 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAC-Attention: a Match-Amend-Complete Scheme for Fast and Accurate Attention Computation
Mar 31, 2026Long-context decoding in LLMs is IO-bound: each token re-reads an ever-growing KV cache. Prior accelerations cut bytes via compression, which lowers fidelity, or selection/eviction, which restricts what remains accessible, and both can degrade delayed recall and long-form generation. We introduce MAC-Attention, a fidelity- and access-preserving alternative that accelerates decoding by reusing prior attention computations for semantically similar recent queries. It starts with a match stage that performs pre-RoPE L2 matching over a short local window; an amend stage rectifies the reused attention by recomputing a small band near the match boundary; and a complete stage fuses the rectified results with fresh attention computed on the KV tail through a numerically stable merge. On a match hit, the compute and bandwidth complexity is constant regardless of context length. The method is model-agnostic and composes with IO-aware kernels, paged-KV managers, and MQA/GQA. Across LongBench v2 (120K), RULER (120K), and LongGenBench (16K continuous generation), compared to the latest FlashInfer library, MAC-Attention reduces KV accesses by up to 99%, cuts token generation latency by over 60% at 128K, and achieves over 14.3x attention-phase speedups, up to 2.6x end-to-end, while maintaining full-attention quality. By reusing computation, MAC-Attention delivers long-context inference that is both fast and faithful. Code is available here: https://github.com/YJHMITWEB/MAC-Attention.git
OMB-Py: Python Micro-Benchmarks for Evaluating Performance of MPI Libraries on HPC Systems
Oct 20, 2021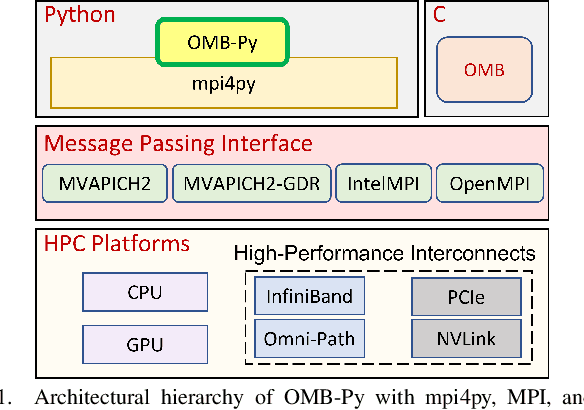
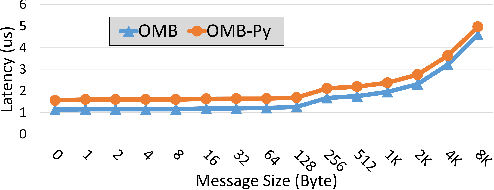
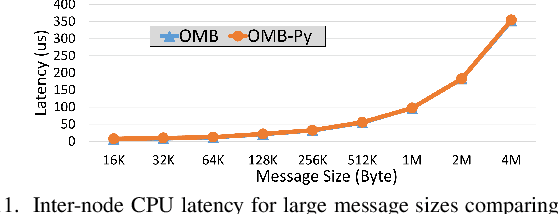
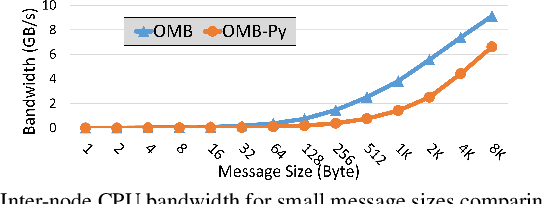
Python has become a dominant programming language for emerging areas like Machine Learning (ML), Deep Learning (DL), and Data Science (DS). An attractive feature of Python is that it provides easy-to-use programming interface while allowing library developers to enhance performance of their applications by harnessing the computing power offered by High Performance Computing (HPC) platforms. Efficient communication is key to scaling applications on parallel systems, which is typically enabled by the Message Passing Interface (MPI) standard and compliant libraries on HPC hardware. mpi4py is a Python-based communication library that provides an MPI-like interface for Python applications allowing application developers to utilize parallel processing elements including GPUs. However, there is currently no benchmark suite to evaluate communication performance of mpi4py -- and Python MPI codes in general -- on modern HPC systems. In order to bridge this gap, we propose OMB-Py -- Python extensions to the open-source OSU Micro-Benchmark (OMB) suite -- aimed to evaluate communication performance of MPI-based parallel applications in Python. To the best of our knowledge, OMB-Py is the first communication benchmark suite for parallel Python applications. OMB-Py consists of a variety of point-to-point and collective communication benchmark tests that are implemented for a range of popular Python libraries including NumPy, CuPy, Numba, and PyCUDA. We also provide Python implementation for several distributed ML algorithms as benchmarks to understand the potential gain in performance for ML/DL workloads. Our evaluation reveals that mpi4py introduces a small overhead when compared to native MPI libraries. We also evaluate the ML/DL workloads and report up to 106x speedup on 224 CPU cores compared to sequential execution. We plan to publicly release OMB-Py to benefit Python HPC community.