 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpherical-to-ERP Epipolar Rectification for Single-Axis Disparity in 360 Stereo
Jun 23, 2026Omnidirectional stereo images provide full-surround perception but violate the geometric assumptions of classical disparity estimation: in spherical or fisheye views, epipolar correspondences follow curved great-circle paths, producing two-dimensional displacements that cannot be treated as single-axis disparity before geometric rectification. In this work, we adopt a standard spherical-to-equirectangular (ERP) projection as a preprocessing step, which straightens epipolar curves and restores a one-dimensional disparity structure - horizontal for left-right rigs and vertical for top-bottom rigs. Building on our previously introduced RAFT + Epipolar-Aligned Channel Selection (EACS) framework, originally developed for rectilinear and ERP stereo, we examine whether the same modular pipeline remains accurate when the input originates from spherical stereo imagery. After ERP projection, dense optical flow from RAFT is reduced to disparity by retaining only the baseline-aligned flow component. Experiments on synthetic fisheye stereo datasets show that this spherical-to-ERP-to-RAFT+EACS pipeline produces accurate, smooth, and structurally consistent disparity maps at real-time speed. These findings confirm that established ERP preprocessing can be effectively combined with our earlier RAFT+EACS method to enable practical, interpretable, and efficient disparity estimation from spherical stereo, providing a straightforward pathway for extending conventional stereo pipelines to 360 imaging.
* 7 Pages, 4 Figures, Conference
Systematic Evaluation of Synthetic Data Augmentation for Multi-class NetFlow Traffic
Aug 28, 2024



The detection of cyber-attacks in computer networks is a crucial and ongoing research challenge. Machine learning-based attack classification offers a promising solution, as these models can be continuously updated with new data, enhancing the effectiveness of network intrusion detection systems (NIDS). Unlike binary classification models that simply indicate the presence of an attack, multi-class models can identify specific types of attacks, allowing for more targeted and effective incident responses. However, a significant drawback of these classification models is their sensitivity to imbalanced training data. Recent advances suggest that generative models can assist in data augmentation, claiming to offer superior solutions for imbalanced datasets. Classical balancing methods, although less novel, also provide potential remedies for this issue. Despite these claims, a comprehensive comparison of these methods within the NIDS domain is lacking. Most existing studies focus narrowly on individual methods, making it difficult to compare results due to varying experimental setups. To close this gap, we designed a systematic framework to compare classical and generative resampling methods for class balancing across multiple popular classification models in the NIDS domain, evaluated on several NIDS benchmark datasets. Our experiments indicate that resampling methods for balancing training data do not reliably improve classification performance. Although some instances show performance improvements, the majority of results indicate decreased performance, with no consistent trend in favor of a specific resampling technique enhancing a particular classifier.
Flow-based Network Traffic Generation using Generative Adversarial Networks
Sep 27, 2018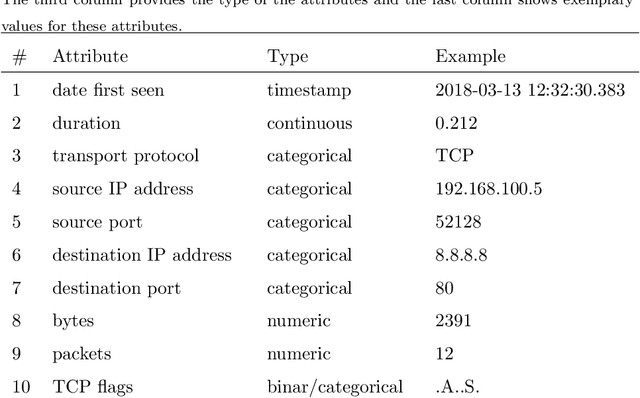
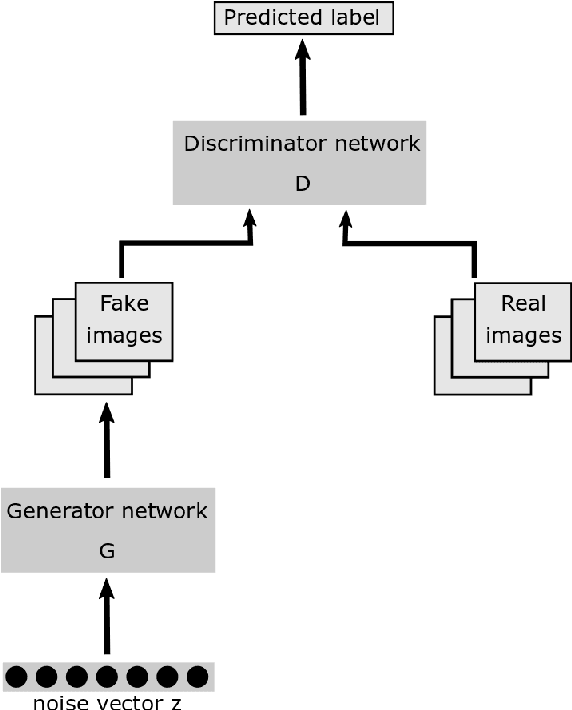
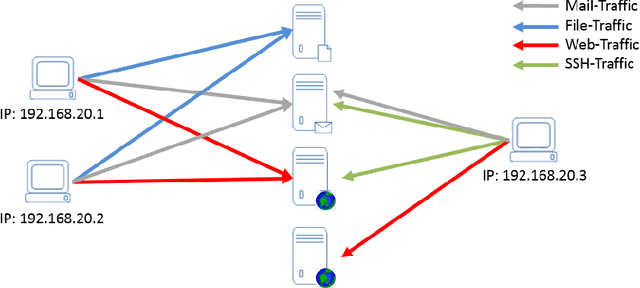
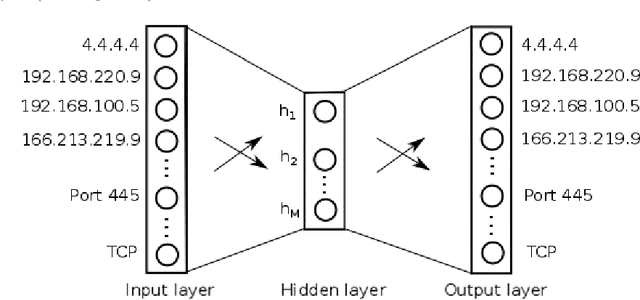
Flow-based data sets are necessary for evaluating network-based intrusion detection systems (NIDS). In this work, we propose a novel methodology for generating realistic flow-based network traffic. Our approach is based on Generative Adversarial Networks (GANs) which achieve good results for image generation. A major challenge lies in the fact that GANs can only process continuous attributes. However, flow-based data inevitably contain categorical attributes such as IP addresses or port numbers. Therefore, we propose three different preprocessing approaches for flow-based data in order to transform them into continuous values. Further, we present a new method for evaluating the generated flow-based network traffic which uses domain knowledge to define quality tests. We use the three approaches for generating flow-based network traffic based on the CIDDS-001 data set. Experiments indicate that two of the three approaches are able to generate high quality data.