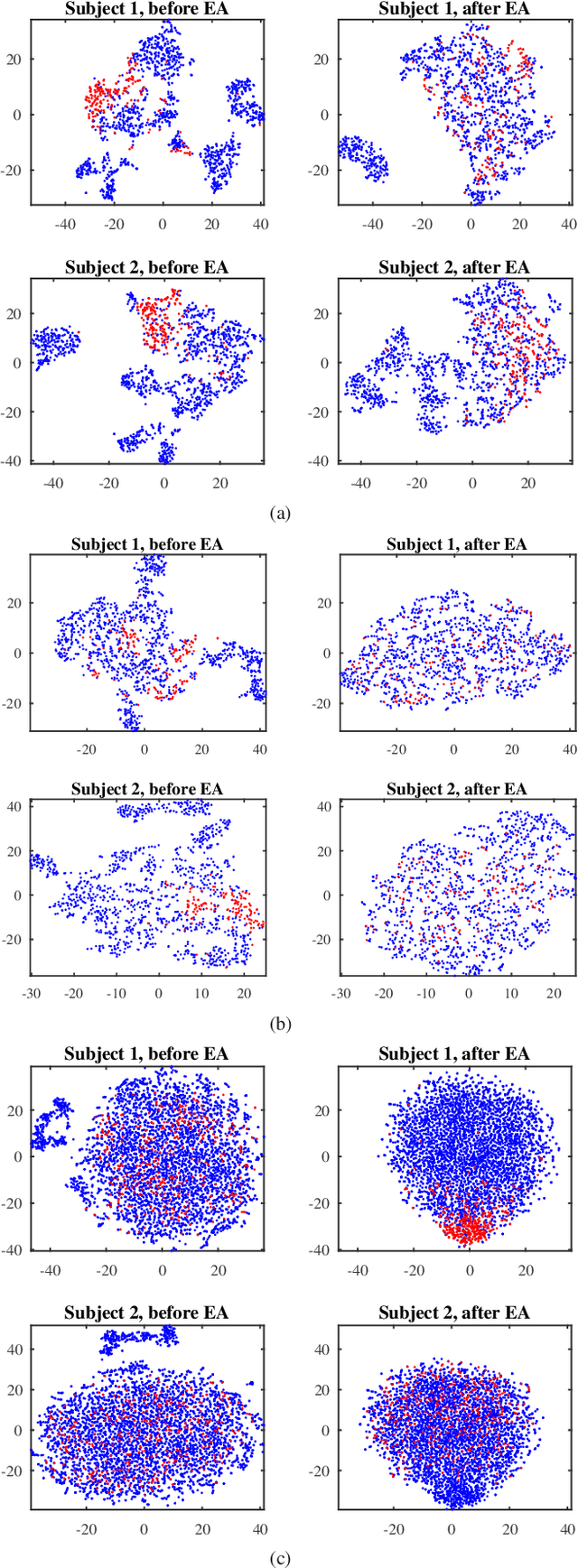
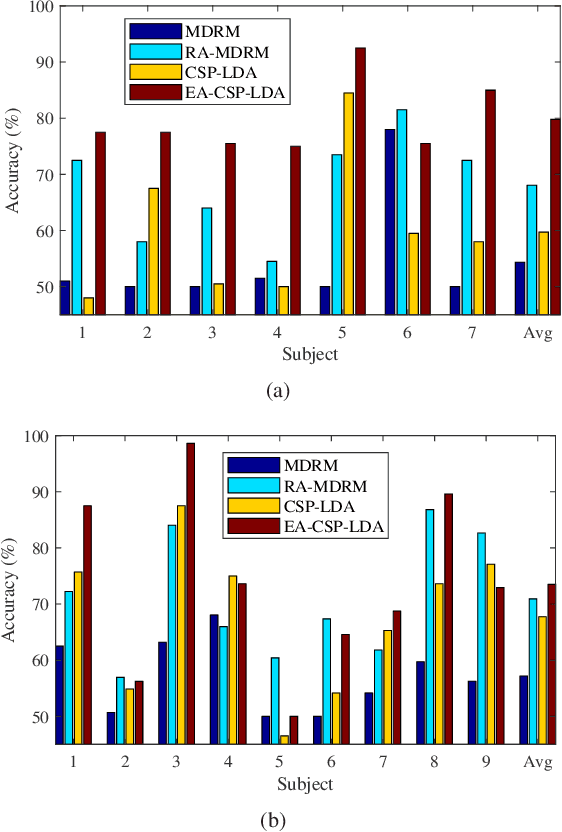
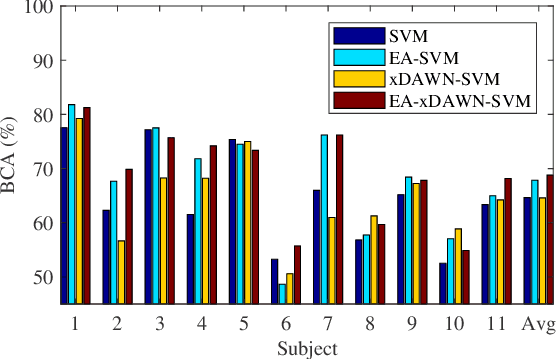
Almost all EEG-based brain-computer interfaces (BCIs) need some labeled subject-specific data to calibrate a new subject, as neural responses are different across subjects to even the same stimulus. So, a major challenge in developing high-performance and user-friendly BCIs is to cope with such individual differences so that the calibration can be reduced or even completely eliminated. This paper focuses on the latter. More specifically, we consider an offline application scenario, in which we have unlabeled EEG trials from a new subject, and would like to accurately label them by leveraging auxiliary labeled EEG trials from other subjects in the same task. To accommodate the individual differences, we propose a novel unsupervised approach to align the EEG trials from different subjects in the Euclidean space to make them more consistent. It has three desirable properties: 1) the aligned trial lie in the Euclidean space, which can be used by any Euclidean space signal processing and machine learning approach; 2) it can be computed very efficiently; and, 3) it does not need any labeled trials from the new subject. Experiments on motor imagery and event-related potentials demonstrated the effectiveness and efficiency of our approach.
EEG-Based Driver Drowsiness Estimation Using Convolutional Neural Networks
Aug 08, 2018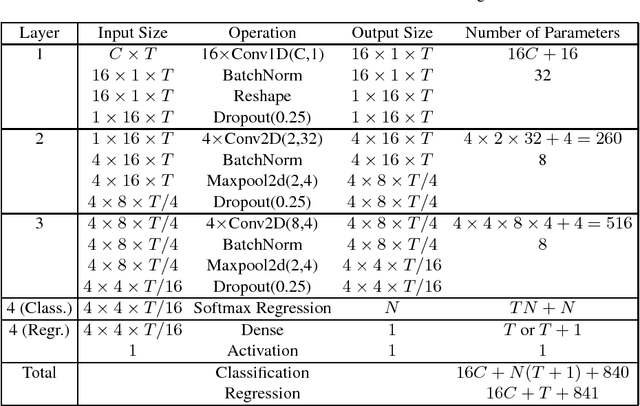
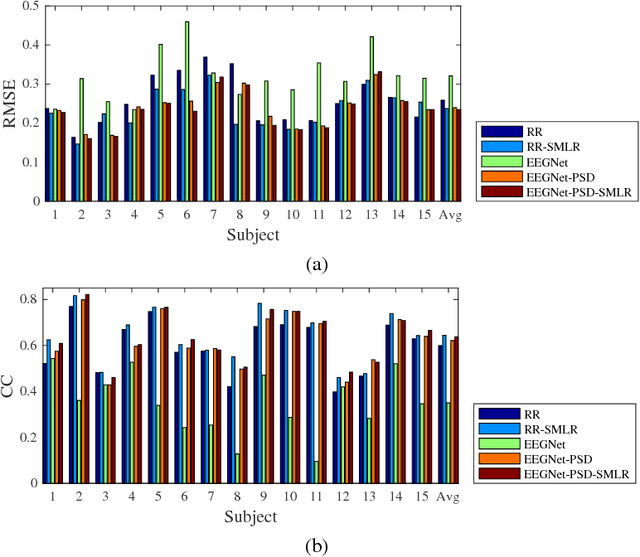

Deep learning, including convolutional neural networks (CNNs), has started finding applications in brain-computer interfaces (BCIs). However, so far most such approaches focused on BCI classification problems. This paper extends EEGNet, a 3-layer CNN model for BCI classification, to BCI regression, and also utilizes a novel spectral meta-learner for regression (SMLR) approach to aggregate multiple EEGNets for improved performance. Our model uses the power spectral density (PSD) of EEG signals as the input. Compared with raw EEG inputs, the PSD inputs can reduce the computational cost significantly, yet achieve much better regression performance. Experiments on driver drowsiness estimation from EEG signals demonstrate the outstanding performance of our approach.