 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust quantum dots charge autotuning using neural networks uncertainty
Jun 07, 2024This study presents a machine-learning-based procedure to automate the charge tuning of semiconductor spin qubits with minimal human intervention, addressing one of the significant challenges in scaling up quantum dot technologies. This method exploits artificial neural networks to identify noisy transition lines in stability diagrams, guiding a robust exploration strategy leveraging neural networks' uncertainty estimations. Tested across three distinct offline experimental datasets representing different single quantum dot technologies, the approach achieves over 99% tuning success rate in optimal cases, where more than 10% of the success is directly attributable to uncertainty exploitation. The challenging constraints of small training sets containing high diagram-to-diagram variability allowed us to evaluate the capabilities and limits of the proposed procedure.
A Cryogenic Memristive Neural Decoder for Fault-tolerant Quantum Error Correction
Jul 18, 2023Neural decoders for quantum error correction (QEC) rely on neural networks to classify syndromes extracted from error correction codes and find appropriate recovery operators to protect logical information against errors. Despite the good performance of neural decoders, important practical requirements remain to be achieved, such as minimizing the decoding time to meet typical rates of syndrome generation in repeated error correction schemes, and ensuring the scalability of the decoding approach as the code distance increases. Designing a dedicated integrated circuit to perform the decoding task in co-integration with a quantum processor appears necessary to reach these decoding time and scalability requirements, as routing signals in and out of a cryogenic environment to be processed externally leads to unnecessary delays and an eventual wiring bottleneck. In this work, we report the design and performance analysis of a neural decoder inference accelerator based on an in-memory computing (IMC) architecture, where crossbar arrays of resistive memory devices are employed to both store the synaptic weights of the decoder neural network and perform analog matrix-vector multiplications during inference. In proof-of-concept numerical experiments supported by experimental measurements, we investigate the impact of TiO$_\textrm{x}$-based memristive devices' non-idealities on decoding accuracy. Hardware-aware training methods are developed to mitigate the loss in accuracy, allowing the memristive neural decoders to achieve a pseudo-threshold of $9.23\times 10^{-4}$ for the distance-three surface code, whereas the equivalent digital neural decoder achieves a pseudo-threshold of $1.01\times 10^{-3}$. This work provides a pathway to scalable, fast, and low-power cryogenic IMC hardware for integrated QEC.
Hardware-aware Training Techniques for Improving Robustness of Ex-Situ Neural Network Transfer onto Passive TiO2 ReRAM Crossbars
May 29, 2023



Passive resistive random access memory (ReRAM) crossbar arrays, a promising emerging technology used for analog matrix-vector multiplications, are far superior to their active (1T1R) counterparts in terms of the integration density. However, current transfers of neural network weights into the conductance state of the memory devices in the crossbar architecture are accompanied by significant losses in precision due to hardware variabilities such as sneak path currents, biasing scheme effects and conductance tuning imprecision. In this work, training approaches that adapt techniques such as dropout, the reparametrization trick and regularization to TiO2 crossbar variabilities are proposed in order to generate models that are better adapted to their hardware transfers. The viability of this approach is demonstrated by comparing the outputs and precision of the proposed hardware-aware network with those of a regular fully connected network over a few thousand weight transfers using the half moons dataset in a simulation based on experimental data. For the neural network trained using the proposed hardware-aware method, 79.5% of the test set's data points can be classified with an accuracy of 95% or higher, while only 18.5% of the test set's data points can be classified with this accuracy by the regularly trained neural network.
Voltage-Dependent Synaptic Plasticity (VDSP): Unsupervised probabilistic Hebbian plasticity rule based on neurons membrane potential
Apr 14, 2022
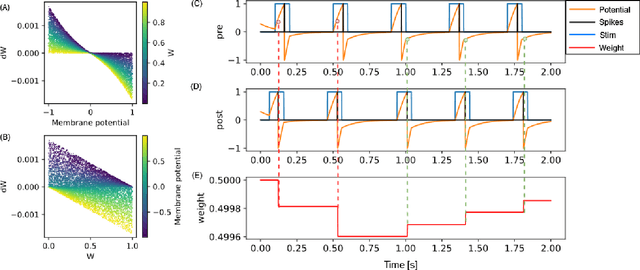
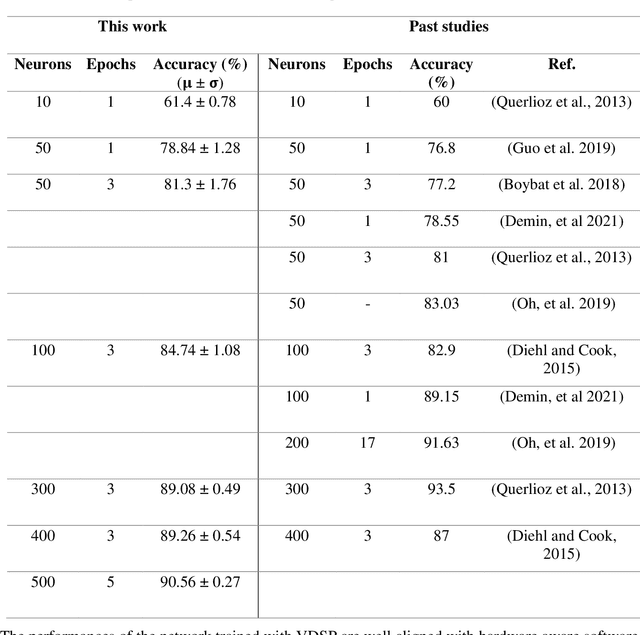
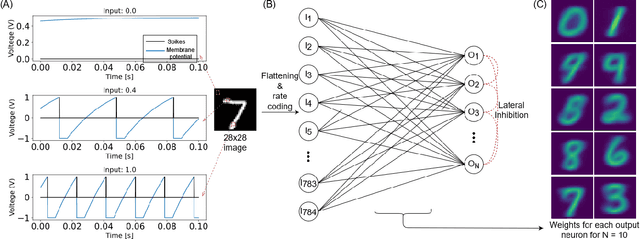
This study proposes voltage-dependent-synaptic plasticity (VDSP), a novel brain-inspired unsupervised local learning rule for the online implementation of Hebb's plasticity mechanism on neuromorphic hardware. The proposed VDSP learning rule updates the synaptic conductance on the spike of the postsynaptic neuron only, which reduces by a factor of two the number of updates with respect to standard spike-timing-dependent plasticity (STDP). This update is dependent on the membrane potential of the presynaptic neuron, which is readily available as part of neuron implementation and hence does not require additional memory for storage. Moreover, the update is also regularized on synaptic weight and prevents explosion or vanishing of weights on repeated stimulation. Rigorous mathematical analysis is performed to draw an equivalence between VDSP and STDP. To validate the system-level performance of VDSP, we train a single-layer spiking neural network (SNN) for the recognition of handwritten digits. We report 85.01 $ \pm $ 0.76% (Mean $ \pm $ S.D.) accuracy for a network of 100 output neurons on the MNIST dataset. The performance improves when scaling the network size (89.93 $ \pm $ 0.41% for 400 output neurons, 90.56 $ \pm $ 0.27 for 500 neurons), which validates the applicability of the proposed learning rule for large-scale computer vision tasks. Interestingly, the learning rule better adapts than STDP to the frequency of input signal and does not require hand-tuning of hyperparameters.
Signals to Spikes for Neuromorphic Regulated Reservoir Computing and EMG Hand Gesture Recognition
Jul 04, 2021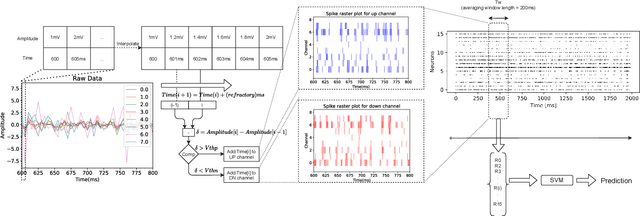
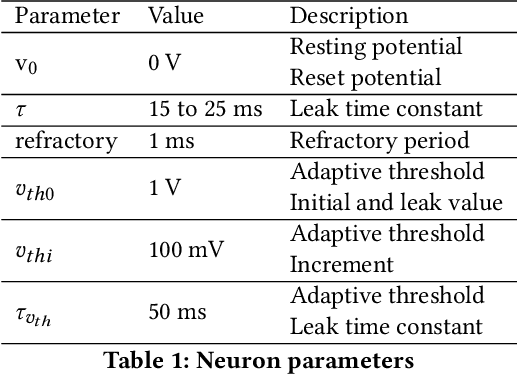
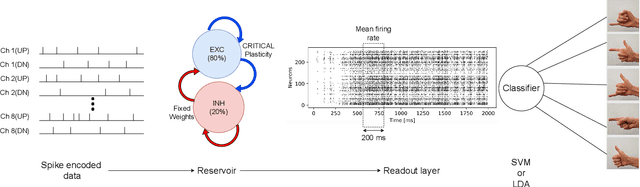
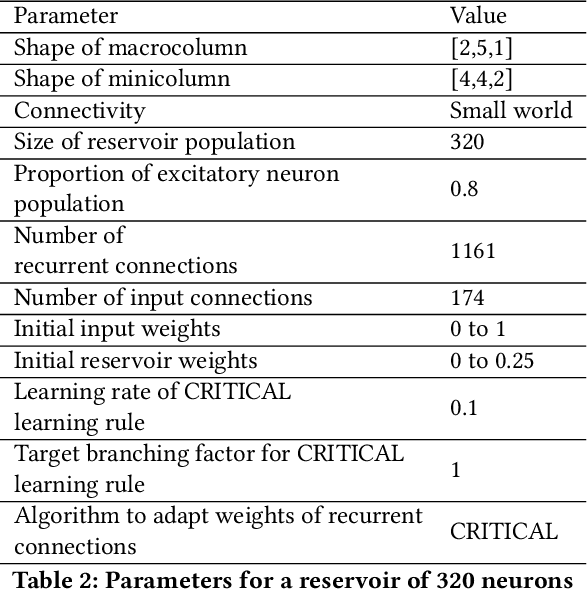
Surface electromyogram (sEMG) signals result from muscle movement and hence they are an ideal candidate for benchmarking event-driven sensing and computing. We propose a simple yet novel approach for optimizing the spike encoding algorithm's hyper-parameters inspired by the readout layer concept in reservoir computing. Using a simple machine learning algorithm after spike encoding, we report performance higher than the state-of-the-art spiking neural networks on two open-source datasets for hand gesture recognition. The spike encoded data is processed through a spiking reservoir with a biologically inspired topology and neuron model. When trained with the unsupervised activity regulation CRITICAL algorithm to operate at the edge of chaos, the reservoir yields better performance than state-of-the-art convolutional neural networks. The reservoir performance with regulated activity was found to be 89.72% for the Roshambo EMG dataset and 70.6% for the EMG subset of sensor fusion dataset. Therefore, the biologically-inspired computing paradigm, which is known for being power efficient, also proves to have a great potential when compared with conventional AI algorithms.