 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Objective Recommender Systems: Survey and Challenges
Oct 19, 2022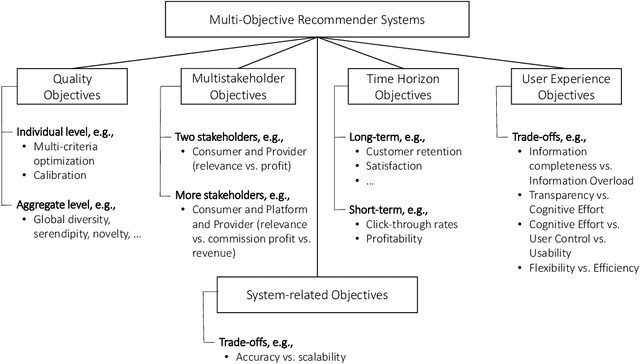
Recommender systems can be characterized as software solutions that provide users convenient access to relevant content. Traditionally, recommender systems research predominantly focuses on developing machine learning algorithms that aim to predict which content is relevant for individual users. In real-world applications, however, optimizing the accuracy of such relevance predictions as a single objective in many cases is not sufficient. Instead, multiple and often competing objectives have to be considered, leading to a need for more research in multi-objective recommender systems. We can differentiate between several types of such competing goals, including (i) competing recommendation quality objectives at the individual and aggregate level, (ii) competing objectives of different involved stakeholders, (iii) long-term vs. short-term objectives, (iv) objectives at the user interface level, and (v) system level objectives. In this paper we review these types of multi-objective recommendation settings and outline open challenges in this area.
Evaluating Conversational Recommender Systems
Aug 25, 2022Conversational recommender systems aim to interactively support online users in their information search and decision-making processes in an intuitive way. With the latest advances in voice-controlled devices, natural language processing, and AI in general, such systems received increased attention in recent years. Technically, conversational recommenders are usually complex multi-component applications and often consist of multiple machine learning models and a natural language user interface. Evaluating such a complex system in a holistic way can therefore be challenging, as it requires (i) the assessment of the quality of the different learning components, and (ii) the quality perception of the system as a whole by users. Thus, a mixed methods approach is often required, which may combine objective (computational) and subjective (perception-oriented) evaluation techniques. In this paper, we review common evaluation approaches for conversational recommender systems, identify possible limitations, and outline future directions towards more holistic evaluation practices.
INSPIRED2: An Improved Dataset for Sociable Conversational Recommendation
Aug 08, 2022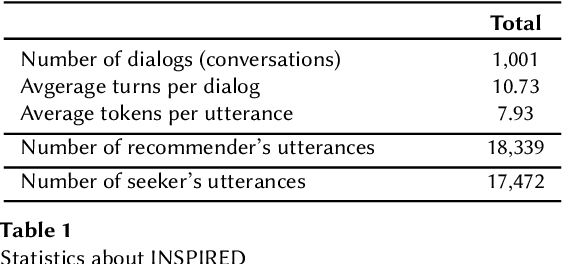
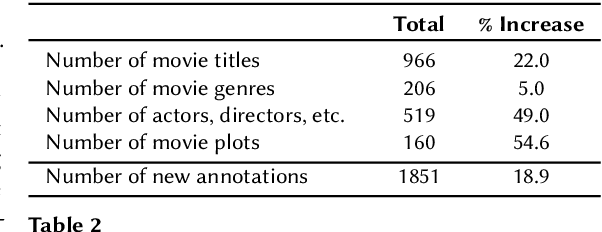
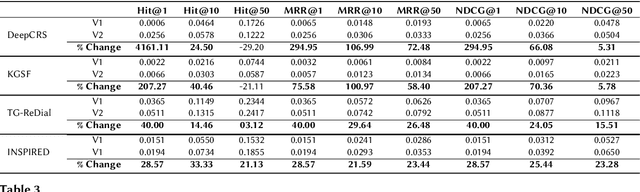
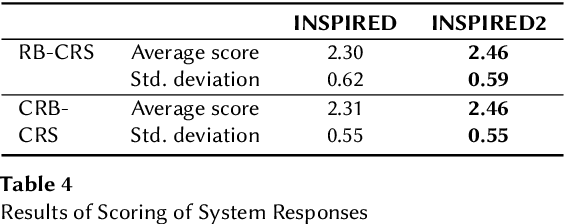
Conversational recommender systems (CRS) that interact with users in natural language utilize recommendation dialogs collected with the help of paired humans, where one plays the role of a seeker and the other as a recommender. These recommendation dialogs include items and entities to disclose seekers' preferences in natural language. However, in order to precisely model the seekers' preferences and respond consistently, mainly CRS rely on explicitly annotated items and entities that appear in the dialog, and usually leverage the domain knowledge. In this work, we investigate INSPIRED, a dataset consisting of recommendation dialogs for the sociable conversational recommendation, where items and entities were explicitly annotated using automatic keyword or pattern matching techniques. To this end, we found a large number of cases where items and entities were either wrongly annotated or missing annotations at all. The question however remains to what extent automatic techniques for annotations are effective. Moreover, it is unclear what is the relative impact of poor and improved annotations on the overall effectiveness of a CRS in terms of the consistency and quality of responses. In this regard, first, we manually fixed the annotations and removed the noise in the INSPIRED dataset. Second, we evaluate the performance of several benchmark CRS using both versions of the dataset. Our analyses suggest that with the improved version of the dataset, i.e., INSPIRED2, various benchmark CRS outperformed and that dialogs are rich in knowledge concepts compared to when the original version is used. We release our improved dataset (INSPIRED2) publicly at https://github.com/ahtsham58/INSPIRED2.
A Survey of Research on Fair Recommender Systems
May 25, 2022
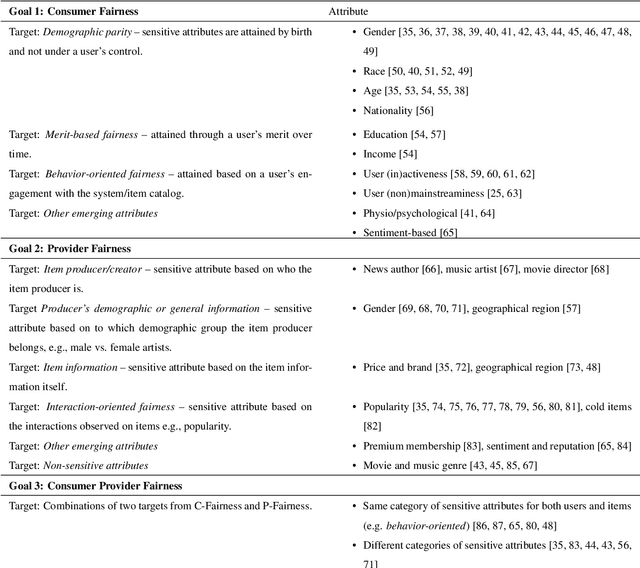
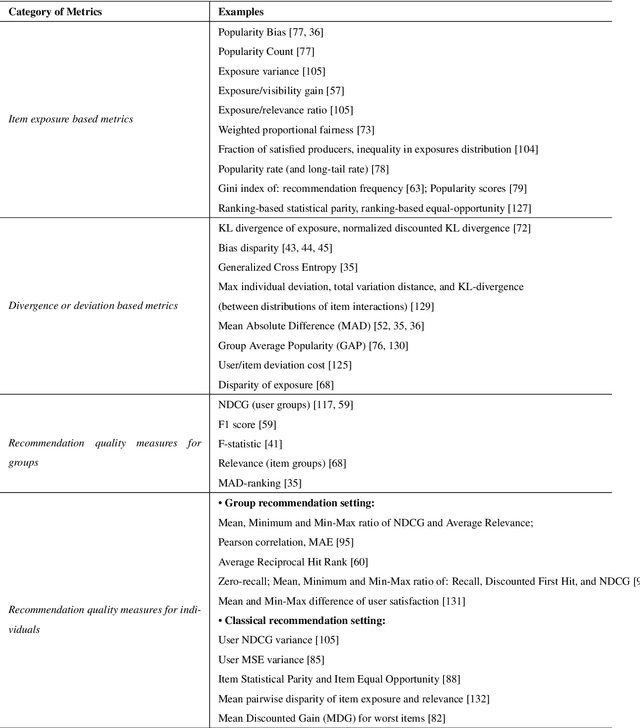
Recommender systems can strongly influence which information we see online, e.g, on social media, and thus impact our beliefs, decisions, and actions. At the same time, these systems can create substantial business value for different stakeholders. Given the growing potential impact of such AI-based systems on individuals, organizations, and society, questions of fairness have gained increased attention in recent years. However, research on fairness in recommender systems is still a developing area. In this survey, we first review the fundamental concepts and notions of fairness that were put forward in the area in the recent past. Afterward, we provide a survey of how research in this area is currently operationalized, for example, in terms of the general research methodology, fairness metrics, and algorithmic approaches. Overall, our analysis of recent works points to certain research gaps. In particular, we find that in many research works in computer science very abstract problem operationalizations are prevalent, which circumvent the fundamental and important question of what represents a fair recommendation in the context of a given application.
Conversational Recommendation: A Grand AI Challenge
Mar 17, 2022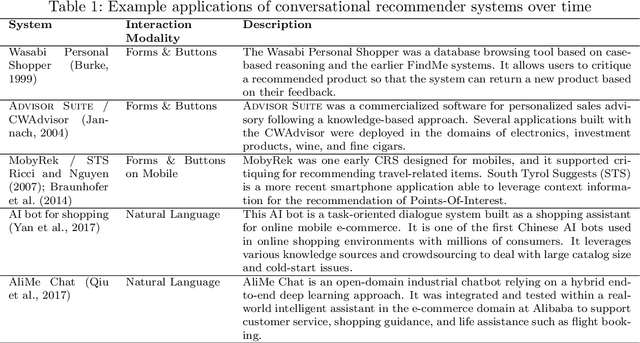
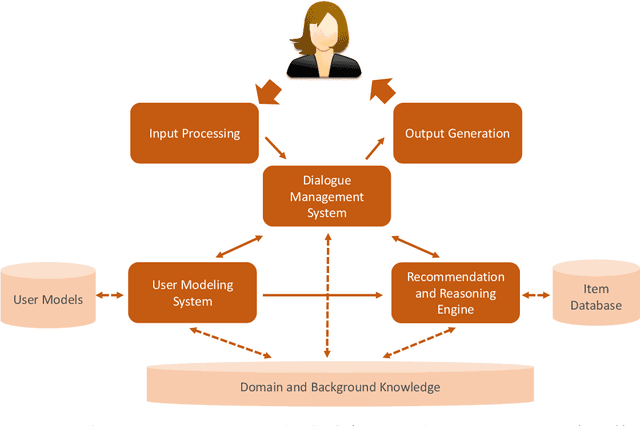
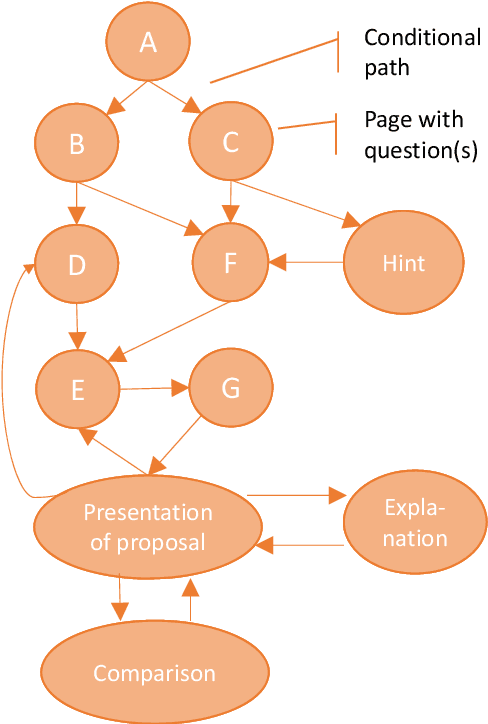
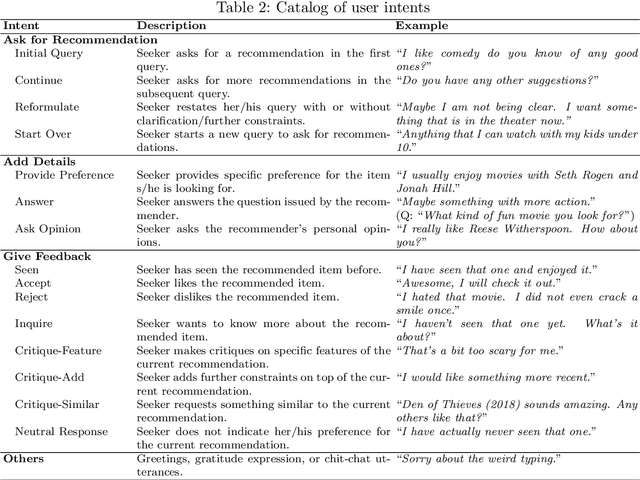
Animated avatars, which look and talk like humans, are iconic visions of the future of AI-powered systems. Through many sci-fi movies we are acquainted with the idea of speaking to such virtual personalities as if they were humans. Today, we talk more and more to machines like Apple's Siri, e.g., to ask them for the weather forecast. However, when asked for recommendations, e.g., for a restaurant to go to, the limitations of such devices quickly become obvious. They do not engage in a conversation to find out what we might prefer, they often do not provide explanations for what they recommend, and they may have difficulties remembering what was said one minute earlier. Conversational recommender systems promise to address these limitations. In this paper, we review existing approaches to build such systems, which developments we observe today, which challenges are still open and why the development of conversational recommenders represents one of the next grand challenges of AI.
Balancing Consumer and Business Value of Recommender Systems: A Simulation-based Analysis
Mar 10, 2022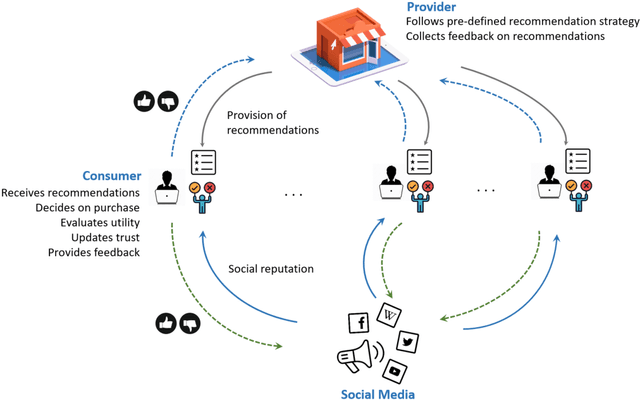

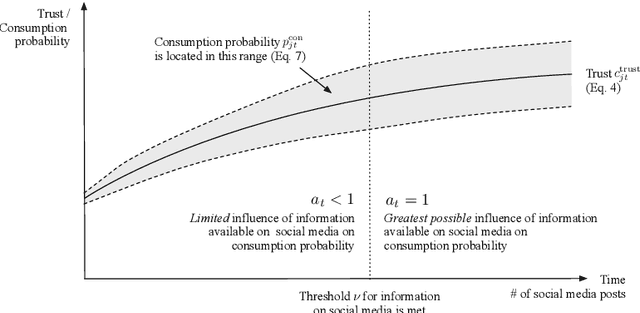
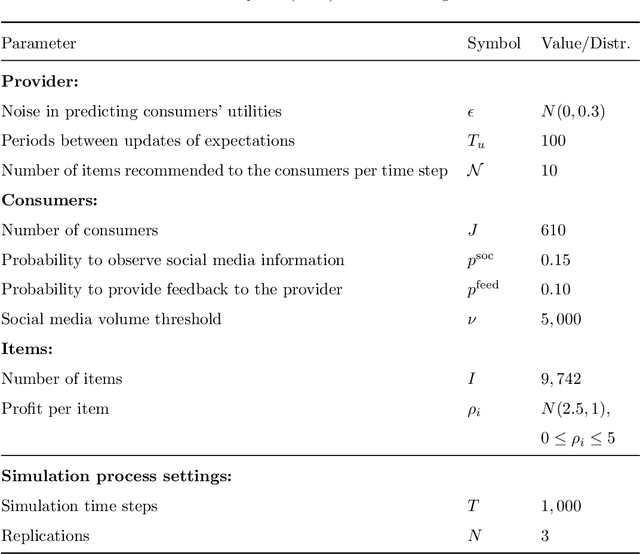
Automated recommendations can nowadays be found on many online platforms, and such recommendations can create substantial value for consumers and providers. Often, however, not all recommendable items have the same profit margin, and providers might thus be tempted to promote items that maximize their profit. In the short run, consumers might accept non-optimal recommendations, but they may lose their trust in the long run. Ultimately, this leads to the problem of designing balanced recommendation strategies, which consider both consumer and provider value and lead to sustained business success. This work proposes a simulation framework based on Agent-based Modeling designed to help providers explore longitudinal dynamics of different recommendation strategies. In our model, consumer agents receive recommendations from providers, and the perceived quality of the recommendations influences the consumers' trust over time. In addition, we consider network effects where positive and negative experiences are shared with others on social media. Simulations with our framework show that balanced strategies that consider both stakeholders indeed lead to stable consumer trust and sustained profitability. We also find that social media can reinforce phenomena like the loss of trust in the case of negative experiences. To ensure reproducibility and foster future research, we publicly share our flexible simulation framework.
Top-N Recommendation Algorithms: A Quest for the State-of-the-Art
Mar 02, 2022
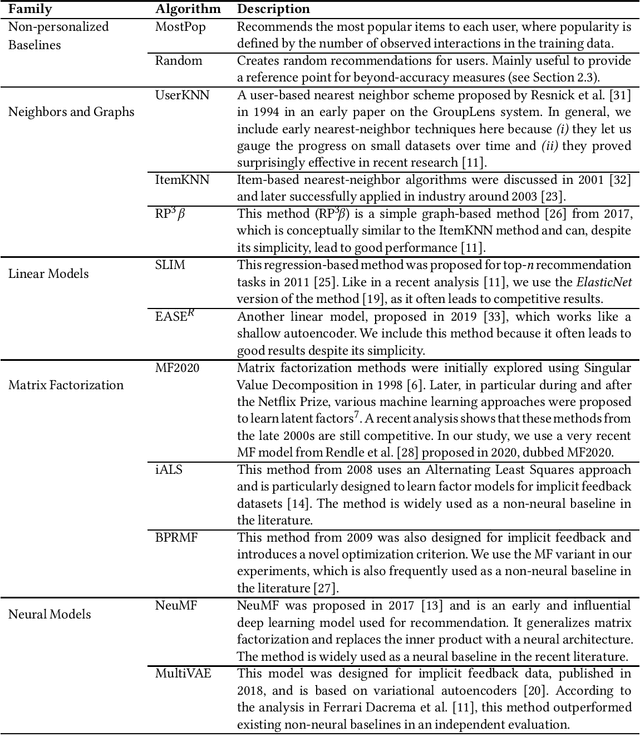
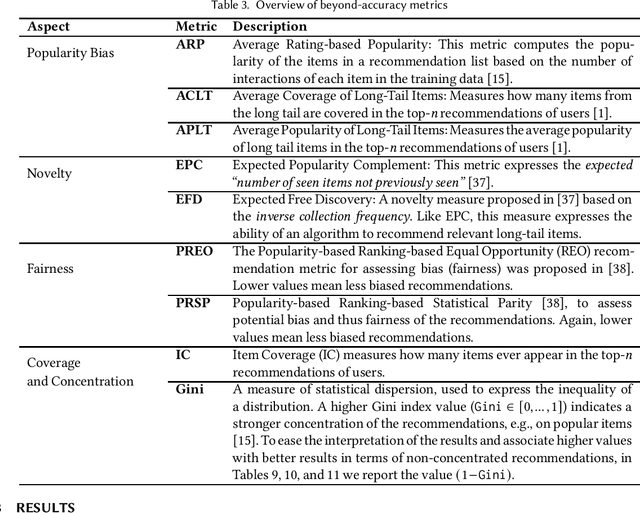
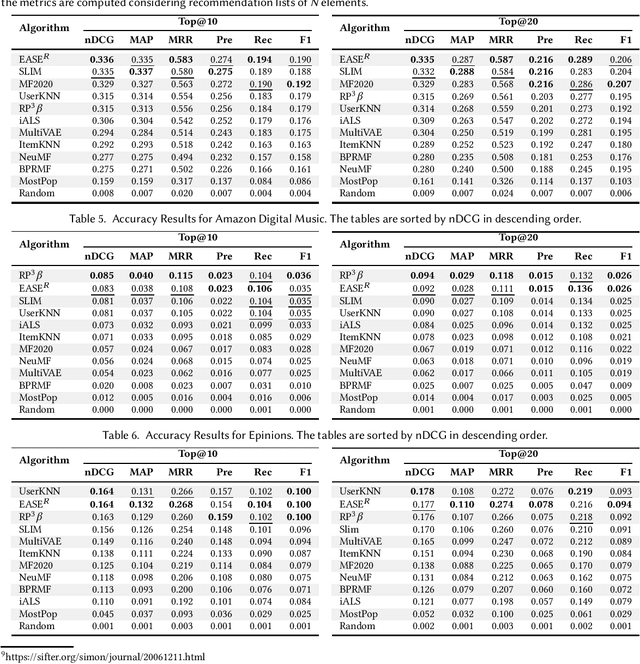
Research on recommender systems algorithms, like other areas of applied machine learning, is largely dominated by efforts to improve the state-of-the-art, typically in terms of accuracy measures. Several recent research works however indicate that the reported improvements over the years sometimes "don't add up", and that methods that were published several years ago often outperform the latest models when evaluated independently. Different factors contribute to this phenomenon, including that some researchers probably often only fine-tune their own models but not the baselines. In this paper, we report the outcomes of an in-depth, systematic, and reproducible comparison of ten collaborative filtering algorithms - covering both traditional and neural models - on several common performance measures on three datasets which are frequently used for evaluation in the recent literature. Our results show that there is no consistent winner across datasets and metrics for the examined top-n recommendation task. Moreover, we find that for none of the accuracy measurements any of the considered neural models led to the best performance. Regarding the performance ranking of algorithms across the measurements, we found that linear models, nearest-neighbor methods, and traditional matrix factorization consistently perform well for the evaluated modest-sized, but commonly-used datasets. Our work shall therefore serve as a guideline for researchers regarding existing baselines to consider in future performance comparisons. Moreover, by providing a set of fine-tuned baseline models for different datasets, we hope that our work helps to establish a common understanding of the state-of-the-art for top-n recommendation tasks.
Conversational Recommendation: Theoretical Model and Complexity Analysis
Nov 12, 2021
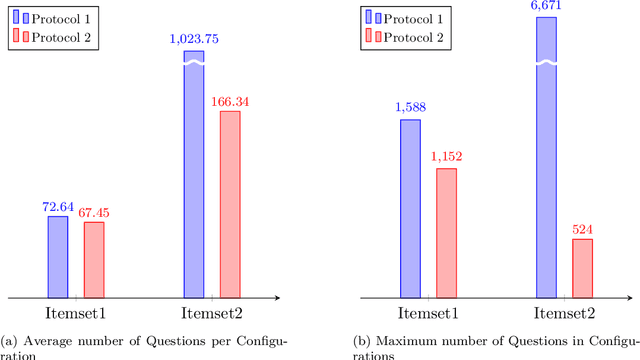


Recommender systems are software applications that help users find items of interest in situations of information overload in a personalized way, using knowledge about the needs and preferences of individual users. In conversational recommendation approaches, these needs and preferences are acquired by the system in an interactive, multi-turn dialog. A common approach in the literature to drive such dialogs is to incrementally ask users about their preferences regarding desired and undesired item features or regarding individual items. A central research goal in this context is efficiency, evaluated with respect to the number of required interactions until a satisfying item is found. This is usually accomplished by making inferences about the best next question to ask to the user. Today, research on dialog efficiency is almost entirely empirical, aiming to demonstrate, for example, that one strategy for selecting questions is better than another one in a given application. With this work, we complement empirical research with a theoretical, domain-independent model of conversational recommendation. This model, which is designed to cover a range of application scenarios, allows us to investigate the efficiency of conversational approaches in a formal way, in particular with respect to the computational complexity of devising optimal interaction strategies. Through such a theoretical analysis we show that finding an efficient conversational strategy is NP-hard, and in PSPACE in general, but for particular kinds of catalogs the upper bound lowers to POLYLOGSPACE. From a practical point of view, this result implies that catalog characteristics can strongly influence the efficiency of individual conversational strategies and should therefore be considered when designing new strategies. A preliminary empirical analysis on datasets derived from a real-world one aligns with our findings.
Towards Retrieval-based Conversational Recommendation
Sep 06, 2021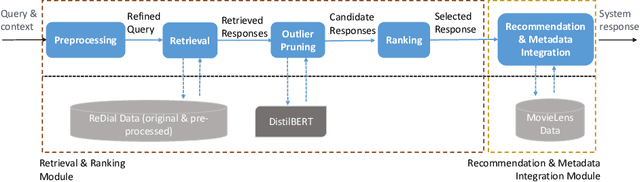

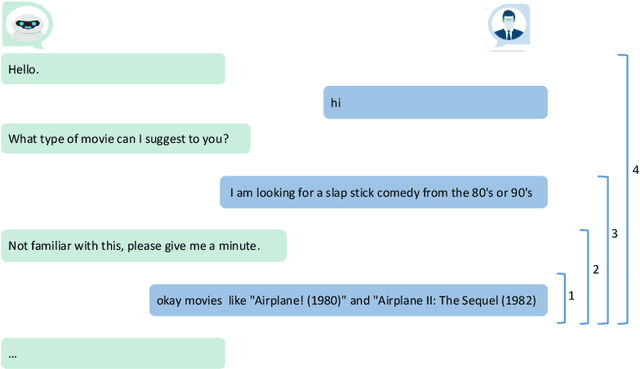
Conversational recommender systems have attracted immense attention recently. The most recent approaches rely on neural models trained on recorded dialogs between humans, implementing an end-to-end learning process. These systems are commonly designed to generate responses given the user's utterances in natural language. One main challenge is that these generated responses both have to be appropriate for the given dialog context and must be grammatically and semantically correct. An alternative to such generation-based approaches is to retrieve responses from pre-recorded dialog data and to adapt them if needed. Such retrieval-based approaches were successfully explored in the context of general conversational systems, but have received limited attention in recent years for CRS. In this work, we re-assess the potential of such approaches and design and evaluate a novel technique for response retrieval and ranking. A user study (N=90) revealed that the responses by our system were on average of higher quality than those of two recent generation-based systems. We furthermore found that the quality ranking of the two generation-based approaches is not aligned with the results from the literature, which points to open methodological questions. Overall, our research underlines that retrieval-based approaches should be considered an alternative or complement to language generation approaches.
Understanding Longitudinal Dynamics of Recommender Systems with Agent-Based Modeling and Simulation
Aug 25, 2021Today's research in recommender systems is largely based on experimental designs that are static in a sense that they do not consider potential longitudinal effects of providing recommendations to users. In reality, however, various important and interesting phenomena only emerge or become visible over time, e.g., when a recommender system continuously reinforces the popularity of already successful artists on a music streaming site or when recommendations that aim at profit maximization lead to a loss of consumer trust in the long run. In this paper, we discuss how Agent-Based Modeling and Simulation (ABM) techniques can be used to study such important longitudinal dynamics of recommender systems. To that purpose, we provide an overview of the ABM principles, outline a simulation framework for recommender systems based on the literature, and discuss various practical research questions that can be addressed with such an ABM-based simulation framework.