 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Synthetic Control
Nov 18, 2017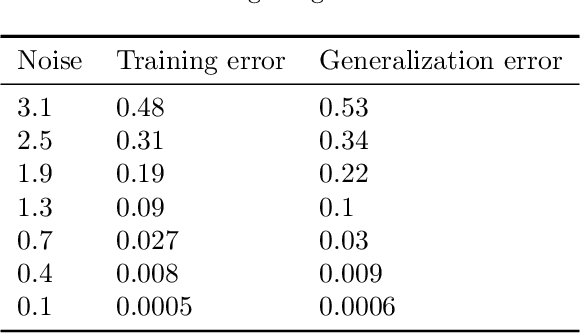
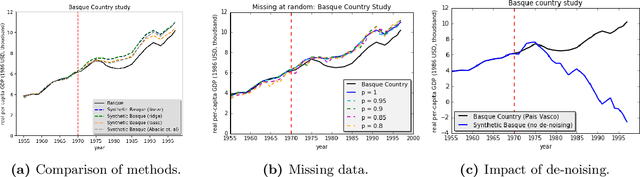
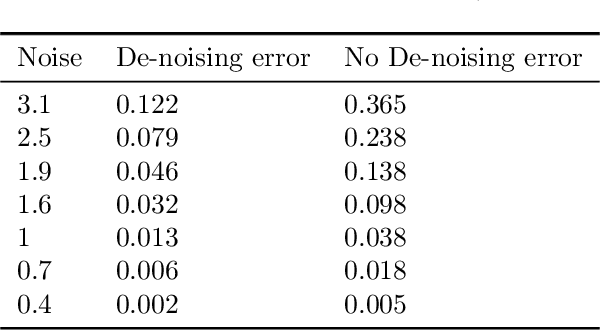
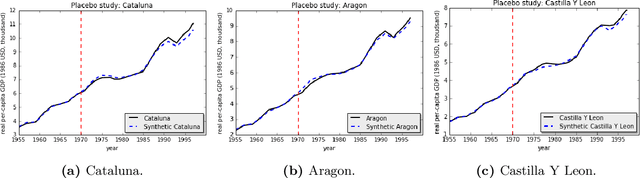
We present a robust generalization of the synthetic control method for comparative case studies. Like the classical method, we present an algorithm to estimate the unobservable counterfactual of a treatment unit. A distinguishing feature of our algorithm is that of de-noising the data matrix via singular value thresholding, which renders our approach robust in multiple facets: it automatically identifies a good subset of donors, overcomes the challenges of missing data, and continues to work well in settings where covariate information may not be provided. To begin, we establish the condition under which the fundamental assumption in synthetic control-like approaches holds, i.e. when the linear relationship between the treatment unit and the donor pool prevails in both the pre- and post-intervention periods. We provide the first finite sample analysis for a broader class of models, the Latent Variable Model, in contrast to Factor Models previously considered in the literature. Further, we show that our de-noising procedure accurately imputes missing entries, producing a consistent estimator of the underlying signal matrix provided $p = \Omega( T^{-1 + \zeta})$ for some $\zeta > 0$; here, $p$ is the fraction of observed data and $T$ is the time interval of interest. Under the same setting, we prove that the mean-squared-error (MSE) in our prediction estimation scales as $O(\sigma^2/p + 1/\sqrt{T})$, where $\sigma^2$ is the noise variance. Using a data aggregation method, we show that the MSE can be made as small as $O(T^{-1/2+\gamma})$ for any $\gamma \in (0, 1/2)$, leading to a consistent estimator. We also introduce a Bayesian framework to quantify the model uncertainty through posterior probabilities. Our experiments, using both real-world and synthetic datasets, demonstrate that our robust generalization yields an improvement over the classical synthetic control method.
Regret Guarantees for Item-Item Collaborative Filtering
Jan 08, 2016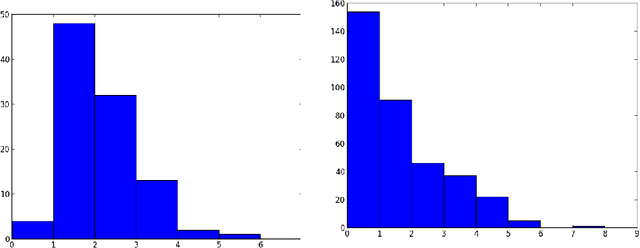
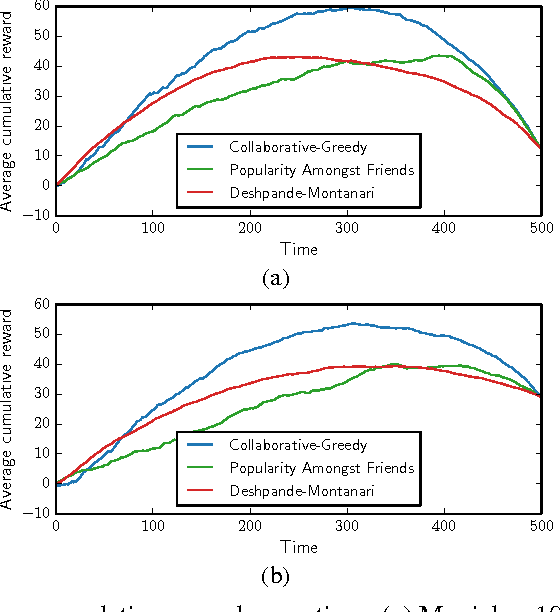
There is much empirical evidence that item-item collaborative filtering works well in practice. Motivated to understand this, we provide a framework to design and analyze various recommendation algorithms. The setup amounts to online binary matrix completion, where at each time a random user requests a recommendation and the algorithm chooses an entry to reveal in the user's row. The goal is to minimize regret, or equivalently to maximize the number of +1 entries revealed at any time. We analyze an item-item collaborative filtering algorithm that can achieve fundamentally better performance compared to user-user collaborative filtering. The algorithm achieves good "cold-start" performance (appropriately defined) by quickly making good recommendations to new users about whom there is little information.
Rank Centrality: Ranking from Pair-wise Comparisons
Nov 12, 2015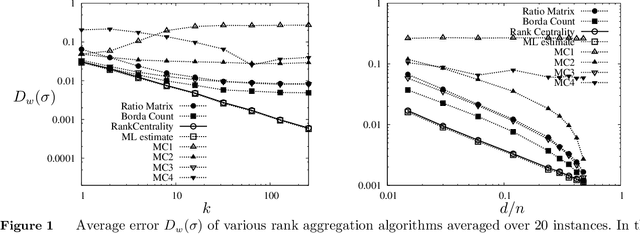
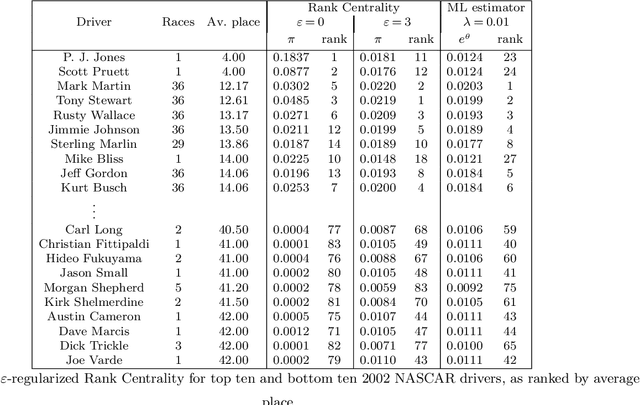
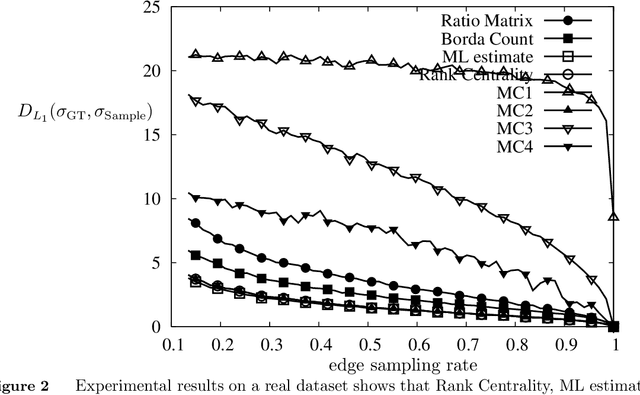
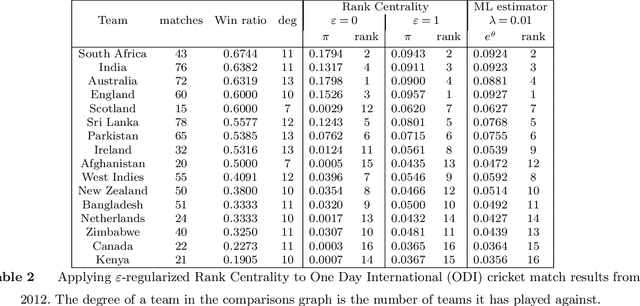
The question of aggregating pair-wise comparisons to obtain a global ranking over a collection of objects has been of interest for a very long time: be it ranking of online gamers (e.g. MSR's TrueSkill system) and chess players, aggregating social opinions, or deciding which product to sell based on transactions. In most settings, in addition to obtaining a ranking, finding `scores' for each object (e.g. player's rating) is of interest for understanding the intensity of the preferences. In this paper, we propose Rank Centrality, an iterative rank aggregation algorithm for discovering scores for objects (or items) from pair-wise comparisons. The algorithm has a natural random walk interpretation over the graph of objects with an edge present between a pair of objects if they are compared; the score, which we call Rank Centrality, of an object turns out to be its stationary probability under this random walk. To study the efficacy of the algorithm, we consider the popular Bradley-Terry-Luce (BTL) model (equivalent to the Multinomial Logit (MNL) for pair-wise comparisons) in which each object has an associated score which determines the probabilistic outcomes of pair-wise comparisons between objects. In terms of the pair-wise marginal probabilities, which is the main subject of this paper, the MNL model and the BTL model are identical. We bound the finite sample error rates between the scores assumed by the BTL model and those estimated by our algorithm. In particular, the number of samples required to learn the score well with high probability depends on the structure of the comparison graph. When the Laplacian of the comparison graph has a strictly positive spectral gap, e.g. each item is compared to a subset of randomly chosen items, this leads to dependence on the number of samples that is nearly order-optimal.
A Latent Source Model for Patch-Based Image Segmentation
Oct 06, 2015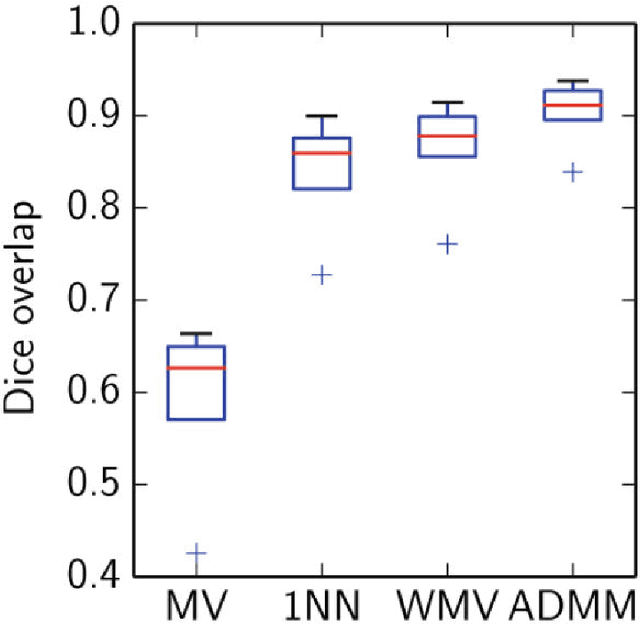
Despite the popularity and empirical success of patch-based nearest-neighbor and weighted majority voting approaches to medical image segmentation, there has been no theoretical development on when, why, and how well these nonparametric methods work. We bridge this gap by providing a theoretical performance guarantee for nearest-neighbor and weighted majority voting segmentation under a new probabilistic model for patch-based image segmentation. Our analysis relies on a new local property for how similar nearby patches are, and fuses existing lines of work on modeling natural imagery patches and theory for nonparametric classification. We use the model to derive a new patch-based segmentation algorithm that iterates between inferring local label patches and merging these local segmentations to produce a globally consistent image segmentation. Many existing patch-based algorithms arise as special cases of the new algorithm.
Structure learning of antiferromagnetic Ising models
Dec 03, 2014In this paper we investigate the computational complexity of learning the graph structure underlying a discrete undirected graphical model from i.i.d. samples. We first observe that the notoriously difficult problem of learning parities with noise can be captured as a special case of learning graphical models. This leads to an unconditional computational lower bound of $\Omega (p^{d/2})$ for learning general graphical models on $p$ nodes of maximum degree $d$, for the class of so-called statistical algorithms recently introduced by Feldman et al (2013). The lower bound suggests that the $O(p^d)$ runtime required to exhaustively search over neighborhoods cannot be significantly improved without restricting the class of models. Aside from structural assumptions on the graph such as it being a tree, hypertree, tree-like, etc., many recent papers on structure learning assume that the model has the correlation decay property. Indeed, focusing on ferromagnetic Ising models, Bento and Montanari (2009) showed that all known low-complexity algorithms fail to learn simple graphs when the interaction strength exceeds a number related to the correlation decay threshold. Our second set of results gives a class of repelling (antiferromagnetic) models that have the opposite behavior: very strong interaction allows efficient learning in time $O(p^2)$. We provide an algorithm whose performance interpolates between $O(p^2)$ and $O(p^{d+2})$ depending on the strength of the repulsion.
Learning graphical models from the Glauber dynamics
Nov 29, 2014In this paper we consider the problem of learning undirected graphical models from data generated according to the Glauber dynamics. The Glauber dynamics is a Markov chain that sequentially updates individual nodes (variables) in a graphical model and it is frequently used to sample from the stationary distribution (to which it converges given sufficient time). Additionally, the Glauber dynamics is a natural dynamical model in a variety of settings. This work deviates from the standard formulation of graphical model learning in the literature, where one assumes access to i.i.d. samples from the distribution. Much of the research on graphical model learning has been directed towards finding algorithms with low computational cost. As the main result of this work, we establish that the problem of reconstructing binary pairwise graphical models is computationally tractable when we observe the Glauber dynamics. Specifically, we show that a binary pairwise graphical model on $p$ nodes with maximum degree $d$ can be learned in time $f(d)p^2\log p$, for a function $f(d)$, using nearly the information-theoretic minimum number of samples.
Learning Mixed Multinomial Logit Model from Ordinal Data
Nov 01, 2014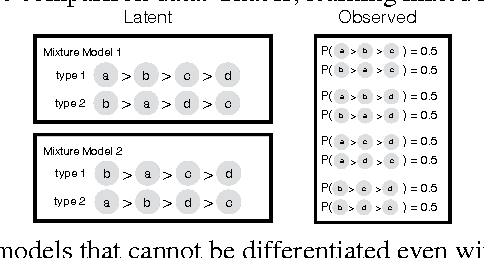
Motivated by generating personalized recommendations using ordinal (or preference) data, we study the question of learning a mixture of MultiNomial Logit (MNL) model, a parameterized class of distributions over permutations, from partial ordinal or preference data (e.g. pair-wise comparisons). Despite its long standing importance across disciplines including social choice, operations research and revenue management, little is known about this question. In case of single MNL models (no mixture), computationally and statistically tractable learning from pair-wise comparisons is feasible. However, even learning mixture with two MNL components is infeasible in general. Given this state of affairs, we seek conditions under which it is feasible to learn the mixture model in both computationally and statistically efficient manner. We present a sufficient condition as well as an efficient algorithm for learning mixed MNL models from partial preferences/comparisons data. In particular, a mixture of $r$ MNL components over $n$ objects can be learnt using samples whose size scales polynomially in $n$ and $r$ (concretely, $r^{3.5}n^3(log n)^4$, with $r\ll n^{2/7}$ when the model parameters are sufficiently incoherent). The algorithm has two phases: first, learn the pair-wise marginals for each component using tensor decomposition; second, learn the model parameters for each component using Rank Centrality introduced by Negahban et al. In the process of proving these results, we obtain a generalization of existing analysis for tensor decomposition to a more realistic regime where only partial information about each sample is available.
A Latent Source Model for Online Collaborative Filtering
Oct 31, 2014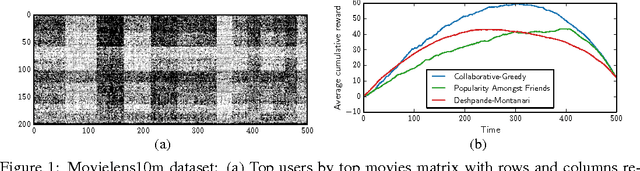
Despite the prevalence of collaborative filtering in recommendation systems, there has been little theoretical development on why and how well it works, especially in the "online" setting, where items are recommended to users over time. We address this theoretical gap by introducing a model for online recommendation systems, cast item recommendation under the model as a learning problem, and analyze the performance of a cosine-similarity collaborative filtering method. In our model, each of $n$ users either likes or dislikes each of $m$ items. We assume there to be $k$ types of users, and all the users of a given type share a common string of probabilities determining the chance of liking each item. At each time step, we recommend an item to each user, where a key distinction from related bandit literature is that once a user consumes an item (e.g., watches a movie), then that item cannot be recommended to the same user again. The goal is to maximize the number of likable items recommended to users over time. Our main result establishes that after nearly $\log(km)$ initial learning time steps, a simple collaborative filtering algorithm achieves essentially optimal performance without knowing $k$. The algorithm has an exploitation step that uses cosine similarity and two types of exploration steps, one to explore the space of items (standard in the literature) and the other to explore similarity between users (novel to this work).
Bayesian regression and Bitcoin
Oct 06, 2014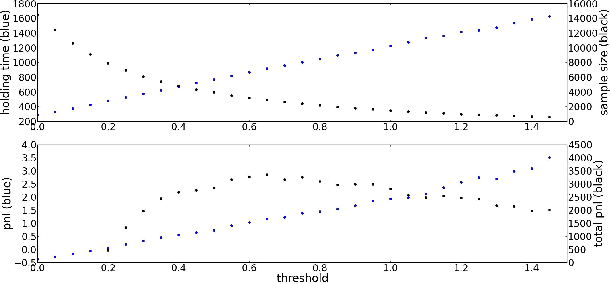
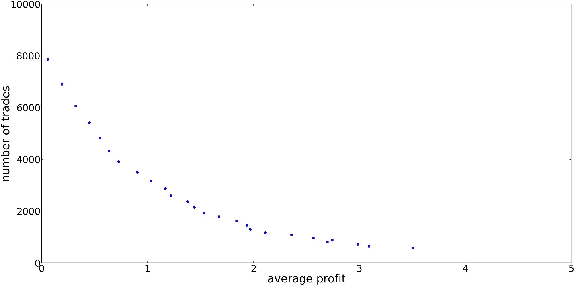
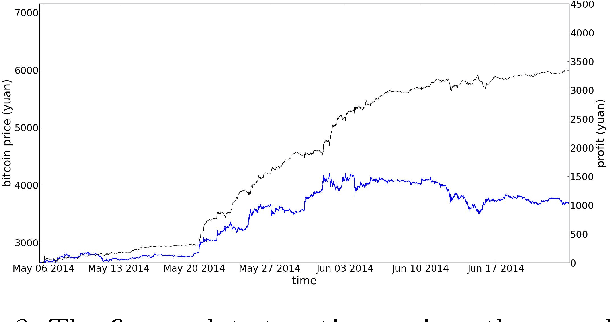
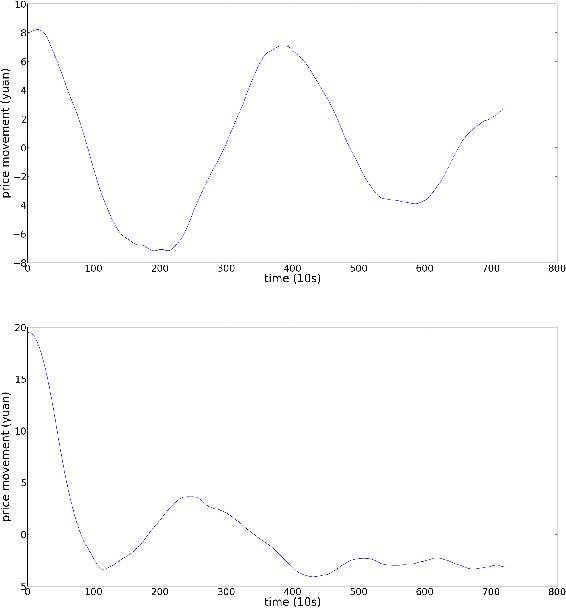
In this paper, we discuss the method of Bayesian regression and its efficacy for predicting price variation of Bitcoin, a recently popularized virtual, cryptographic currency. Bayesian regression refers to utilizing empirical data as proxy to perform Bayesian inference. We utilize Bayesian regression for the so-called "latent source model". The Bayesian regression for "latent source model" was introduced and discussed by Chen, Nikolov and Shah (2013) and Bresler, Chen and Shah (2014) for the purpose of binary classification. They established theoretical as well as empirical efficacy of the method for the setting of binary classification. In this paper, instead we utilize it for predicting real-valued quantity, the price of Bitcoin. Based on this price prediction method, we devise a simple strategy for trading Bitcoin. The strategy is able to nearly double the investment in less than 60 day period when run against real data trace.
Hardness of parameter estimation in graphical models
Sep 17, 2014We consider the problem of learning the canonical parameters specifying an undirected graphical model (Markov random field) from the mean parameters. For graphical models representing a minimal exponential family, the canonical parameters are uniquely determined by the mean parameters, so the problem is feasible in principle. The goal of this paper is to investigate the computational feasibility of this statistical task. Our main result shows that parameter estimation is in general intractable: no algorithm can learn the canonical parameters of a generic pair-wise binary graphical model from the mean parameters in time bounded by a polynomial in the number of variables (unless RP = NP). Indeed, such a result has been believed to be true (see the monograph by Wainwright and Jordan (2008)) but no proof was known. Our proof gives a polynomial time reduction from approximating the partition function of the hard-core model, known to be hard, to learning approximate parameters. Our reduction entails showing that the marginal polytope boundary has an inherent repulsive property, which validates an optimization procedure over the polytope that does not use any knowledge of its structure (as required by the ellipsoid method and others).