 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication of Hierarchical Temporal Memory Theory for Document Categorization
Dec 29, 2021
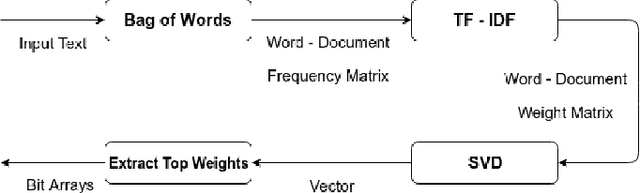
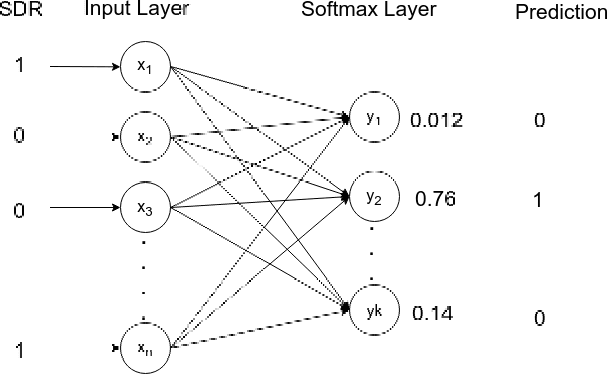
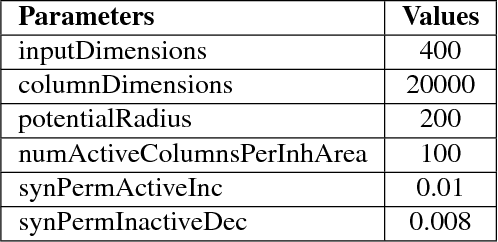
The current work intends to study the performance of the Hierarchical Temporal Memory(HTM) theory for automated classification of text as well as documents. HTM is a biologically inspired theory based on the working principles of the human neocortex. The current study intends to provide an alternative framework for document categorization using the Spatial Pooler learning algorithm in the HTM Theory. As HTM accepts only a stream of binary data as input, Latent Semantic Indexing(LSI) technique is used for extracting the top features from the input and converting them into binary format. The Spatial Pooler algorithm converts the binary input into sparse patterns with similar input text having overlapping spatial patterns making it easy for classifying the patterns into categories. The results obtained prove that HTM theory, although is in its nascent stages, performs at par with most of the popular machine learning based classifiers.
* 6 pages, 3 figures, 2 tables
Predictive Biases in Natural Language Processing Models: A Conceptual Framework and Overview
Nov 09, 2019
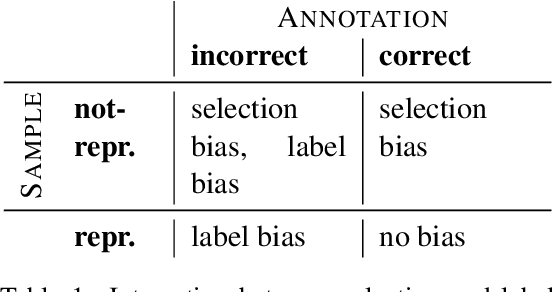
An increasing number of works in natural language processing have addressed the effect of bias on the predicted outcomes, introducing mitigation techniques that act on different parts of the standard NLP pipeline (data and models). However, these works have been conducted in isolation, without a unifying framework to organize efforts within the field. This leads to repetitive approaches, and puts an undue focus on the effects of bias, rather than on their origins. Research focused on bias symptoms rather than the underlying origins could limit the development of effective countermeasures. In this paper, we propose a unifying conceptualization: the predictive bias framework for NLP. We summarize the NLP literature and propose a general mathematical definition of predictive bias in NLP along with a conceptual framework, differentiating four main origins of biases: label bias, selection bias, model overamplification, and semantic bias. We discuss how past work has countered each bias origin. Our framework serves to guide an introductory overview of predictive bias in NLP, integrating existing work into a single structure and opening avenues for future research.
Brain Tumor Detection Based on Bilateral Symmetry Information
Dec 09, 2014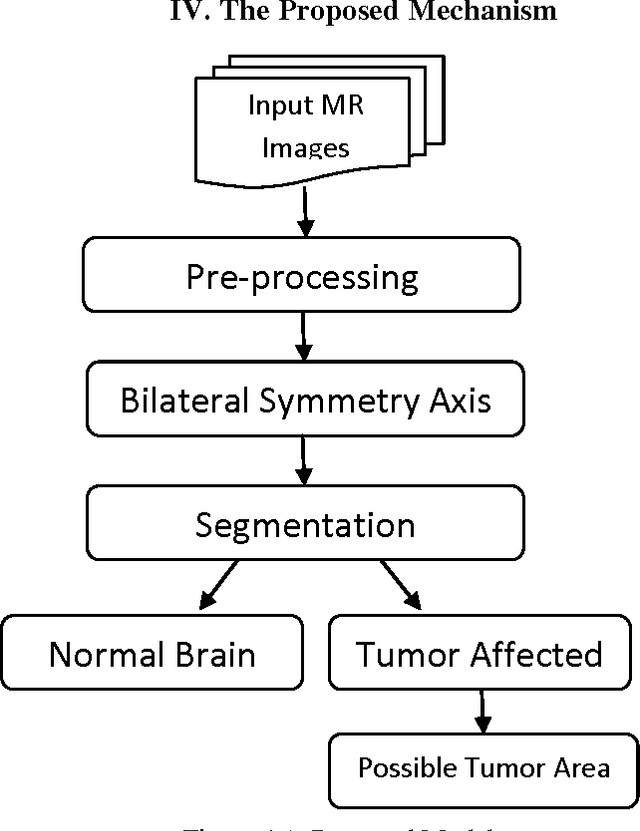
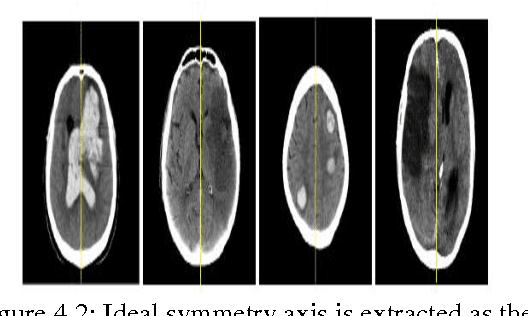
Advances in computing technology have allowed researchers across many fields of endeavor to collect and maintain vast amounts of observational statistical data such as clinical data,biological patient data,data regarding access of web sites,financial data,and the like.Brain Magnetic Resonance Imaging(MRI)segmentation is a complex problem in the field of medical imaging despite various presented methods.MR image of human brain can be divided into several sub regions especially soft tissues such as gray matter,white matter and cerebrospinal fluid.Although edge information is the main clue in image segmentation,it can not get a better result in analysis the content of images without combining other information.The segmentation of brain tissue in the magnetic resonance imaging(MRI)is very important for detecting the existence and outlines of tumors.In this paper,an algorithm about segmentation based on the symmetry character of brain MRI image is presented.Our goal is to detect the position and boundary of tumors automatically.Experiments were conducted on real pictures,and the results show that the algorithm is flexible and convenient.
* 06 pages,02 figures,06 graphs. arXiv admin note: text overlap with arXiv:1403.6002