 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Agents: A Post-Training Procedure for Internalized Multi-Agent Debate
Apr 27, 2026Multi-agent debate has been shown to improve reasoning in large language models (LLMs). However, it is compute-intensive, requiring generation of long transcripts before answering questions. To address this inefficiency, we develop a framework that distills multi-agent debate into a single LLM through a two-stage fine-tuning pipeline combining debate structure learning with internalization via dynamic reward scheduling and length clipping. Across multiple models and benchmarks, our internalized models match or exceed explicit multi-agent debate performance using up to 93% fewer tokens. We then investigate the mechanistic basis of this capability through activation steering, finding that internalization creates agent-specific subspaces: interpretable directions in activation space corresponding to different agent perspectives. We further demonstrate a practical application: by instilling malicious agents into the LLM through internalized debate, then applying negative steering to suppress them, we show that distillation makes harmful behaviors easier to localize and control with smaller reductions in general performance compared to steering base models. Our findings offer a new perspective for understanding multi-agent capabilities in distilled models and provide practical guidelines for controlling internalized reasoning behaviors. Code available at https://github.com/johnsk95/latent_agents
Take Caution in Using LLMs as Human Surrogates: Scylla Ex Machina
Oct 25, 2024



Recent studies suggest large language models (LLMs) can exhibit human-like reasoning, aligning with human behavior in economic experiments, surveys, and political discourse. This has led many to propose that LLMs can be used as surrogates for humans in social science research. However, LLMs differ fundamentally from humans, relying on probabilistic patterns, absent the embodied experiences or survival objectives that shape human cognition. We assess the reasoning depth of LLMs using the 11-20 money request game. Almost all advanced approaches fail to replicate human behavior distributions across many models, except in one case involving fine-tuning using a substantial amount of human behavior data. Causes of failure are diverse, relating to input language, roles, and safeguarding. These results caution against using LLMs to study human behaviors or as human surrogates.
Influence via Ethos: On the Persuasive Power of Reputation in Deliberation Online
Jun 01, 2020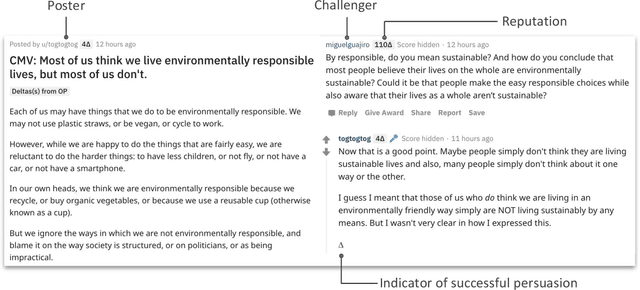
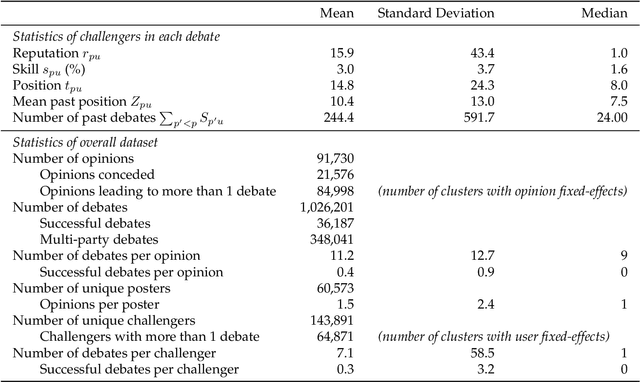
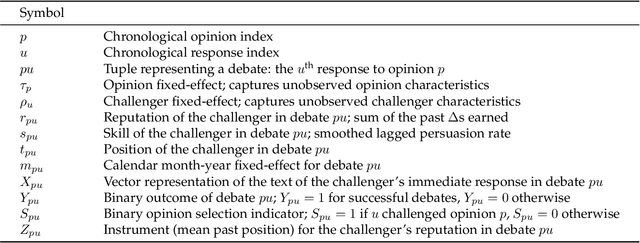
Deliberation among individuals online plays a key role in shaping the opinions that drive votes, purchases, donations and other critical offline behavior. Yet, the determinants of opinion-change via persuasion in deliberation online remain largely unexplored. Our research examines the persuasive power of $\textit{ethos}$ -- an individual's "reputation" -- using a 7-year panel of over a million debates from an argumentation platform containing explicit indicators of successful persuasion. We identify the causal effect of reputation on persuasion by constructing an instrument for reputation from a measure of past debate competition, and by controlling for unstructured argument text using neural models of language in the double machine-learning framework. We find that an individual's reputation significantly impacts their persuasion rate above and beyond the validity, strength and presentation of their arguments. In our setting, we find that having 10 additional reputation points causes a 31% increase in the probability of successful persuasion over the platform average. We also find that the impact of reputation is moderated by characteristics of the argument content, in a manner consistent with a theoretical model that attributes the persuasive power of reputation to heuristic information-processing under cognitive overload. We discuss managerial implications for platforms that facilitate deliberative decision-making for public and private organizations online.