 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Querying Over Relational Databases and Large Language Models
Aug 01, 2024



Database queries traditionally operate under the closed-world assumption, providing no answers to questions that require information beyond the data stored in the database. Hybrid querying using SQL offers an alternative by integrating relational databases with large language models (LLMs) to answer beyond-database questions. In this paper, we present the first cross-domain benchmark, SWAN, containing 120 beyond-database questions over four real-world databases. To leverage state-of-the-art language models in addressing these complex questions in SWAN, we present, HQDL, a preliminary solution for hybrid querying, and also discuss potential future directions. Our evaluation demonstrates that HQDL using GPT-4 Turbo with few-shot prompts, achieves 40.0\% in execution accuracy and 48.2\% in data factuality. These results highlights both the potential and challenges for hybrid querying. We believe that our work will inspire further research in creating more efficient and accurate data systems that seamlessly integrate relational databases and large language models to address beyond-database questions.
LLM-SQL-Solver: Can LLMs Determine SQL Equivalence?
Dec 16, 2023



Judging the equivalence between two SQL queries is a fundamental problem with many practical applications in data management and SQL generation (i.e., evaluating the quality of generated SQL queries in text-to-SQL task). While the research community has reasoned about SQL equivalence for decades, it poses considerable difficulties and no complete solutions exist. Recently, Large Language Models (LLMs) have shown strong reasoning capability in conversation, question answering and solving mathematics challenges. In this paper, we study if LLMs can be used to determine the equivalence between SQL queries under two notions of SQL equivalence (semantic equivalence and relaxed equivalence). To assist LLMs in generating high quality responses, we present two prompting techniques: Miniature & Mull and Explain & Compare. The former technique is used to evaluate the semantic equivalence in which it asks LLMs to execute a query on a simple database instance and then explore if a counterexample exists by modifying the database. The latter technique is used to evaluate the relaxed equivalence in which it asks LLMs to explain the queries and then compare if they contain significant logical differences. Our experiments demonstrate using our techniques, LLMs is a promising tool to help data engineers in writing semantically equivalent SQL queries, however challenges still persist, and is a better metric for evaluating SQL generation than the popular execution accuracy.
Autumn: A Scalable Read Optimized LSM-tree based Key-Value Stores with Fast Point and Range Read Speed
May 08, 2023The Log Structured Merge Trees (LSM-tree) based key-value stores are widely used in many storage systems to support a variety of operations such as updates, point reads, and range reads. Traditionally, LSM-tree's merge policy organizes data into multiple levels of exponentially increasing capacity to support high-speed writes. However, we contend that the traditional merge policies are not optimized for reads. In this work, we present Autumn, a scalable and read optimized LSM-tree based key-value stores with minimal point and range read cost. The key idea in improving the read performance is to dynamically adjust the capacity ratio between two adjacent levels as more data are stored. As a result, smaller levels gradually increase their capacities and merge more often. In particular, the point and range read cost improves from the previous best known $O(logN)$ complexity to $O(\sqrt{logN})$ in Autumn by applying the new novel Garnering merge policy. While Garnering merge policy optimizes for both point reads and range reads, it maintains high performance for updates. Moreover, to further improve the update costs, Autumn uses a small amount of bounded space of DRAM to pin/keep the first level of LSM-tree. We implemented Autumn on top of LevelDB and experimentally showcases the gain in performance for real world workloads.
Parameter Database : Data-centric Synchronization for Scalable Machine Learning
Aug 04, 2015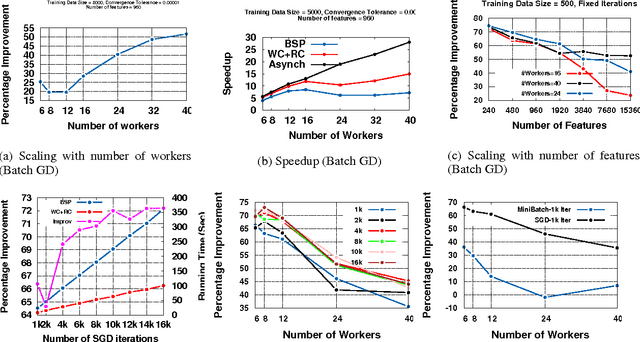
We propose a new data-centric synchronization framework for carrying out of machine learning (ML) tasks in a distributed environment. Our framework exploits the iterative nature of ML algorithms and relaxes the application agnostic bulk synchronization parallel (BSP) paradigm that has previously been used for distributed machine learning. Data-centric synchronization complements function-centric synchronization based on using stale updates to increase the throughput of distributed ML computations. Experiments to validate our framework suggest that we can attain substantial improvement over BSP while guaranteeing sequential correctness of ML tasks.