 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFarFetched: Entity-centric Reasoning and Claim Validation for the Greek Language based on Textually Represented Environments
Jul 13, 2024



Our collective attention span is shortened by the flood of online information. With \textit{FarFetched}, we address the need for automated claim validation based on the aggregated evidence derived from multiple online news sources. We introduce an entity-centric reasoning framework in which latent connections between events, actions, or statements are revealed via entity mentions and represented in a graph database. Using entity linking and semantic similarity, we offer a way for collecting and combining information from diverse sources in order to generate evidence relevant to the user's claim. Then, we leverage textual entailment recognition to quantitatively determine whether this assertion is credible, based on the created evidence. Our approach tries to fill the gap in automated claim validation for less-resourced languages and is showcased on the Greek language, complemented by the training of relevant semantic textual similarity (STS) and natural language inference (NLI) models that are evaluated on translated versions of common benchmarks.
INODE: Building an End-to-End Data Exploration System in Practice
Apr 09, 2021
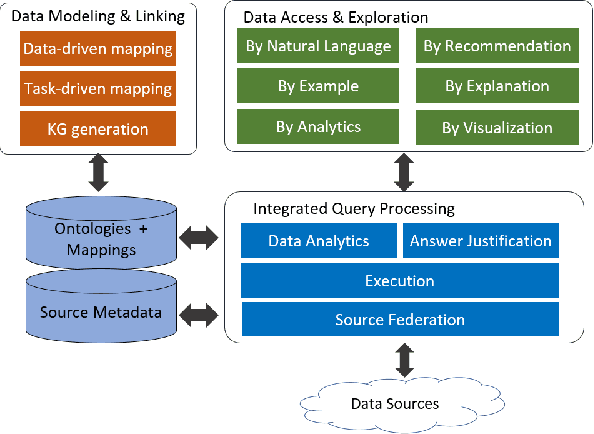

A full-fledged data exploration system must combine different access modalities with a powerful concept of guiding the user in the exploration process, by being reactive and anticipative both for data discovery and for data linking. Such systems are a real opportunity for our community to cater to users with different domain and data science expertise. We introduce INODE -- an end-to-end data exploration system -- that leverages, on the one hand, Machine Learning and, on the other hand, semantics for the purpose of Data Management (DM). Our vision is to develop a classic unified, comprehensive platform that provides extensive access to open datasets, and we demonstrate it in three significant use cases in the fields of Cancer Biomarker Reearch, Research and Innovation Policy Making, and Astrophysics. INODE offers sustainable services in (a) data modeling and linking, (b) integrated query processing using natural language, (c) guidance, and (d) data exploration through visualization, thus facilitating the user in discovering new insights. We demonstrate that our system is uniquely accessible to a wide range of users from larger scientific communities to the public. Finally, we briefly illustrate how this work paves the way for new research opportunities in DM.
PENELOPIE: Enabling Open Information Extraction for the Greek Language through Machine Translation
Mar 28, 2021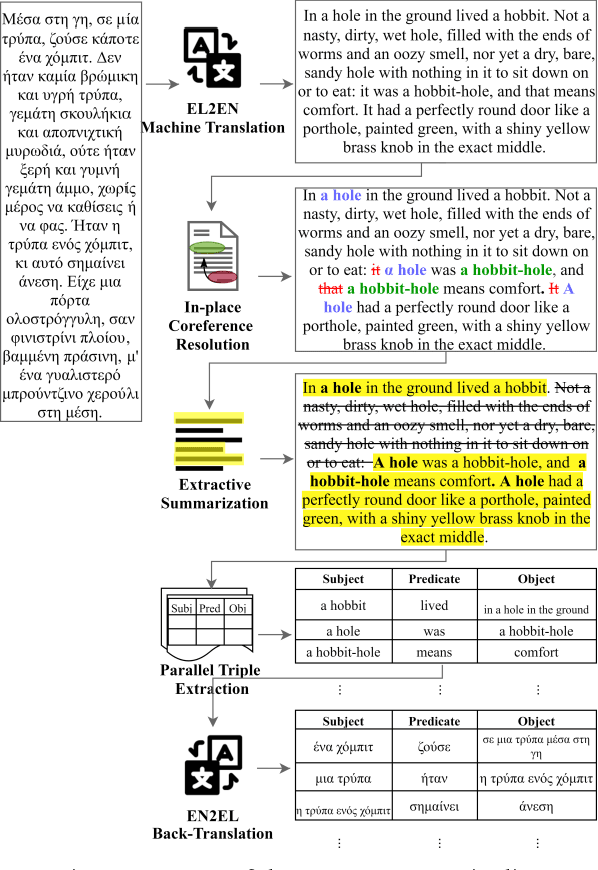
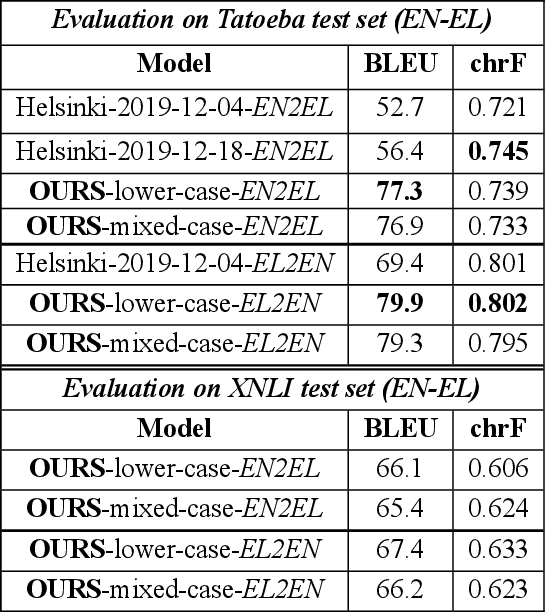
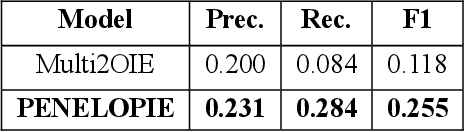
In this paper we present our submission for the EACL 2021 SRW; a methodology that aims at bridging the gap between high and low-resource languages in the context of Open Information Extraction, showcasing it on the Greek language. The goals of this paper are twofold: First, we build Neural Machine Translation (NMT) models for English-to-Greek and Greek-to-English based on the Transformer architecture. Second, we leverage these NMT models to produce English translations of Greek text as input for our NLP pipeline, to which we apply a series of pre-processing and triple extraction tasks. Finally, we back-translate the extracted triples to Greek. We conduct an evaluation of both our NMT and OIE methods on benchmark datasets and demonstrate that our approach outperforms the current state-of-the-art for the Greek natural language.