 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Selection for Anomaly Detection
Jul 12, 2017Anomaly detection based on one-class classification algorithms is broadly used in many applied domains like image processing (e.g. detection of whether a patient is "cancerous" or "healthy" from mammography image), network intrusion detection, etc. Performance of an anomaly detection algorithm crucially depends on a kernel, used to measure similarity in a feature space. The standard approaches (e.g. cross-validation) for kernel selection, used in two-class classification problems, can not be used directly due to the specific nature of a data (absence of a second, abnormal, class data). In this paper we generalize several kernel selection methods from binary-class case to the case of one-class classification and perform extensive comparison of these approaches using both synthetic and real-world data.
* 6 pages, 3 figures, Eighth International Conference on Machine Vision (December 8, 2015)
One-Class SVM with Privileged Information and its Application to Malware Detection
Nov 20, 2016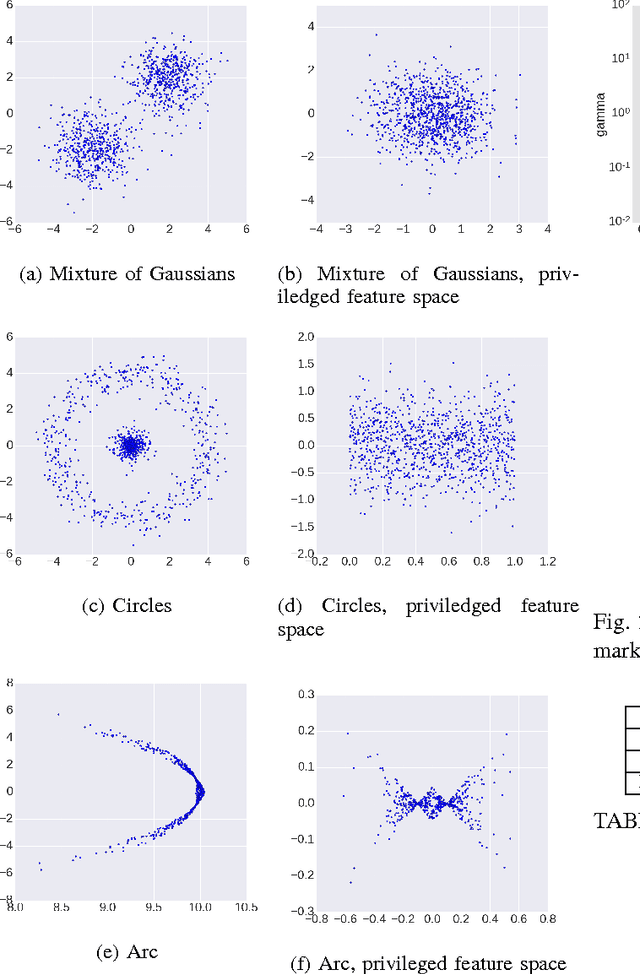
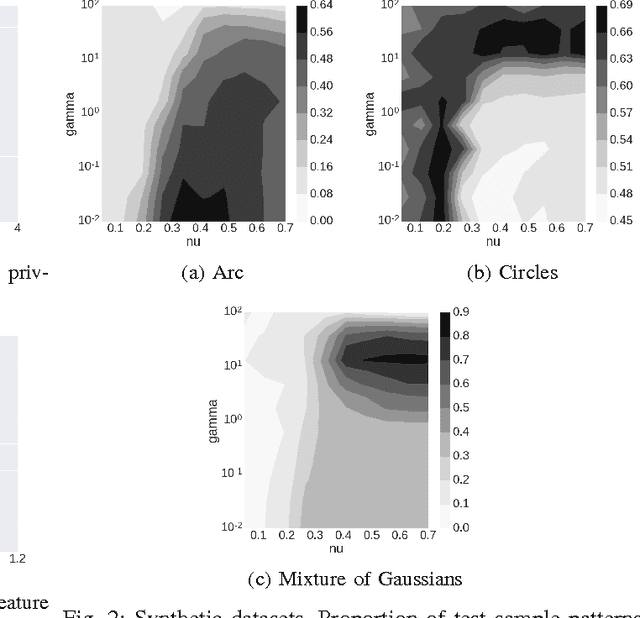
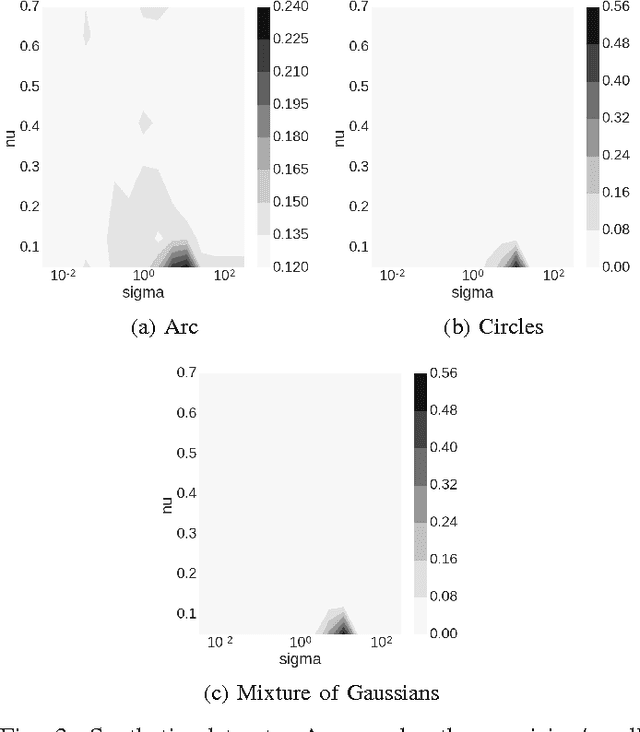
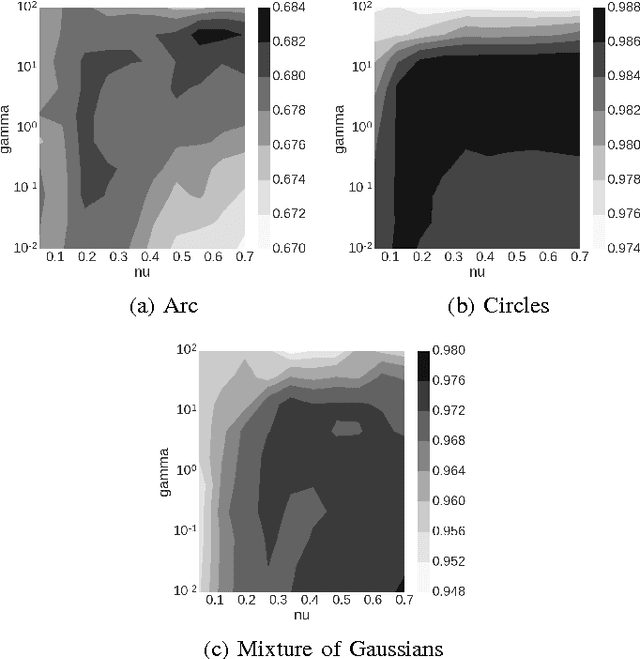
A number of important applied problems in engineering, finance and medicine can be formulated as a problem of anomaly detection. A classical approach to the problem is to describe a normal state using a one-class support vector machine. Then to detect anomalies we quantify a distance from a new observation to the constructed description of the normal class. In this paper we present a new approach to the one-class classification. We formulate a new problem statement and a corresponding algorithm that allow taking into account a privileged information during the training phase. We evaluate performance of the proposed approach using a synthetic dataset, as well as the publicly available Microsoft Malware Classification Challenge dataset.