 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarially Robust Generalization Requires More Data
May 02, 2018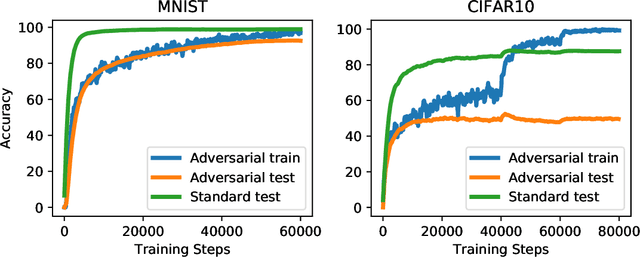
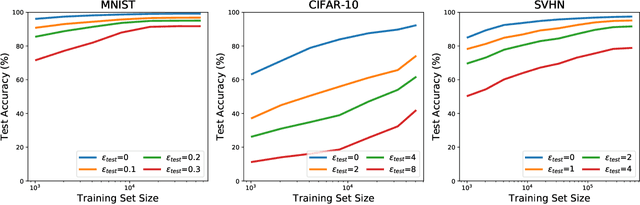
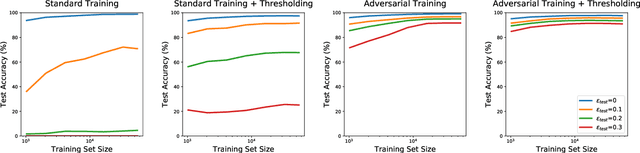
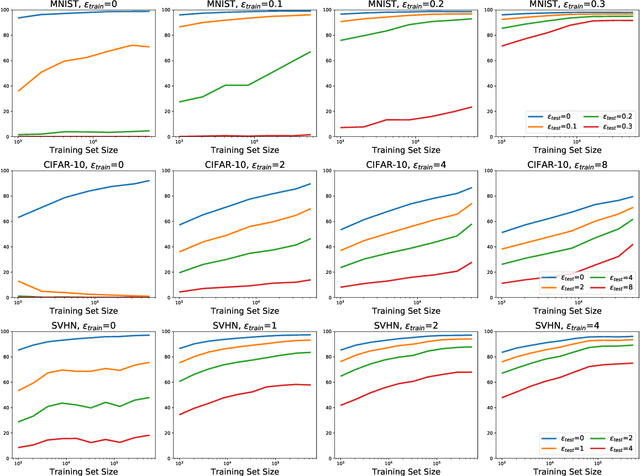
Machine learning models are often susceptible to adversarial perturbations of their inputs. Even small perturbations can cause state-of-the-art classifiers with high "standard" accuracy to produce an incorrect prediction with high confidence. To better understand this phenomenon, we study adversarially robust learning from the viewpoint of generalization. We show that already in a simple natural data model, the sample complexity of robust learning can be significantly larger than that of "standard" learning. This gap is information theoretic and holds irrespective of the training algorithm or the model family. We complement our theoretical results with experiments on popular image classification datasets and show that a similar gap exists here as well. We postulate that the difficulty of training robust classifiers stems, at least partially, from this inherently larger sample complexity.
A Rotation and a Translation Suffice: Fooling CNNs with Simple Transformations
Feb 13, 2018
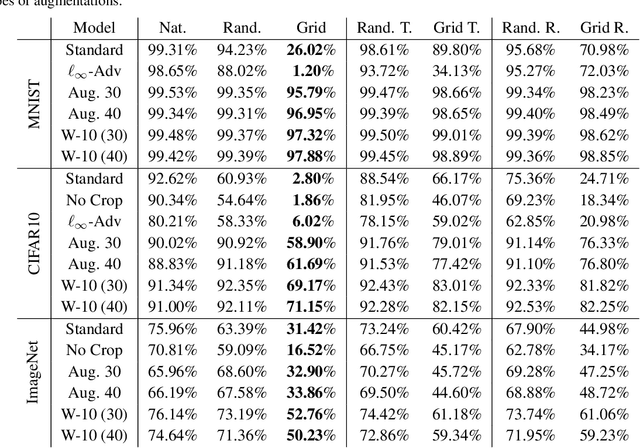
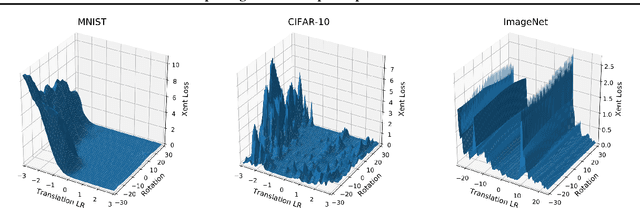
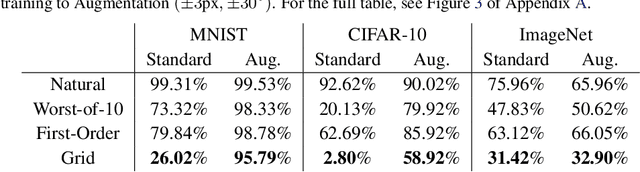
We show that simple transformations, namely translations and rotations alone, are sufficient to fool neural network-based vision models on a significant fraction of inputs. This is in sharp contrast to previous work that relied on more complicated optimization approaches that are unlikely to appear outside of a truly adversarial setting. Moreover, fooling rotations and translations are easy to find and require only a few black-box queries to the target model. Overall, our findings emphasize the need for designing robust classifiers even in natural, benign contexts.
Towards Deep Learning Models Resistant to Adversarial Attacks
Nov 09, 2017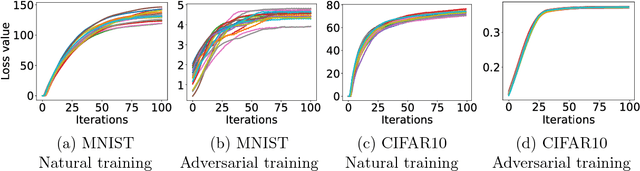
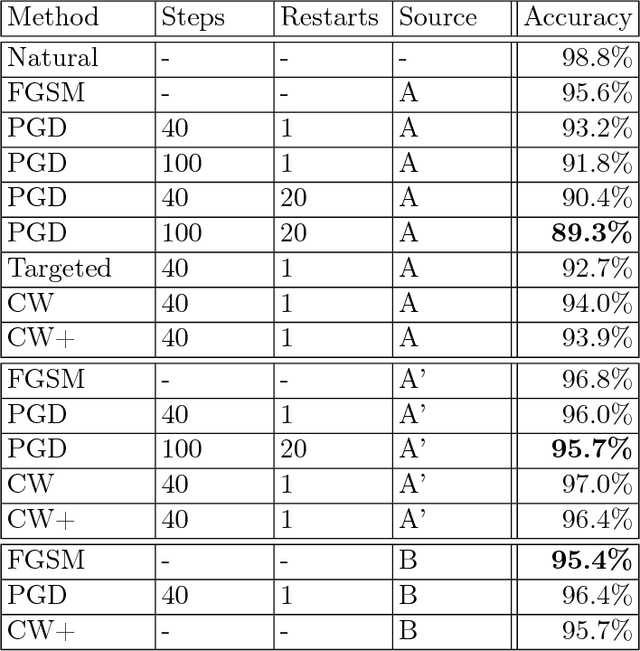
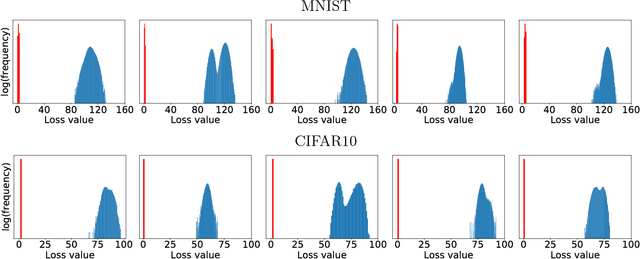
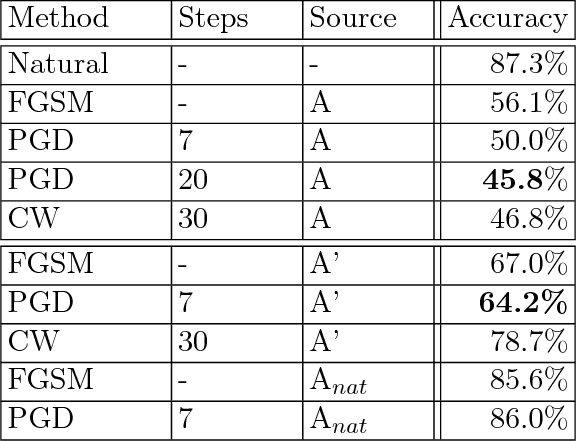
Recent work has demonstrated that neural networks are vulnerable to adversarial examples, i.e., inputs that are almost indistinguishable from natural data and yet classified incorrectly by the network. In fact, some of the latest findings suggest that the existence of adversarial attacks may be an inherent weakness of deep learning models. To address this problem, we study the adversarial robustness of neural networks through the lens of robust optimization. This approach provides us with a broad and unifying view on much of the prior work on this topic. Its principled nature also enables us to identify methods for both training and attacking neural networks that are reliable and, in a certain sense, universal. In particular, they specify a concrete security guarantee that would protect against any adversary. These methods let us train networks with significantly improved resistance to a wide range of adversarial attacks. They also suggest the notion of security against a first-order adversary as a natural and broad security guarantee. We believe that robustness against such well-defined classes of adversaries is an important stepping stone towards fully resistant deep learning models.