 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAxis Decomposition for ODRL: Resolving Dimensional Ambiguity in Policy Constraints through Interval Semantics
Feb 24, 2026Every ODRL 2.2 constraint compares a single scalar value: (leftOperand, operator, rightOperand). Five of ODRL's left operands, however, denote multi-dimensional quantities--image dimensions, canvas positions, geographic coordinates--whose specification text explicitly references multiple axes. For these operands, a single scalar constraint admits one interpretation per axis, making policy evaluation non-deterministic. We classify ODRL's left operands by value-domain structure (scalar, dimensional, concept-valued), grounded in the ODRL 2.2 specification text, and show that dimensional ambiguity is intrinsic to the constraint syntax. We present an axis-decomposition framework that refines each dimensional operand into axis-specific scalar operands and prove four properties: deterministic interpretation, AABB completeness, projection soundness, and conservative extension. Conflict detection operates in two layers: per-axis verdicts are always decidable; box-level verdicts compose through Strong Kleene conjunction into a three-valued logic (Conflict, Compatible, Unknown). For ODRL's disjunctive (odrl:or) and exclusive-or (odrl:xone) logical constraints, where per-axis decomposition does not apply, the framework encodes coupled multi-axis conjectures directly. We instantiate the framework as the ODRL Spatial Axis Profile--15 axis-specific left operands for the five affected base terms--and evaluate it on 117 benchmark problems spanning nine categories across both TPTP FOF (Vampire) and SMT-LIB (Z3) encodings, achieving full concordance between provers. Benchmark scenarios are inspired by constraints arising in cultural heritage dataspaces such as Datenraum Kultur. All meta-theorems are mechanically verified in Isabelle/HOL.
Denotational Semantics for ODRL: Knowledge-Based Constraint Conflict Detection
Feb 23, 2026ODRL's six set-based operators -- isA, isPartOf, hasPart, isAnyOf, isAllOf, isNoneOf -- depend on external domain knowledge that the W3C specification leaves unspecified. Without it, every cross-dataspace policy comparison defaults to Unknown. We present a denotational semantics that maps each ODRL constraint to the set of knowledge-base concepts satisfying it. Conflict detection reduces to denotation intersection under a three-valued verdict -- Conflict, Compatible, or Unknown -- that is sound under incomplete knowledge. The framework covers all three ODRL composition modes (and, or, xone) and all three semantic domains arising in practice: taxonomic (class subsumption), mereological (part-whole containment), and nominal (identity). For cross-dataspace interoperability, we define order-preserving alignments between knowledge bases and prove two guarantees: conflicts are preserved across different KB standards, and unmapped concepts degrade gracefully to Unknown -- never to false conflicts. A runtime soundness theorem ensures that design-time verdicts hold for all execution contexts. The encoding stays within the decidable EPR fragment of first-order logic. We validate it with 154 benchmarks across six knowledge base families (GeoNames, ISO 3166, W3C DPV, a GDPR-derived taxonomy, BCP 47, and ISO 639-3) and four structural KBs targeting adversarial edge cases. Both the Vampire theorem prover and the Z3 SMT solver agree on all 154 verdicts. A key finding is that exclusive composition (xone) requires strictly stronger KB axioms than conjunction or disjunction: open-world semantics blocks exclusivity even when positive evidence appears to satisfy exactly one branch.
Towards Enabling FAIR Dataspaces Using Large Language Models
Mar 18, 2024Dataspaces have recently gained adoption across various sectors, including traditionally less digitized domains such as culture. Leveraging Semantic Web technologies helps to make dataspaces FAIR, but their complexity poses a significant challenge to the adoption of dataspaces and increases their cost. The advent of Large Language Models (LLMs) raises the question of how these models can support the adoption of FAIR dataspaces. In this work, we demonstrate the potential of LLMs in dataspaces with a concrete example. We also derive a research agenda for exploring this emerging field.
Unveiling Relations in the Industry 4.0 Standards Landscape based on Knowledge Graph Embeddings
Jun 03, 2020
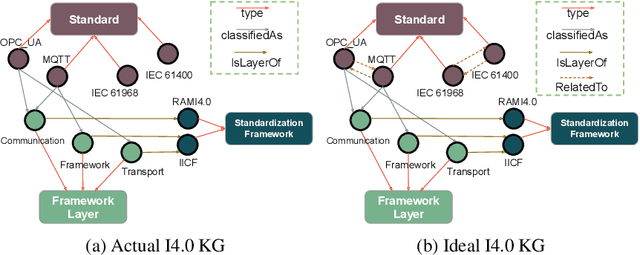
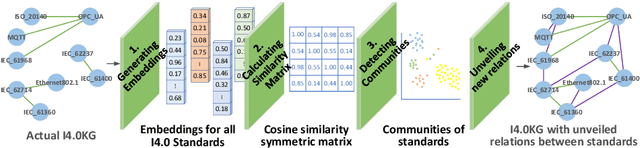
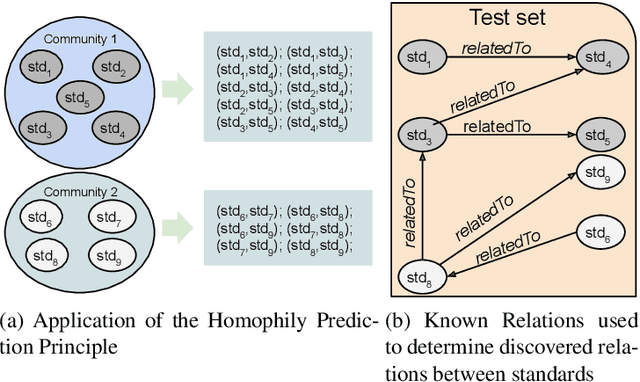
Industry~4.0 (I4.0) standards and standardization frameworks have been proposed with the goal of \emph{empowering interoperability} in smart factories. These standards enable the description and interaction of the main components, systems, and processes inside of a smart factory. Due to the growing number of frameworks and standards, there is an increasing need for approaches that automatically analyze the landscape of I4.0 standards. Standardization frameworks classify standards according to their functions into layers and dimensions. However, similar standards can be classified differently across the frameworks, producing, thus, interoperability conflicts among them. Semantic-based approaches that rely on ontologies and knowledge graphs, have been proposed to represent standards, known relations among them, as well as their classification according to existing frameworks. Albeit informative, the structured modeling of the I4.0 landscape only provides the foundations for detecting interoperability issues. Thus, graph-based analytical methods able to exploit knowledge encoded by these approaches, are required to uncover alignments among standards. We study the relatedness among standards and frameworks based on community analysis to discover knowledge that helps to cope with interoperability conflicts between standards. We use knowledge graph embeddings to automatically create these communities exploiting the meaning of the existing relationships. In particular, we focus on the identification of similar standards, i.e., communities of standards, and analyze their properties to detect unknown relations. We empirically evaluate our approach on a knowledge graph of I4.0 standards using the Trans$^*$ family of embedding models for knowledge graph entities. Our results are promising and suggest that relations among standards can be detected accurately.