 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed Precision Training of Convolutional Neural Networks using Integer Operations
Feb 23, 2018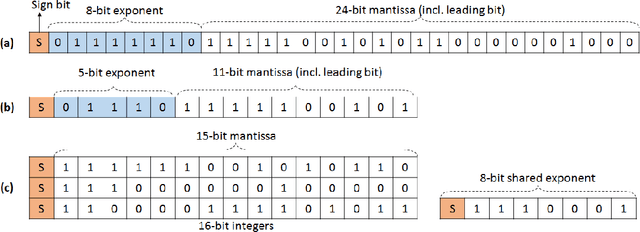
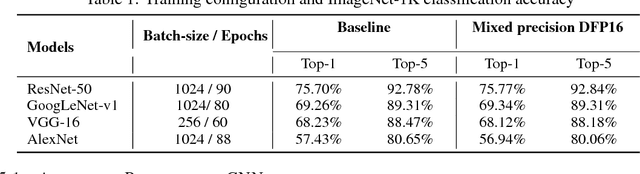
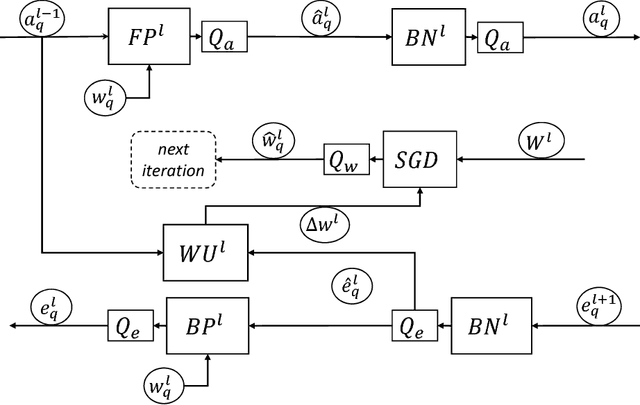
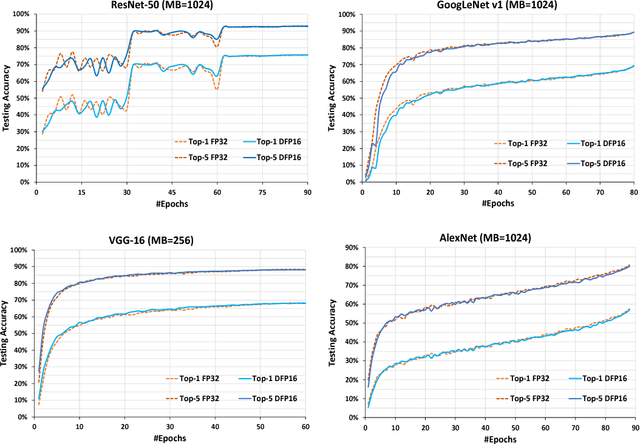
The state-of-the-art (SOTA) for mixed precision training is dominated by variants of low precision floating point operations, and in particular, FP16 accumulating into FP32 Micikevicius et al. (2017). On the other hand, while a lot of research has also happened in the domain of low and mixed-precision Integer training, these works either present results for non-SOTA networks (for instance only AlexNet for ImageNet-1K), or relatively small datasets (like CIFAR-10). In this work, we train state-of-the-art visual understanding neural networks on the ImageNet-1K dataset, with Integer operations on General Purpose (GP) hardware. In particular, we focus on Integer Fused-Multiply-and-Accumulate (FMA) operations which take two pairs of INT16 operands and accumulate results into an INT32 output.We propose a shared exponent representation of tensors and develop a Dynamic Fixed Point (DFP) scheme suitable for common neural network operations. The nuances of developing an efficient integer convolution kernel is examined, including methods to handle overflow of the INT32 accumulator. We implement CNN training for ResNet-50, GoogLeNet-v1, VGG-16 and AlexNet; and these networks achieve or exceed SOTA accuracy within the same number of iterations as their FP32 counterparts without any change in hyper-parameters and with a 1.8X improvement in end-to-end training throughput. To the best of our knowledge these results represent the first INT16 training results on GP hardware for ImageNet-1K dataset using SOTA CNNs and achieve highest reported accuracy using half-precision
On Scale-out Deep Learning Training for Cloud and HPC
Jan 24, 2018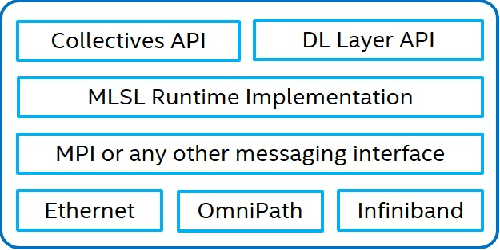
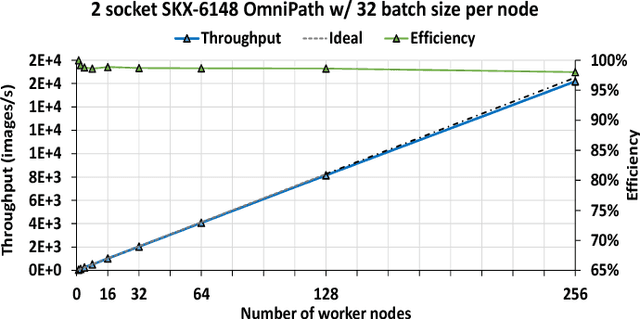
The exponential growth in use of large deep neural networks has accelerated the need for training these deep neural networks in hours or even minutes. This can only be achieved through scalable and efficient distributed training, since a single node/card cannot satisfy the compute, memory, and I/O requirements of today's state-of-the-art deep neural networks. However, scaling synchronous Stochastic Gradient Descent (SGD) is still a challenging problem and requires continued research/development. This entails innovations spanning algorithms, frameworks, communication libraries, and system design. In this paper, we describe the philosophy, design, and implementation of Intel Machine Learning Scalability Library (MLSL) and present proof-points demonstrating scaling DL training on 100s to 1000s of nodes across Cloud and HPC systems.
Distributed Deep Learning Using Synchronous Stochastic Gradient Descent
Feb 22, 2016
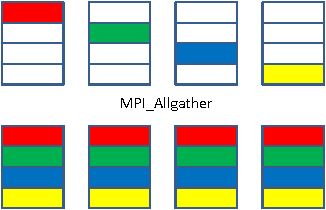
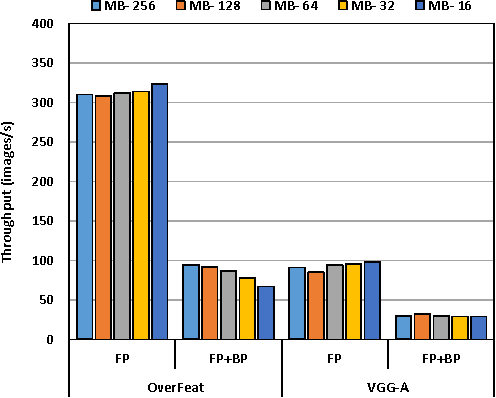
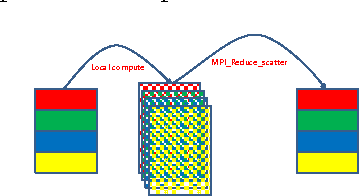
We design and implement a distributed multinode synchronous SGD algorithm, without altering hyper parameters, or compressing data, or altering algorithmic behavior. We perform a detailed analysis of scaling, and identify optimal design points for different networks. We demonstrate scaling of CNNs on 100s of nodes, and present what we believe to be record training throughputs. A 512 minibatch VGG-A CNN training run is scaled 90X on 128 nodes. Also 256 minibatch VGG-A and OverFeat-FAST networks are scaled 53X and 42X respectively on a 64 node cluster. We also demonstrate the generality of our approach via best-in-class 6.5X scaling for a 7-layer DNN on 16 nodes. Thereafter we attempt to democratize deep-learning by training on an Ethernet based AWS cluster and show ~14X scaling on 16 nodes.