 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Solution for Breast Tumor Segmentation and Classification in Ultrasound Images Using Deep Adversarial Learning
Jul 01, 2019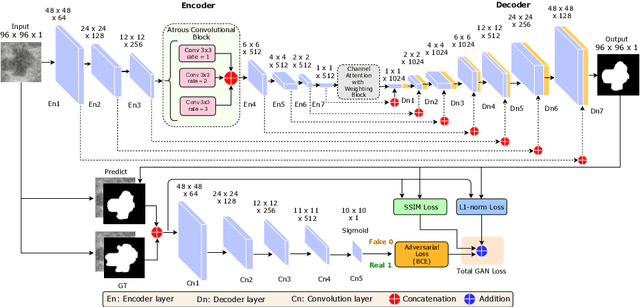
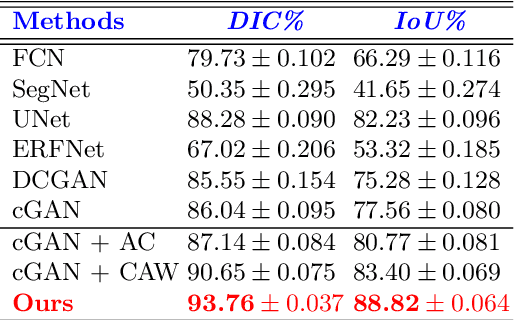
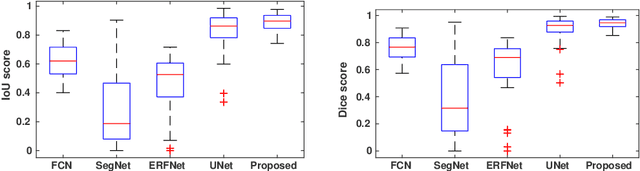

This paper proposes an efficient solution for tumor segmentation and classification in breast ultrasound (BUS) images. We propose to add an atrous convolution layer to the conditional generative adversarial network (cGAN) segmentation model to learn tumor features at different resolutions of BUS images. To automatically re-balance the relative impact of each of the highest level encoded features, we also propose to add a channel-wise weighting block in the network. In addition, the SSIM and L1-norm loss with the typical adversarial loss are used as a loss function to train the model. Our model outperforms the state-of-the-art segmentation models in terms of the Dice and IoU metrics, achieving top scores of 93.76% and 88.82%, respectively. In the classification stage, we show that few statistics features extracted from the shape of the boundaries of the predicted masks can properly discriminate between benign and malignant tumors with an accuracy of 85%$
MobileGAN: Skin Lesion Segmentation Using a Lightweight Generative Adversarial Network
Jul 01, 2019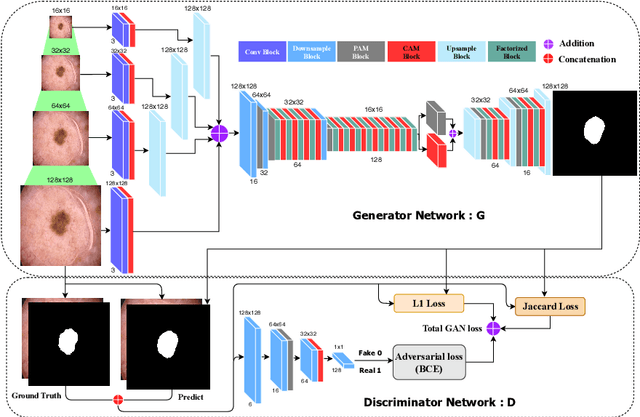
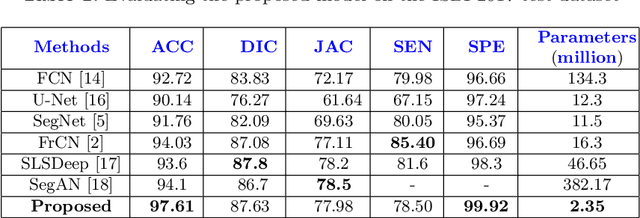
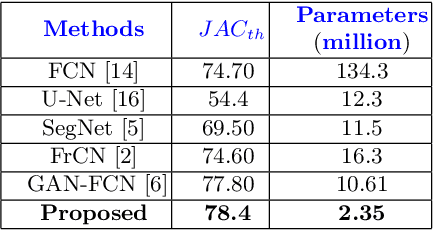
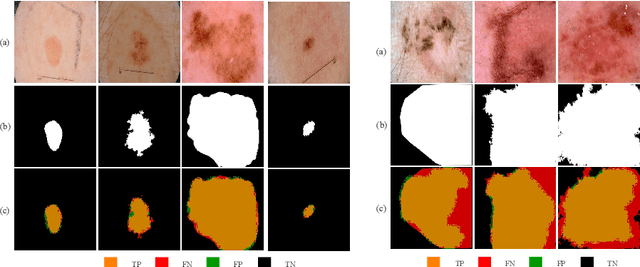
Skin lesion segmentation in dermoscopic images is a challenge due to their blurry and irregular boundaries. Most of the segmentation approaches based on deep learning are time and memory consuming due to the hundreds of millions of parameters. Consequently, it is difficult to apply them to real dermatoscope devices with limited GPU and memory resources. In this paper, we propose a lightweight and efficient Generative Adversarial Networks (GAN) model, called MobileGAN for skin lesion segmentation. More precisely, the MobileGAN combines 1D non-bottleneck factorization networks with position and channel attention modules in a GAN model. The proposed model is evaluated on the test dataset of the ISBI 2017 challenges and the validation dataset of ISIC 2018 challenges. Although the proposed network has only 2.35 millions of parameters, it is still comparable with the state-of-the-art. The experimental results show that our MobileGAN obtains comparable performance with an accuracy of 97.61%.
Hierarchical approach to classify food scenes in egocentric photo-streams
May 10, 2019
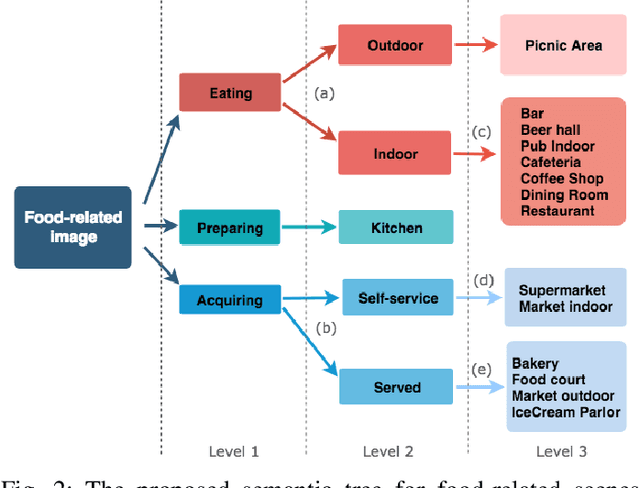
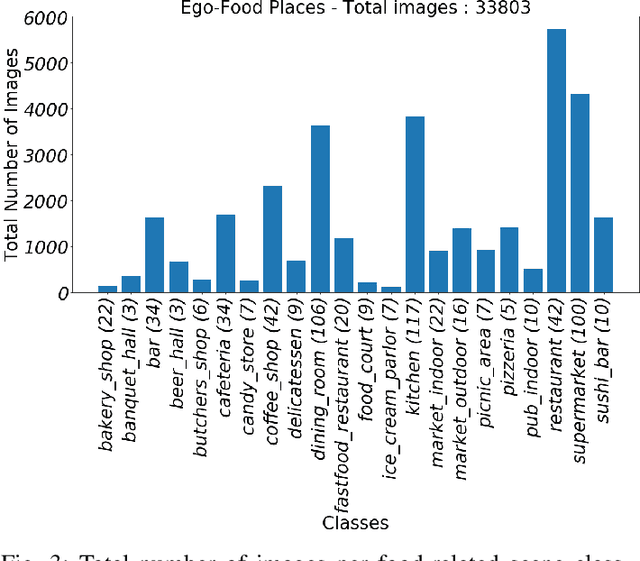
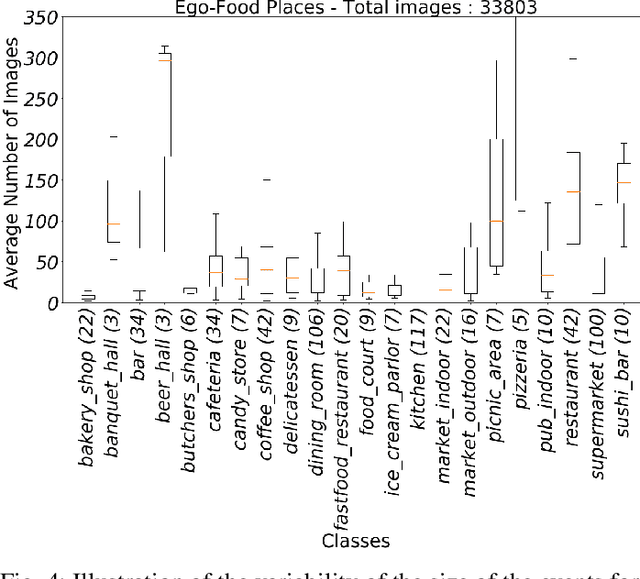
Recent studies have shown that the environment where people eat can affect their nutritional behaviour. In this work, we provide automatic tools for a personalised analysis of a person's health habits by the examination of daily recorded egocentric photo-streams. Specifically, we propose a new automatic approach for the classification of food-related environments, that is able to classify up to 15 such scenes. In this way, people can monitor the context around their food intake in order to get an objective insight into their daily eating routine. We propose a model that classifies food-related scenes organized in a semantic hierarchy. Additionally, we present and make available a new egocentric dataset composed of more than 33000 images recorded by a wearable camera, over which our proposed model has been tested. Our approach obtains an accuracy and F-score of 56\% and 65\%, respectively, clearly outperforming the baseline methods.
Breast Tumor Segmentation and Shape Classification in Mammograms using Generative Adversarial and Convolutional Neural Network
Oct 23, 2018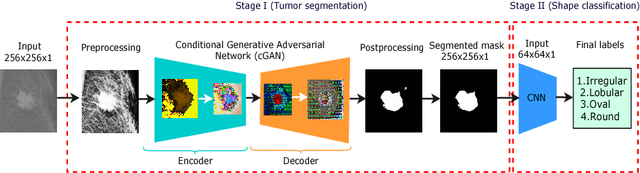
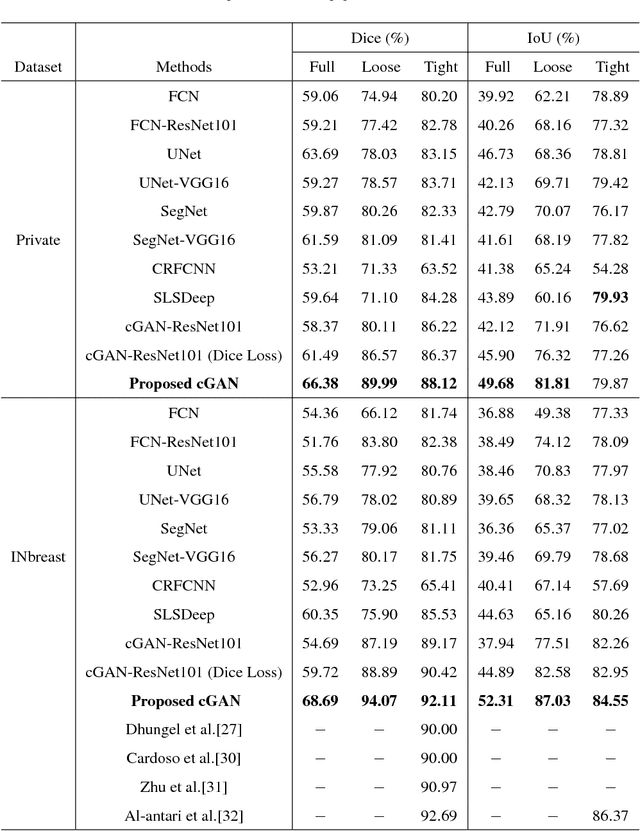
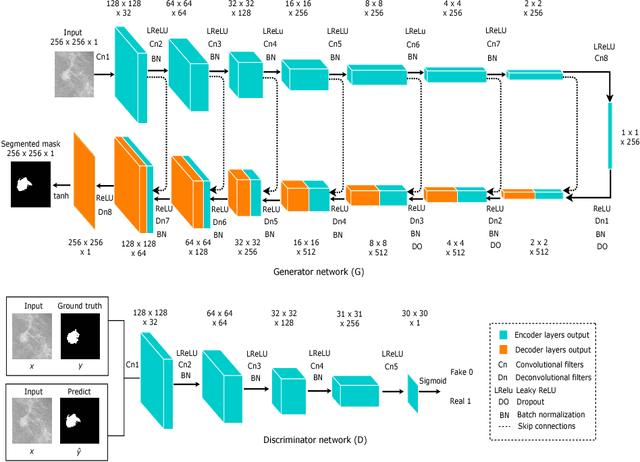
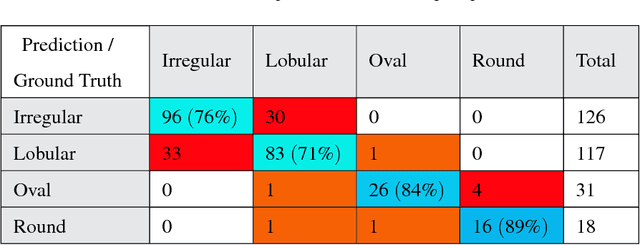
Mammogram inspection in search of breast tumors is a tough assignment that radiologists must carry out frequently. Therefore, image analysis methods are needed for the detection and delineation of breast masses, which portray crucial morphological information that will support reliable diagnosis. In this paper, we proposed a conditional Generative Adversarial Network (cGAN) devised to segment a breast mass within a region of interest (ROI) in a mammogram. The generative network learns to recognize the breast mass area and to create the binary mask that outlines the breast mass. In turn, the adversarial network learns to distinguish between real (ground truth) and synthetic segmentations, thus enforcing the generative network to create binary masks as realistic as possible. The cGAN works well even when the number of training samples are limited. Therefore, the proposed method outperforms several state-of-the-art approaches. This hypothesis is corroborated by diverse experiments performed on two datasets, the public INbreast and a private in-house dataset. The proposed segmentation model provides a high Dice coefficient and Intersection over Union (IoU) of 94% and 87%, respectively. In addition, a shape descriptor based on a Convolutional Neural Network (CNN) is proposed to classify the generated masks into four mass shapes: irregular, lobular, oval and round. The proposed shape descriptor was trained on Digital Database for Screening Mammography (DDSM) yielding an overall accuracy of 80%, which outperforms the current state-of-the-art.
Identification and Visualization of the Underlying Independent Causes of the Diagnostic of Diabetic Retinopathy made by a Deep Learning Classifier
Sep 23, 2018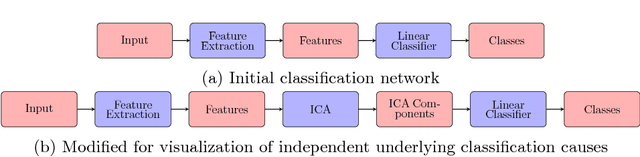
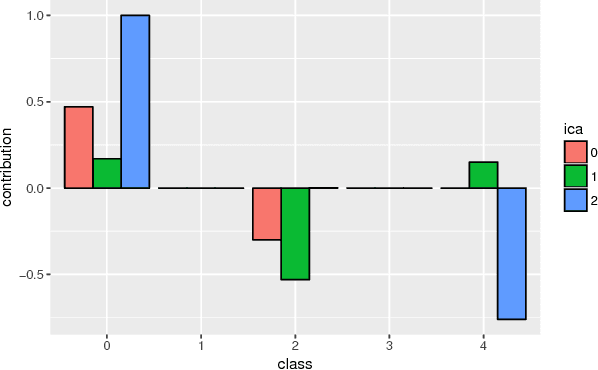
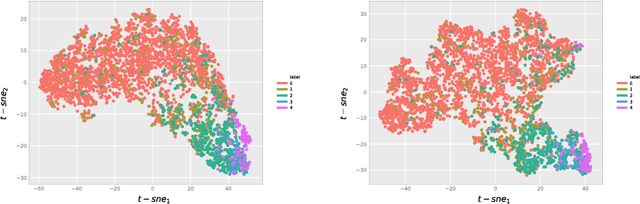
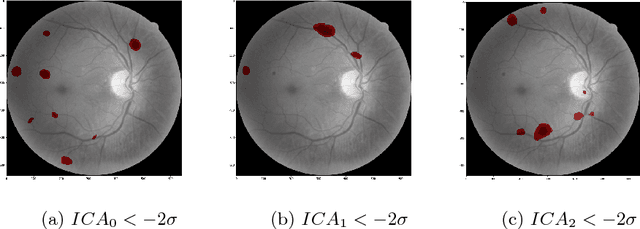
Interpretability is a key factor in the design of automatic classifiers for medical diagnosis. Deep learning models have been proven to be a very effective classification algorithm when trained in a supervised way with enough data. The main concern is the difficulty of inferring rationale interpretations from them. Different attempts have been done in last years in order to convert deep learning classifiers from high confidence statistical black box machines into self-explanatory models. In this paper we go forward into the generation of explanations by identifying the independent causes that use a deep learning model for classifying an image into a certain class. We use a combination of Independent Component Analysis with a Score Visualization technique. In this paper we study the medical problem of classifying an eye fundus image into 5 levels of Diabetic Retinopathy. We conclude that only 3 independent components are enough for the differentiation and correct classification between the 5 disease standard classes. We propose a method for visualizing them and detecting lesions from the generated visual maps.
MACNet: Multi-scale Atrous Convolution Networks for Food Places Classification in Egocentric Photo-streams
Aug 29, 2018
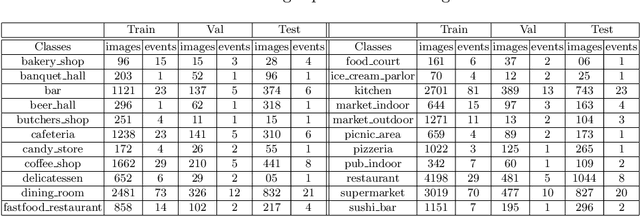
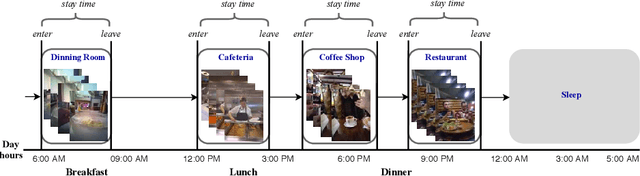
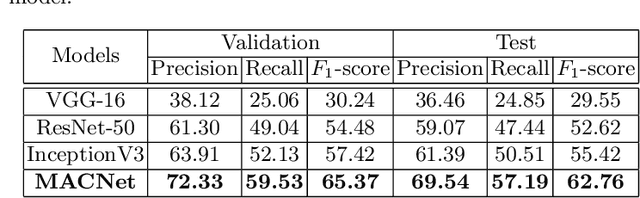
First-person (wearable) camera continually captures unscripted interactions of the camera user with objects, people, and scenes reflecting his personal and relational tendencies. One of the preferences of people is their interaction with food events. The regulation of food intake and its duration has a great importance to protect against diseases. Consequently, this work aims to develop a smart model that is able to determine the recurrences of a person on food places during a day. This model is based on a deep end-to-end model for automatic food places recognition by analyzing egocentric photo-streams. In this paper, we apply multi-scale Atrous convolution networks to extract the key features related to food places of the input images. The proposed model is evaluated on an in-house private dataset called "EgoFoodPlaces". Experimental results shows promising results of food places classification recognition in egocentric photo-streams.
Retinal Optic Disc Segmentation using Conditional Generative Adversarial Network
Jun 11, 2018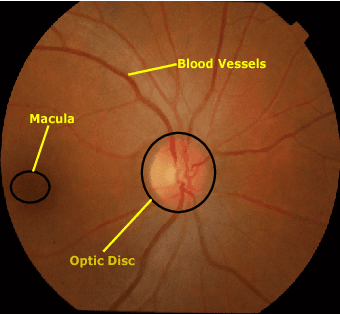
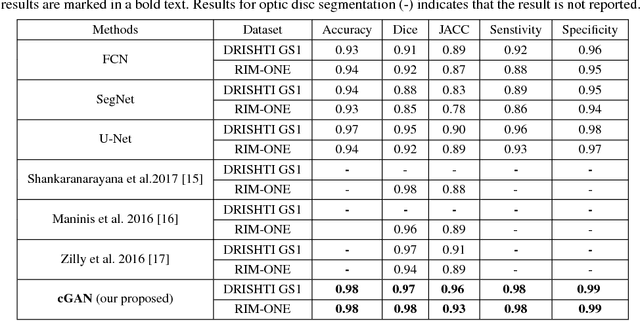
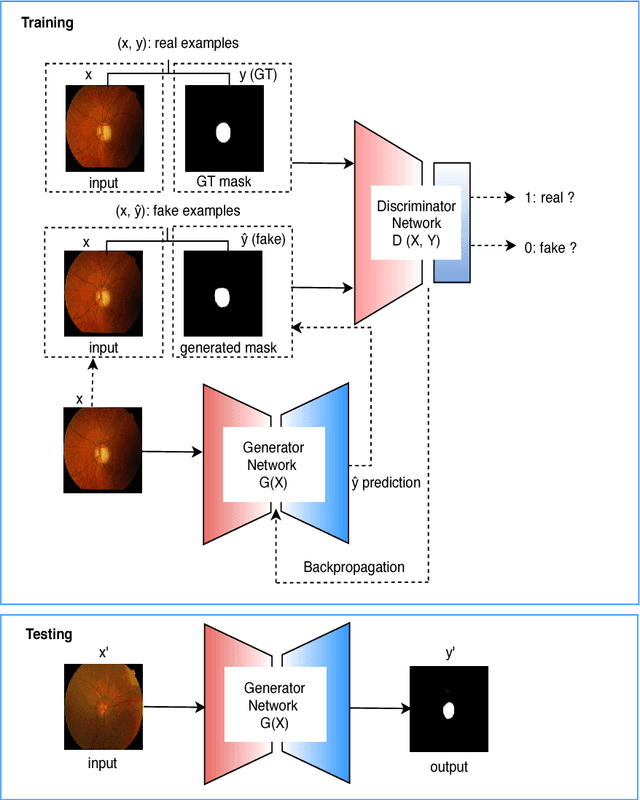
This paper proposed a retinal image segmentation method based on conditional Generative Adversarial Network (cGAN) to segment optic disc. The proposed model consists of two successive networks: generator and discriminator. The generator learns to map information from the observing input (i.e., retinal fundus color image), to the output (i.e., binary mask). Then, the discriminator learns as a loss function to train this mapping by comparing the ground-truth and the predicted output with observing the input image as a condition.Experiments were performed on two publicly available dataset; DRISHTI GS1 and RIM-ONE. The proposed model outperformed state-of-the-art-methods by achieving around 0.96% and 0.98% of Jaccard and Dice coefficients, respectively. Moreover, an image segmentation is performed in less than a second on recent GPU.
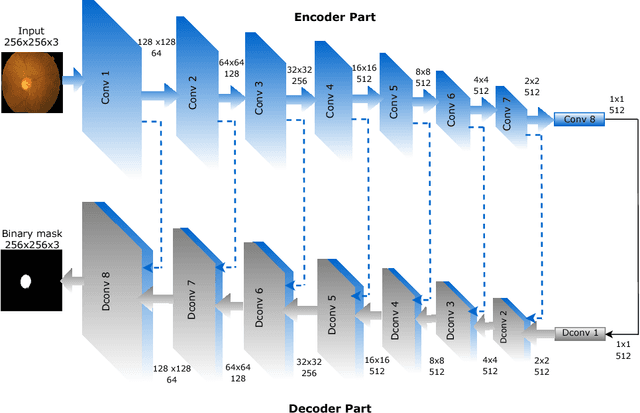
Conditional Generative Adversarial and Convolutional Networks for X-ray Breast Mass Segmentation and Shape Classification
Jun 10, 2018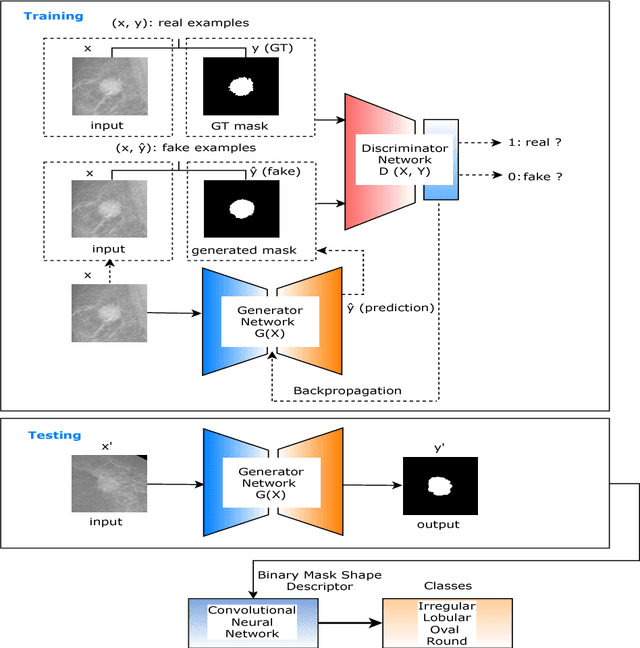
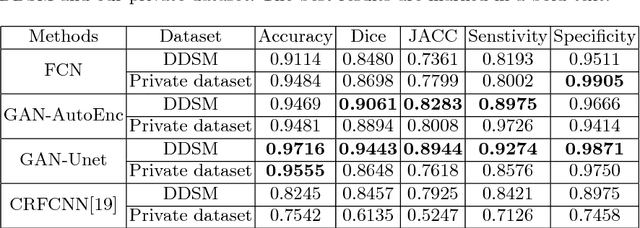
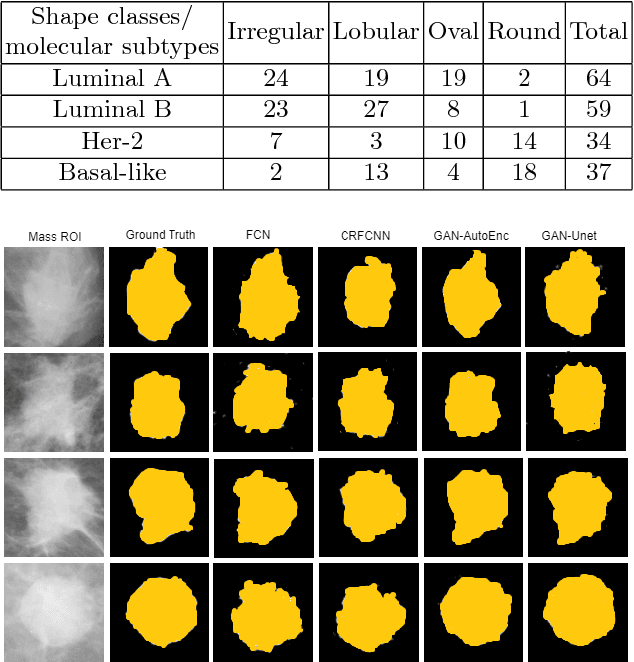
This paper proposes a novel approach based on conditional Generative Adversarial Networks (cGAN) for breast mass segmentation in mammography. We hypothesized that the cGAN structure is well-suited to accurately outline the mass area, especially when the training data is limited. The generative network learns intrinsic features of tumors while the adversarial network enforces segmentations to be similar to the ground truth. Experiments performed on dozens of malignant tumors extracted from the public DDSM dataset and from our in-house private dataset confirm our hypothesis with very high Dice coefficient and Jaccard index (>94% and >89%, respectively) outperforming the scores obtained by other state-of-the-art approaches. Furthermore, in order to detect portray significant morphological features of the segmented tumor, a specific Convolutional Neural Network (CNN) have also been designed for classifying the segmented tumor areas into four types (irregular, lobular, oval and round), which provides an overall accuracy about 72% with the DDSM dataset.
CuisineNet: Food Attributes Classification using Multi-scale Convolution Network
Jun 08, 2018
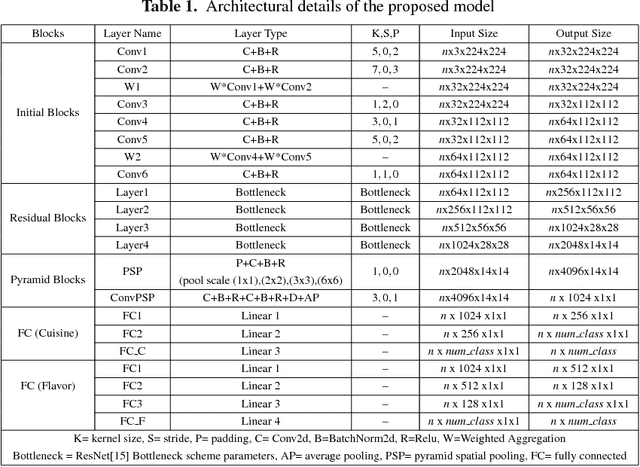
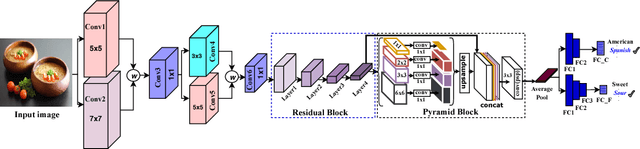
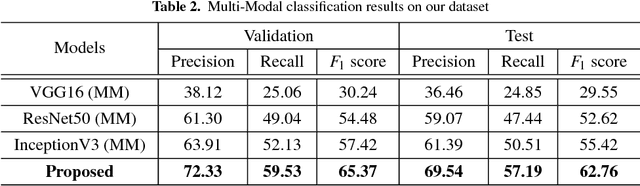
Diversity of food and its attributes represents the culinary habits of peoples from different countries. Thus, this paper addresses the problem of identifying food culture of people around the world and its flavor by classifying two main food attributes, cuisine and flavor. A deep learning model based on multi-scale convotuional networks is proposed for extracting more accurate features from input images. The aggregation of multi-scale convolution layers with different kernel size is also used for weighting the features results from different scales. In addition, a joint loss function based on Negative Log Likelihood (NLL) is used to fit the model probability to multi labeled classes for multi-modal classification task. Furthermore, this work provides a new dataset for food attributes, so-called Yummly48K, extracted from the popular food website, Yummly. Our model is assessed on the constructed Yummly48K dataset. The experimental results show that our proposed method yields 65% and 62% average F1 score on validation and test set which outperforming the state-of-the-art models.
SLSDeep: Skin Lesion Segmentation Based on Dilated Residual and Pyramid Pooling Networks
May 31, 2018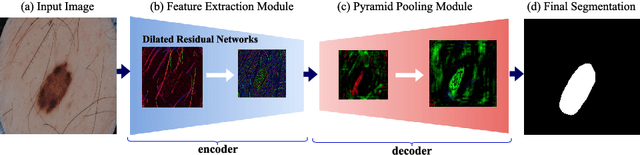
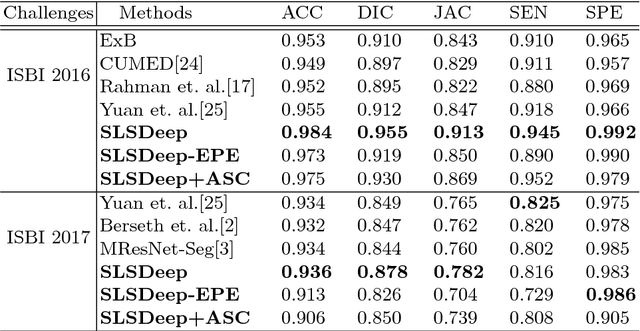
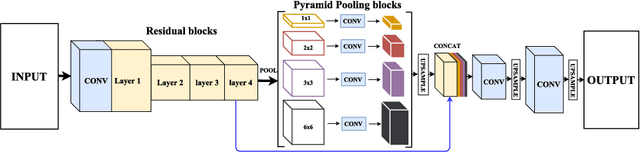
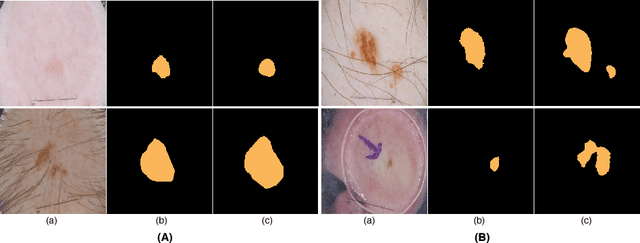
Skin lesion segmentation (SLS) in dermoscopic images is a crucial task for automated diagnosis of melanoma. In this paper, we present a robust deep learning SLS model, so-called SLSDeep, which is represented as an encoder-decoder network. The encoder network is constructed by dilated residual layers, in turn, a pyramid pooling network followed by three convolution layers is used for the decoder. Unlike the traditional methods employing a cross-entropy loss, we investigated a loss function by combining both Negative Log Likelihood (NLL) and End Point Error (EPE) to accurately segment the melanoma regions with sharp boundaries. The robustness of the proposed model was evaluated on two public databases: ISBI 2016 and 2017 for skin lesion analysis towards melanoma detection challenge. The proposed model outperforms the state-of-the-art methods in terms of segmentation accuracy. Moreover, it is capable to segment more than $100$ images of size 384x384 per second on a recent GPU.