 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRIMT: Preference-based Reinforcement Learning with Multimodal Feedback and Trajectory Synthesis from Foundation Models
Sep 19, 2025Preference-based reinforcement learning (PbRL) has emerged as a promising paradigm for teaching robots complex behaviors without reward engineering. However, its effectiveness is often limited by two critical challenges: the reliance on extensive human input and the inherent difficulties in resolving query ambiguity and credit assignment during reward learning. In this paper, we introduce PRIMT, a PbRL framework designed to overcome these challenges by leveraging foundation models (FMs) for multimodal synthetic feedback and trajectory synthesis. Unlike prior approaches that rely on single-modality FM evaluations, PRIMT employs a hierarchical neuro-symbolic fusion strategy, integrating the complementary strengths of large language models and vision-language models in evaluating robot behaviors for more reliable and comprehensive feedback. PRIMT also incorporates foresight trajectory generation, which reduces early-stage query ambiguity by warm-starting the trajectory buffer with bootstrapped samples, and hindsight trajectory augmentation, which enables counterfactual reasoning with a causal auxiliary loss to improve credit assignment. We evaluate PRIMT on 2 locomotion and 6 manipulation tasks on various benchmarks, demonstrating superior performance over FM-based and scripted baselines.
AuD-Former: A Hierarchical Transformer Network for Multimodal Audio-Based Disease Prediction
Oct 11, 2024



Audio-based disease prediction is emerging as a promising supplement to traditional medical diagnosis methods, facilitating early, convenient, and non-invasive disease detection and prevention. Multimodal fusion, which integrates features from various domains within or across bio-acoustic modalities, has proven effective in enhancing diagnostic performance. However, most existing methods in the field employ unilateral fusion strategies that focus solely on either intra-modal or inter-modal fusion. This approach limits the full exploitation of the complementary nature of diverse acoustic feature domains and bio-acoustic modalities. Additionally, the inadequate and isolated exploration of latent dependencies within modality-specific and modality-shared spaces curtails their capacity to manage the inherent heterogeneity in multimodal data. To fill these gaps, we propose AuD-Former, a hierarchical transformer network designed for general multimodal audio-based disease prediction. Specifically, we seamlessly integrate intra-modal and inter-modal fusion in a hierarchical manner and proficiently encode the necessary intra-modal and inter-modal complementary correlations, respectively. Comprehensive experiments demonstrate that AuD-Former achieves state-of-the-art performance in predicting three diseases: COVID-19, Parkinson's disease, and pathological dysarthria, showcasing its promising potential in a broad context of audio-based disease prediction tasks. Additionally, extensive ablation studies and qualitative analyses highlight the significant benefits of each main component within our model.
REBEL: Rule-based and Experience-enhanced Learning with LLMs for Initial Task Allocation in Multi-Human Multi-Robot Teams
Sep 24, 2024



Multi-human multi-robot teams combine the complementary strengths of humans and robots to tackle complex tasks across diverse applications. However, the inherent heterogeneity of these teams presents significant challenges in initial task allocation (ITA), which involves assigning the most suitable tasks to each team member based on their individual capabilities before task execution. While current learning-based methods have shown promising results, they are often computationally expensive to train, and lack the flexibility to incorporate user preferences in multi-objective optimization and adapt to last-minute changes in real-world dynamic environments. To address these issues, we propose REBEL, an LLM-based ITA framework that integrates rule-based and experience-enhanced learning. By leveraging Retrieval-Augmented Generation, REBEL dynamically retrieves relevant rules and past experiences, enhancing reasoning efficiency. Additionally, REBEL can complement pre-trained RL-based ITA policies, improving situational awareness and overall team performance. Extensive experiments validate the effectiveness of our approach across various settings. More details are available at https://sites.google.com/view/ita-rebel .
Adaptive Task Allocation in Multi-Human Multi-Robot Teams under Team Heterogeneity and Dynamic Information Uncertainty
Sep 20, 2024



Task allocation in multi-human multi-robot (MH-MR) teams presents significant challenges due to the inherent heterogeneity of team members, the dynamics of task execution, and the information uncertainty of operational states. Existing approaches often fail to address these challenges simultaneously, resulting in suboptimal performance. To tackle this, we propose ATA-HRL, an adaptive task allocation framework using hierarchical reinforcement learning (HRL), which incorporates initial task allocation (ITA) that leverages team heterogeneity and conditional task reallocation in response to dynamic operational states. Additionally, we introduce an auxiliary state representation learning task to manage information uncertainty and enhance task execution. Through an extensive case study in large-scale environmental monitoring tasks, we demonstrate the benefits of our approach.
PrefMMT: Modeling Human Preferences in Preference-based Reinforcement Learning with Multimodal Transformers
Sep 20, 2024



Preference-based reinforcement learning (PbRL) shows promise in aligning robot behaviors with human preferences, but its success depends heavily on the accurate modeling of human preferences through reward models. Most methods adopt Markovian assumptions for preference modeling (PM), which overlook the temporal dependencies within robot behavior trajectories that impact human evaluations. While recent works have utilized sequence modeling to mitigate this by learning sequential non-Markovian rewards, they ignore the multimodal nature of robot trajectories, which consist of elements from two distinctive modalities: state and action. As a result, they often struggle to capture the complex interplay between these modalities that significantly shapes human preferences. In this paper, we propose a multimodal sequence modeling approach for PM by disentangling state and action modalities. We introduce a multimodal transformer network, named PrefMMT, which hierarchically leverages intra-modal temporal dependencies and inter-modal state-action interactions to capture complex preference patterns. We demonstrate that PrefMMT consistently outperforms state-of-the-art PM baselines on locomotion tasks from the D4RL benchmark and manipulation tasks from the Meta-World benchmark.
Personalization in Human-Robot Interaction through Preference-based Action Representation Learning
Sep 20, 2024



Preference-based reinforcement learning (PbRL) has shown significant promise for personalization in human-robot interaction (HRI) by explicitly integrating human preferences into the robot learning process. However, existing practices often require training a personalized robot policy from scratch, resulting in inefficient use of human feedback. In this paper, we propose preference-based action representation learning (PbARL), an efficient fine-tuning method that decouples common task structure from preference by leveraging pre-trained robot policies. Instead of directly fine-tuning the pre-trained policy with human preference, PbARL uses it as a reference for an action representation learning task that maximizes the mutual information between the pre-trained source domain and the target user preference-aligned domain. This approach allows the robot to personalize its behaviors while preserving original task performance and eliminates the need for extensive prior information from the source domain, thereby enhancing efficiency and practicality in real-world HRI scenarios. Empirical results on the Assistive Gym benchmark and a real-world user study (N=8) demonstrate the benefits of our method compared to state-of-the-art approaches.
PrefCLM: Enhancing Preference-based Reinforcement Learning with Crowdsourced Large Language Models
Jul 11, 2024



Preference-based reinforcement learning (PbRL) is emerging as a promising approach to teaching robots through human comparative feedback, sidestepping the need for complex reward engineering. However, the substantial volume of feedback required in existing PbRL methods often lead to reliance on synthetic feedback generated by scripted teachers. This approach necessitates intricate reward engineering again and struggles to adapt to the nuanced preferences particular to human-robot interaction (HRI) scenarios, where users may have unique expectations toward the same task. To address these challenges, we introduce PrefCLM, a novel framework that utilizes crowdsourced large language models (LLMs) as simulated teachers in PbRL. We utilize Dempster-Shafer Theory to fuse individual preferences from multiple LLM agents at the score level, efficiently leveraging their diversity and collective intelligence. We also introduce a human-in-the-loop pipeline that facilitates collective refinements based on user interactive feedback. Experimental results across various general RL tasks show that PrefCLM achieves competitive performance compared to traditional scripted teachers and excels in facilitating more more natural and efficient behaviors. A real-world user study (N=10) further demonstrates its capability to tailor robot behaviors to individual user preferences, significantly enhancing user satisfaction in HRI scenarios.
Initial Task Assignment in Multi-Human Multi-Robot Teams: An Attention-enhanced Hierarchical Reinforcement Learning Approach
Oct 08, 2023



Multi-human multi-robot teams (MH-MR) obtain tremendous potential in tackling intricate and massive missions by merging distinct strengths and expertise of individual members. The inherent heterogeneity of these teams necessitates advanced initial task assignment (ITA) methods that align tasks with the intrinsic capabilities of team members from the outset. While existing reinforcement learning approaches show encouraging results, they might fall short in addressing the nuances of long-horizon ITA problems, particularly in settings with large-scale MH-MR teams or multifaceted tasks. To bridge this gap, we propose an attention-enhanced hierarchical reinforcement learning approach that decomposes the complex ITA problem into structured sub-problems, facilitating more efficient allocations. To bolster sub-policy learning, we introduce a hierarchical cross-attribute attention (HCA) mechanism, encouraging each sub-policy within the hierarchy to discern and leverage the specific nuances in the state space that are crucial for its respective decision-making phase. Through an extensive environmental surveillance case study, we demonstrate the benefits of our model and the HCA inside.
Initial Task Allocation for Multi-Human Multi-Robot Teams with Attention-based Deep Reinforcement Learning
Mar 04, 2023Multi-human multi-robot teams have great potential for complex and large-scale tasks through the collaboration of humans and robots with diverse capabilities and expertise. To efficiently operate such highly heterogeneous teams and maximize team performance timely, sophisticated initial task allocation strategies that consider individual differences across team members and tasks are required. While existing works have shown promising results in reallocating tasks based on agent state and performance, the neglect of the inherent heterogeneity of the team hinders their effectiveness in realistic scenarios. In this paper, we present a novel formulation of the initial task allocation problem in multi-human multi-robot teams as contextual multi-attribute decision-make process and propose an attention-based deep reinforcement learning approach. We introduce a cross-attribute attention module to encode the latent and complex dependencies of multiple attributes in the state representation. We conduct a case study in a massive threat surveillance scenario and demonstrate the strengths of our model.
Husformer: A Multi-Modal Transformer for Multi-Modal Human State Recognition
Sep 30, 2022

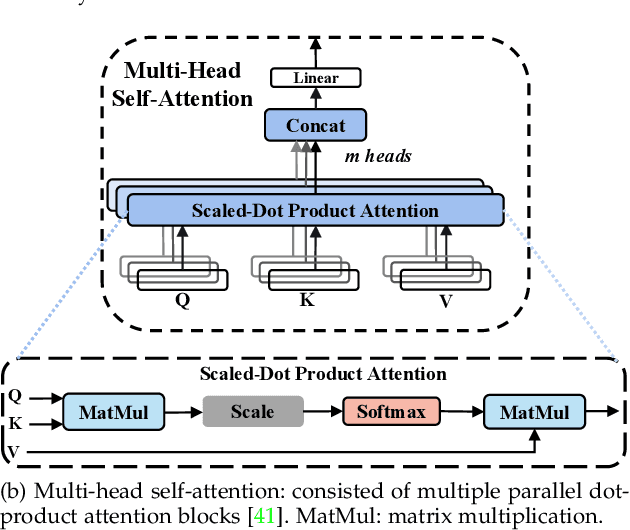

Human state recognition is a critical topic with pervasive and important applications in human-machine systems.Multi-modal fusion, the combination of metrics from multiple data sources, has been shown as a sound method for improving the recognition performance. However, while promising results have been reported by recent multi-modal-based models, they generally fail to leverage the sophisticated fusion strategies that would model sufficient cross-modal interactions when producing the fusion representation; instead, current methods rely on lengthy and inconsistent data preprocessing and feature crafting. To address this limitation, we propose an end-to-end multi-modal transformer framework for multi-modal human state recognition called Husformer.Specifically, we propose to use cross-modal transformers, which inspire one modality to reinforce itself through directly attending to latent relevance revealed in other modalities, to fuse different modalities while ensuring sufficient awareness of the cross-modal interactions introduced. Subsequently, we utilize a self-attention transformer to further prioritize contextual information in the fusion representation. Using two such attention mechanisms enables effective and adaptive adjustments to noise and interruptions in multi-modal signals during the fusion process and in relation to high-level features. Extensive experiments on two human emotion corpora (DEAP and WESAD) and two cognitive workload datasets (MOCAS and CogLoad) demonstrate that in the recognition of human state, our Husformer outperforms both state-of-the-art multi-modal baselines and the use of a single modality by a large margin, especially when dealing with raw multi-modal signals. We also conducted an ablation study to show the benefits of each component in Husformer/