 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Autoencoders for Studying the Manifold of Precoding Matrices with High Spectral Efficiency
Dec 01, 2021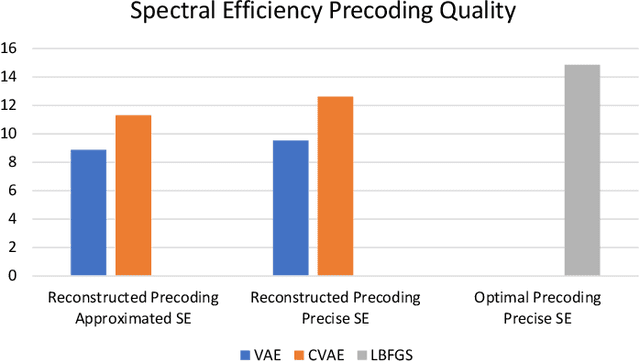
In multiple-input multiple-output (MIMO) wireless communications systems, neural networks have been employed for channel decoding, detection, channel estimation, and resource management. In this paper, we look at how to use a variational autoencoder to find a precoding matrix with a high Spectral Efficiency (SE). To collect optimal precoding matrices, an optimization approach is used. Our objective is to create a less time-consuming algorithm with minimum quality degradation. To build precoding matrices, we employed two forms of variational autoencoders: conventional variational autoencoders (VAE) and conditional variational autoencoders (CVAE). Both methods may be used to study a wide range of optimal precoding matrices. To the best of our knowledge, the development of precoding matrices for the spectral efficiency objective function (SE) utilising VAE and CVAE methods is being published for the first time.
Leveraging Recursive Gumbel-Max Trick for Approximate Inference in Combinatorial Spaces
Oct 28, 2021
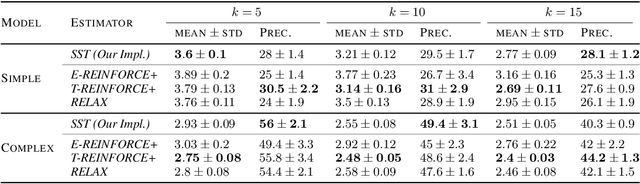
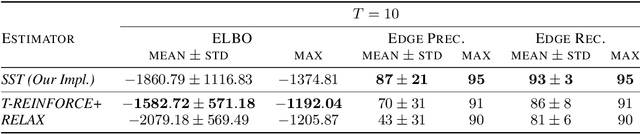
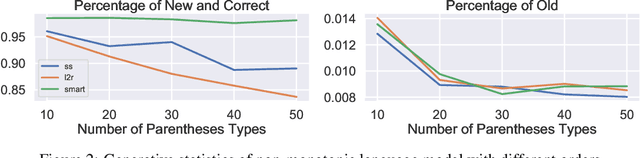
Structured latent variables allow incorporating meaningful prior knowledge into deep learning models. However, learning with such variables remains challenging because of their discrete nature. Nowadays, the standard learning approach is to define a latent variable as a perturbed algorithm output and to use a differentiable surrogate for training. In general, the surrogate puts additional constraints on the model and inevitably leads to biased gradients. To alleviate these shortcomings, we extend the Gumbel-Max trick to define distributions over structured domains. We avoid the differentiable surrogates by leveraging the score function estimators for optimization. In particular, we highlight a family of recursive algorithms with a common feature we call stochastic invariant. The feature allows us to construct reliable gradient estimates and control variates without additional constraints on the model. In our experiments, we consider various structured latent variable models and achieve results competitive with relaxation-based counterparts.
Automating Control of Overestimation Bias for Continuous Reinforcement Learning
Oct 26, 2021
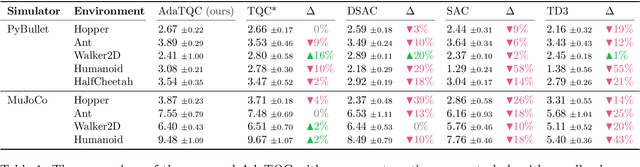

Bias correction techniques are used by most of the high-performing methods for off-policy reinforcement learning. However, these techniques rely on a pre-defined bias correction policy that is either not flexible enough or requires environment-specific tuning of hyperparameters. In this work, we present a simple data-driven approach for guiding bias correction. We demonstrate its effectiveness on the Truncated Quantile Critics -- a state-of-the-art continuous control algorithm. The proposed technique can adjust the bias correction across environments automatically. As a result, it eliminates the need for an extensive hyperparameter search, significantly reducing the actual number of interactions and computation.
Quantization of Generative Adversarial Networks for Efficient Inference: a Methodological Study
Aug 31, 2021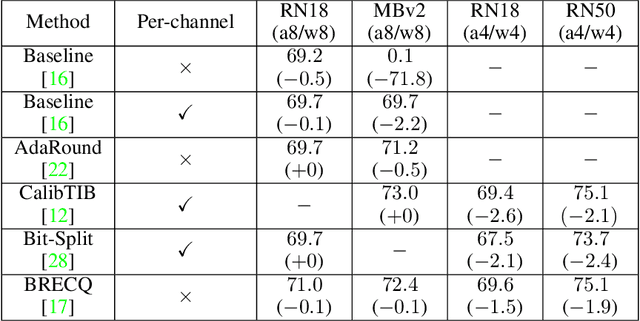
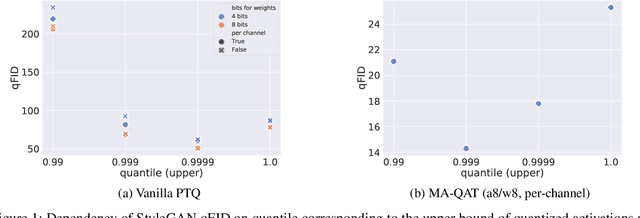
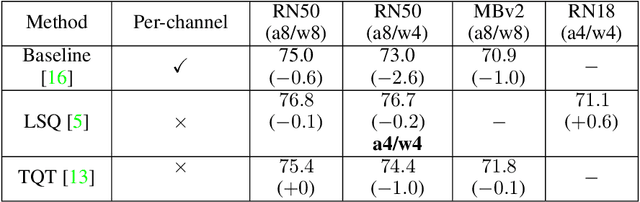

Generative adversarial networks (GANs) have an enormous potential impact on digital content creation, e.g., photo-realistic digital avatars, semantic content editing, and quality enhancement of speech and images. However, the performance of modern GANs comes together with massive amounts of computations performed during the inference and high energy consumption. That complicates, or even makes impossible, their deployment on edge devices. The problem can be reduced with quantization -- a neural network compression technique that facilitates hardware-friendly inference by replacing floating-point computations with low-bit integer ones. While quantization is well established for discriminative models, the performance of modern quantization techniques in application to GANs remains unclear. GANs generate content of a more complex structure than discriminative models, and thus quantization of GANs is significantly more challenging. To tackle this problem, we perform an extensive experimental study of state-of-art quantization techniques on three diverse GAN architectures, namely StyleGAN, Self-Attention GAN, and CycleGAN. As a result, we discovered practical recipes that allowed us to successfully quantize these models for inference with 4/8-bit weights and 8-bit activations while preserving the quality of the original full-precision models.
Mean Embeddings with Test-Time Data Augmentation for Ensembling of Representations
Jul 14, 2021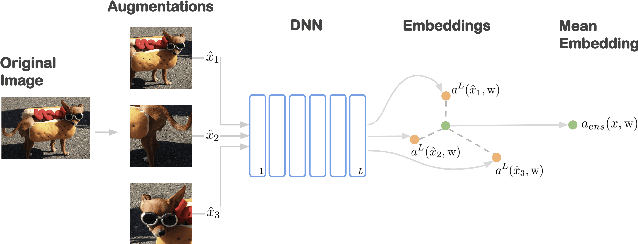
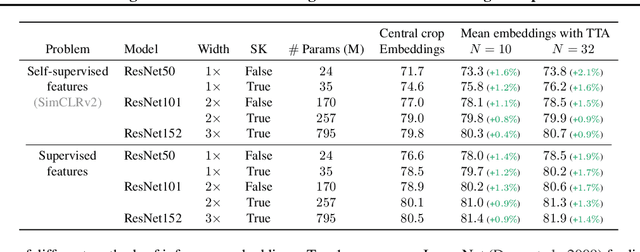
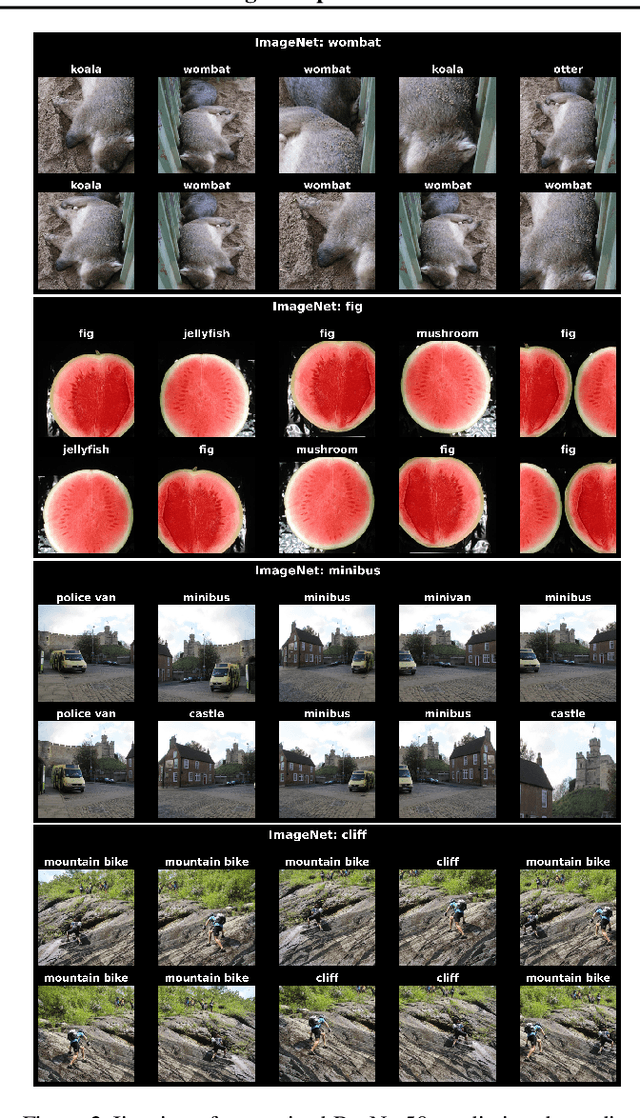
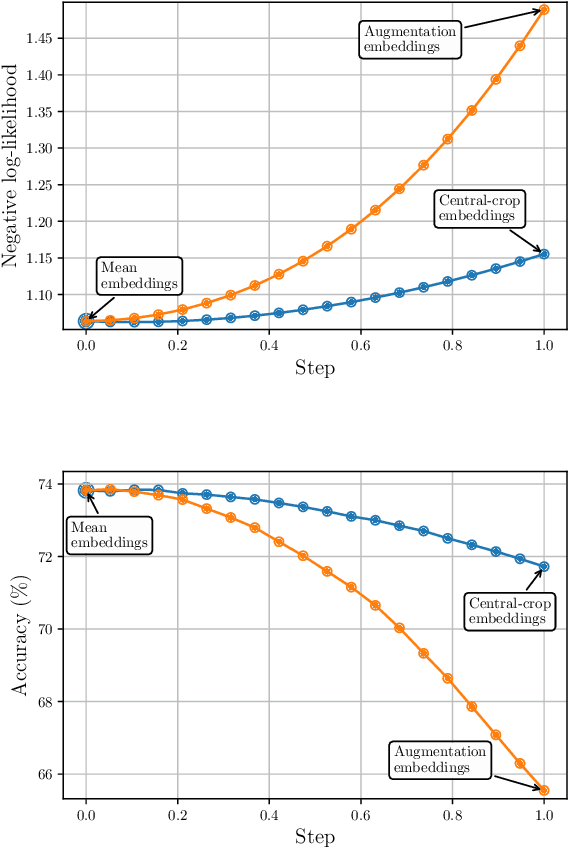
Averaging predictions over a set of models -- an ensemble -- is widely used to improve predictive performance and uncertainty estimation of deep learning models. At the same time, many machine learning systems, such as search, matching, and recommendation systems, heavily rely on embeddings. Unfortunately, due to misalignment of features of independently trained models, embeddings, cannot be improved with a naive deep ensemble like approach. In this work, we look at the ensembling of representations and propose mean embeddings with test-time augmentation (MeTTA) simple yet well-performing recipe for ensembling representations. Empirically we demonstrate that MeTTA significantly boosts the quality of linear evaluation on ImageNet for both supervised and self-supervised models. Even more exciting, we draw connections between MeTTA, image retrieval, and transformation invariant models. We believe that spreading the success of ensembles to inference higher-quality representations is the important step that will open many new applications of ensembling.
On the Periodic Behavior of Neural Network Training with Batch Normalization and Weight Decay
Jun 29, 2021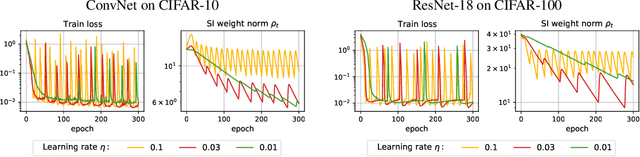

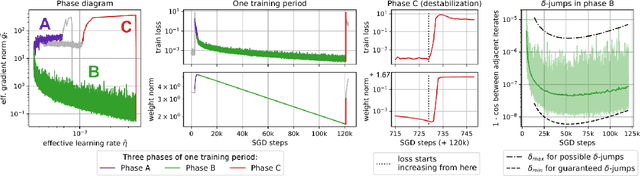
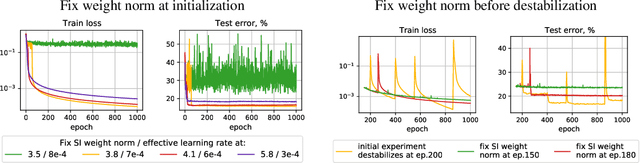
Despite the conventional wisdom that using batch normalization with weight decay may improve neural network training, some recent works show their joint usage may cause instabilities at the late stages of training. Other works, in contrast, show convergence to the equilibrium, i.e., the stabilization of training metrics. In this paper, we study this contradiction and show that instead of converging to a stable equilibrium, the training dynamics converge to consistent periodic behavior. That is, the training process regularly exhibits instabilities which, however, do not lead to complete training failure, but cause a new period of training. We rigorously investigate the mechanism underlying this discovered periodic behavior both from an empirical and theoretical point of view and show that this periodic behavior is indeed caused by the interaction between batch normalization and weight decay.
Towards Practical Credit Assignment for Deep Reinforcement Learning
Jun 08, 2021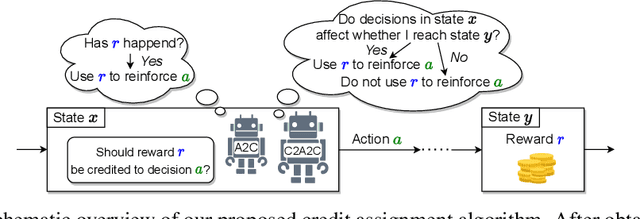
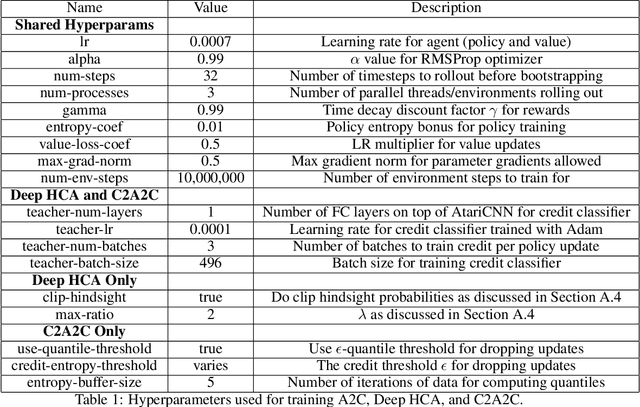
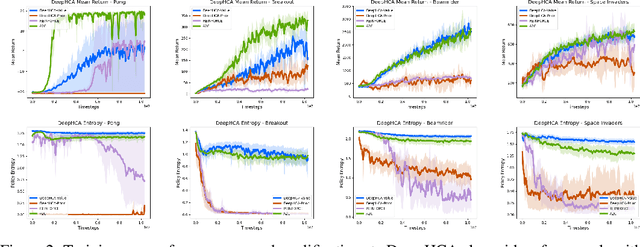
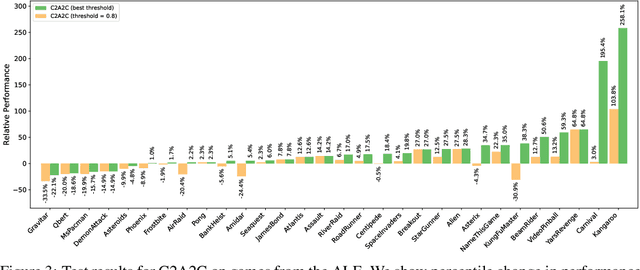
Credit assignment is a fundamental problem in reinforcement learning, the problem of measuring an action's influence on future rewards. Improvements in credit assignment methods have the potential to boost the performance of RL algorithms on many tasks, but thus far have not seen widespread adoption. Recently, a family of methods called Hindsight Credit Assignment (HCA) was proposed, which explicitly assign credit to actions in hindsight based on the probability of the action having led to an observed outcome. This approach is appealing as a means to more efficient data usage, but remains a largely theoretical idea applicable to a limited set of tabular RL tasks, and it is unclear how to extend HCA to Deep RL environments. In this work, we explore the use of HCA-style credit in a deep RL context. We first describe the limitations of existing HCA algorithms in deep RL, then propose several theoretically-justified modifications to overcome them. Based on this exploration, we present a new algorithm, Credit-Constrained Advantage Actor-Critic (C2A2C), which ignores policy updates for actions which don't affect future outcomes based on credit in hindsight, while updating the policy as normal for those that do. We find that C2A2C outperforms Advantage Actor-Critic (A2C) on the Arcade Learning Environment (ALE) benchmark, showing broad improvements over A2C and motivating further work on credit-constrained update rules for deep RL methods.
On Power Laws in Deep Ensembles
Jul 16, 2020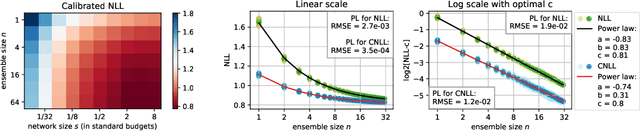

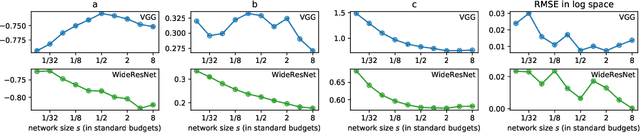

Ensembles of deep neural networks are known to achieve state-of-the-art performance in uncertainty estimation and lead to accuracy improvement. In this work, we focus on a classification problem and investigate the behavior of both non-calibrated and calibrated negative log-likelihood (CNLL) of a deep ensemble as a function of the ensemble size and the member network size. We indicate the conditions under which CNLL follows a power law w.r.t. ensemble size or member network size, and analyze the dynamics of the parameters of the discovered power laws. Our important practical finding is that one large network may perform worse than an ensemble of several medium-size networks with the same total number of parameters (we call this ensemble a memory split). Using the detected power law-like dependencies, we can predict (1) the possible gain from the ensembling of networks with given structure, (2) the optimal memory split given a memory budget, based on a relatively small number of trained networks. We describe the memory split advantage effect in more details in arXiv:2005.07292
Involutive MCMC: a Unifying Framework
Jun 30, 2020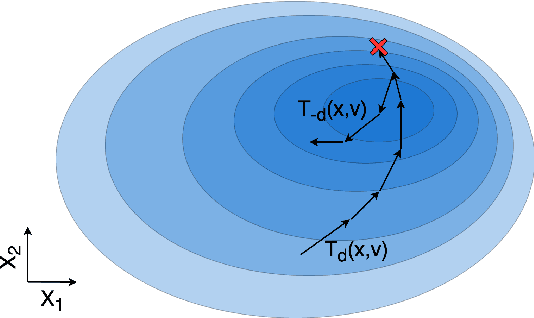
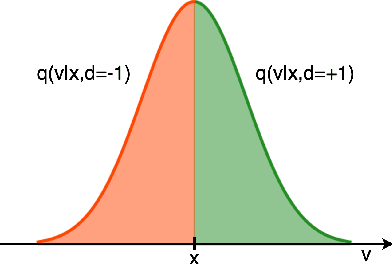

Markov Chain Monte Carlo (MCMC) is a computational approach to fundamental problems such as inference, integration, optimization, and simulation. The field has developed a broad spectrum of algorithms, varying in the way they are motivated, the way they are applied and how efficiently they sample. Despite all the differences, many of them share the same core principle, which we unify as the Involutive MCMC (iMCMC) framework. Building upon this, we describe a wide range of MCMC algorithms in terms of iMCMC, and formulate a number of "tricks" which one can use as design principles for developing new MCMC algorithms. Thus, iMCMC provides a unified view of many known MCMC algorithms, which facilitates the derivation of powerful extensions. We demonstrate the latter with two examples where we transform known reversible MCMC algorithms into more efficient irreversible ones.
MARS: Masked Automatic Ranks Selection in Tensor Decompositions
Jun 18, 2020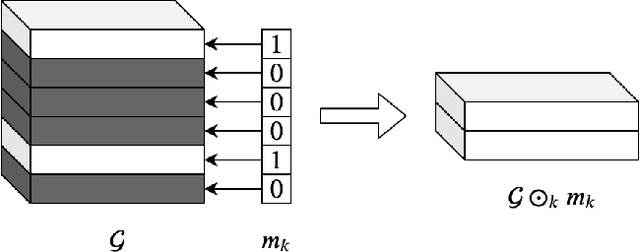

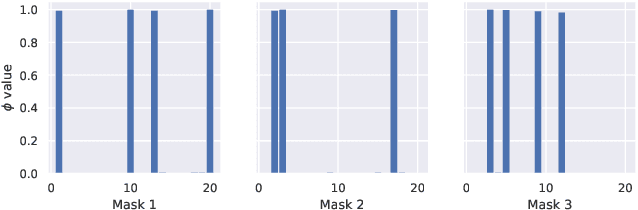

Tensor decomposition methods have recently proven to be efficient for compressing and accelerating neural networks. However, the problem of optimal decomposition structure determination is still not well studied while being quite important. Specifically, decomposition ranks present the crucial parameter controlling the compression-accuracy trade-off. In this paper, we introduce MARS -- a new efficient method for the automatic selection of ranks in general tensor decompositions. During training, the procedure learns binary masks over decomposition cores that "select" the optimal tensor structure. The learning is performed via relaxed maximum a posteriori (MAP) estimation in a specific Bayesian model. The proposed method achieves better results compared to previous works in various tasks.