 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretability Without Tradeoffs: Disentangling Polysemanticity At Equal Predictive Performance
May 29, 2026Deep neural networks (DNNs) are widely used, but interpreting what they actually learn remains difficult. A major obstacle is that individual neurons often encode multiple unrelated concepts, obscuring the decision process of the network. While prior work, such as sparse autoencoders, can separate these mixed signals into more meaningful, "monosemantic" features, this typically requires altering the model in ways that can degrade downstream performance. To overcome this, we introduce ELUDe (explicit, lossless, unsupervised disentanglement), a method for improving the interpretability of DNNs while preserving their functional equivalence. ELUDe breaks latent representations into clear, inspectable sub-units that behave like interpretable features, while guaranteeing that the model's outputs remain exactly the same. It requires no explicit training, no labels, and can be applied to pretrained models. ELUDe works by reorganizing how information flows between layers, re-routing concept-specific contributions while preserving the original computation by construction. Across several vision models, including DINOv2 and supervised ViT-B/16, ELUDe improves interpretability, keeps downstream accuracy unchanged, runs efficiently, and supports practical uses such as steering model representations. In short, ELUDe offers interpretability (almost) without a tradeoff: clearer, scalable, and actionable model insights with no loss in performance.
Beyond Accuracy: What Matters in Designing Well-Behaved Models?
Mar 21, 2025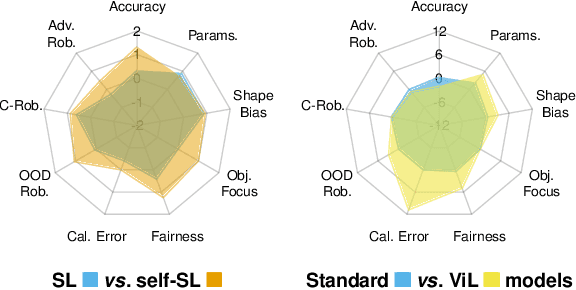

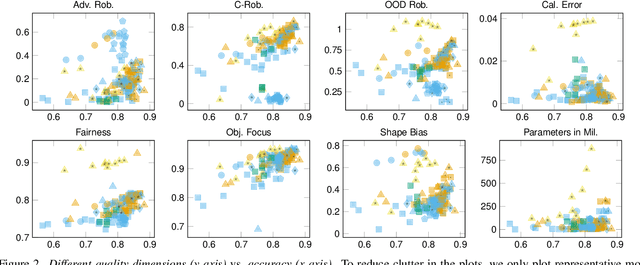
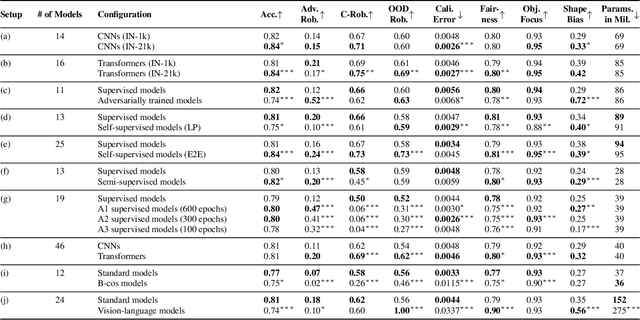
Deep learning has become an essential part of computer vision, with deep neural networks (DNNs) excelling in predictive performance. However, they often fall short in other critical quality dimensions, such as robustness, calibration, or fairness. While existing studies have focused on a subset of these quality dimensions, none have explored a more general form of "well-behavedness" of DNNs. With this work, we address this gap by simultaneously studying nine different quality dimensions for image classification. Through a large-scale study, we provide a bird's-eye view by analyzing 326 backbone models and how different training paradigms and model architectures affect the quality dimensions. We reveal various new insights such that (i) vision-language models exhibit high fairness on ImageNet-1k classification and strong robustness against domain changes; (ii) self-supervised learning is an effective training paradigm to improve almost all considered quality dimensions; and (iii) the training dataset size is a major driver for most of the quality dimensions. We conclude our study by introducing the QUBA score (Quality Understanding Beyond Accuracy), a novel metric that ranks models across multiple dimensions of quality, enabling tailored recommendations based on specific user needs.