 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecification-Aware Distribution Shaping for Robotics Foundation Models
Mar 18, 2026Robotics foundation models have demonstrated strong capabilities in executing natural language instructions across diverse tasks and environments. However, they remain largely data-driven and lack formal guarantees on safety and satisfaction of time-dependent specifications during deployment. In practice, robots often need to comply with operational constraints involving rich spatio-temporal requirements such as time-bounded goal visits, sequential objectives, and persistent safety conditions. In this work, we propose a specification-aware action distribution optimization framework that enforces a broad class of Signal Temporal Logic (STL) constraints during execution of a pretrained robotics foundation model without modifying its parameters. At each decision step, the method computes a minimally modified action distribution that satisfies a hard STL feasibility constraint by reasoning over the remaining horizon using forward dynamics propagation. We validate the proposed framework in simulation using a state-of-the-art robotics foundation model across multiple environments and complex specifications.
Shielded Reinforcement Learning Under Dynamic Temporal Logic Constraints
Mar 17, 2026Reinforcement Learning (RL) has shown promise in various robotics applications, yet its deployment on real systems is still limited due to safety and operational constraints. The safe RL field has gained considerable attention in recent years, which focuses on imposing safety constraints throughout the learning process. However, real systems often require more complex constraints than just safety, such as periodic recharging or time-bounded visits to specific regions. Imposing such spatio-temporal tasks during learning still remains a challenge. Signal Temporal Logic (STL) is a formal language for specifying temporal properties of real-valued signals and provides a way to express such complex tasks. In this paper, we propose a framework that leverages sequential control barrier functions and model-free RL to ensure that the given STL tasks are satisfied throughout the learning process. Our method extends beyond traditional safety constraints by enforcing rich STL specifications, which can involve visits to dynamic targets with unknown trajectories. We also demonstrate the effectiveness of our framework through various simulations.
Contingency-Aware Planning via Certified Neural Hamilton-Jacobi Reachability
Mar 17, 2026Hamilton-Jacobi (HJ) reachability provides formal safety guarantees for dynamical systems, but solving high-dimensional HJ partial differential equations limits its use in real-time planning. This paper presents a contingency-aware multi-goal navigation framework that integrates learning-based reachability with sampling-based planning in unknown environments. We use Fourier Neural Operator (FNO) to approximate the solution operator of the Hamilton-Jacobi-Isaacs variational inequality under varying obstacle configurations. We first provide a theoretical under-approximation guarantee on the safe backward reach-avoid set, which enables formal safety certification of the learned reachable sets. Then, we integrate the certified reachable sets with an incremental multi-goal planner, which enforces reachable-set constraints and a recovery policy that guarantees finite-time return to a safe region. Overall, we demonstrate that the proposed framework achieves asymptotically optimal navigation with provable contingency behavior, and validate its performance through real-time deployment on KUKA's youBot in Webots simulation.
Temporal-Logic-Aware Frontier-Based Exploration
Feb 21, 2026This paper addresses the problem of temporal logic motion planning for an autonomous robot operating in an unknown environment. The objective is to enable the robot to satisfy a syntactically co-safe Linear Temporal Logic (scLTL) specification when the exact locations of the desired labels are not known a priori. We introduce a new type of automaton state, referred to as commit states. These states capture intermediate task progress resulting from actions whose consequences are irreversible. In other words, certain future paths to satisfaction become not feasible after taking those actions that lead to the commit states. By leveraging commit states, we propose a sound and complete frontier-based exploration algorithm that strategically guides the robot to make progress toward the task while preserving all possible ways of satisfying it. The efficacy of the proposed method is validated through simulations.
Motion Planning Under Temporal Logic Specifications In Semantically Unknown Environments
Nov 05, 2025



This paper addresses a motion planning problem to achieve spatio-temporal-logical tasks, expressed by syntactically co-safe linear temporal logic specifications (scLTL\next), in uncertain environments. Here, the uncertainty is modeled as some probabilistic knowledge on the semantic labels of the environment. For example, the task is "first go to region 1, then go to region 2"; however, the exact locations of regions 1 and 2 are not known a priori, instead a probabilistic belief is available. We propose a novel automata-theoretic approach, where a special product automaton is constructed to capture the uncertainty related to semantic labels, and a reward function is designed for each edge of this product automaton. The proposed algorithm utilizes value iteration for online replanning. We show some theoretical results and present some simulations/experiments to demonstrate the efficacy of the proposed approach.
Probabilistic Satisfaction of Temporal Logic Constraints in Reinforcement Learning via Adaptive Policy-Switching
Oct 10, 2024Constrained Reinforcement Learning (CRL) is a subset of machine learning that introduces constraints into the traditional reinforcement learning (RL) framework. Unlike conventional RL which aims solely to maximize cumulative rewards, CRL incorporates additional constraints that represent specific mission requirements or limitations that the agent must comply with during the learning process. In this paper, we address a type of CRL problem where an agent aims to learn the optimal policy to maximize reward while ensuring a desired level of temporal logic constraint satisfaction throughout the learning process. We propose a novel framework that relies on switching between pure learning (reward maximization) and constraint satisfaction. This framework estimates the probability of constraint satisfaction based on earlier trials and properly adjusts the probability of switching between learning and constraint satisfaction policies. We theoretically validate the correctness of the proposed algorithm and demonstrate its performance and scalability through comprehensive simulations.
Reinforcement Learning Under Probabilistic Spatio-Temporal Constraints with Time Windows
Jul 29, 2023We propose an automata-theoretic approach for reinforcement learning (RL) under complex spatio-temporal constraints with time windows. The problem is formulated using a Markov decision process under a bounded temporal logic constraint. Different from existing RL methods that can eventually learn optimal policies satisfying such constraints, our proposed approach enforces a desired probability of constraint satisfaction throughout learning. This is achieved by translating the bounded temporal logic constraint into a total automaton and avoiding "unsafe" actions based on the available prior information regarding the transition probabilities, i.e., a pair of upper and lower bounds for each transition probability. We provide theoretical guarantees on the resulting probability of constraint satisfaction. We also provide numerical results in a scenario where a robot explores the environment to discover high-reward regions while fulfilling some periodic pick-up and delivery tasks that are encoded as temporal logic constraints.
Distributed Planning for Serving Cooperative Tasks with Time Windows: A Game Theoretic Approach
Jul 18, 2021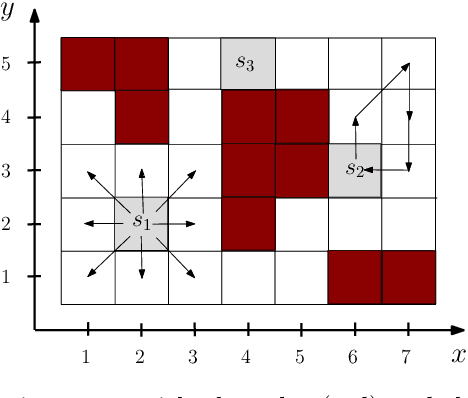

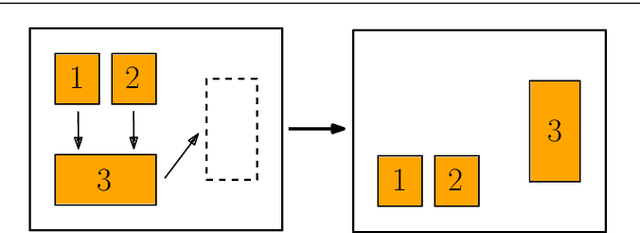
We study distributed planning for multi-robot systems to provide optimal service to cooperative tasks that are distributed over space and time. Each task requires service by sufficiently many robots at the specified location within the specified time window. Tasks arrive over episodes and the robots try to maximize the total value of service in each episode by planning their own trajectories based on the specifications of incoming tasks. Robots are required to start and end each episode at their assigned stations in the environment. We present a game theoretic solution to this problem by mapping it to a game, where the action of each robot is its trajectory in an episode, and using a suitable learning algorithm to obtain optimal joint plans in a distributed manner. We present a systematic way to design minimal action sets (subsets of feasible trajectories) for robots based on the specifications of incoming tasks to facilitate fast learning. We then provide the performance guarantees for the cases where all the robots follow a best response or noisy best response algorithm to iteratively plan their trajectories. While the best response algorithm leads to a Nash equilibrium, the noisy best response algorithm leads to globally optimal joint plans with high probability. We show that the proposed game can in general have arbitrarily poor Nash equilibria, which makes the noisy best response algorithm preferable unless the task specifications are known to have some special structure. We also describe a family of special cases where all the equilibria are guaranteed to have bounded suboptimality. Simulations and experimental results are provided to demonstrate the proposed approach.
Control Synthesis using Signal Temporal Logic Specifications with Integral and Derivative Predicates
Mar 26, 2021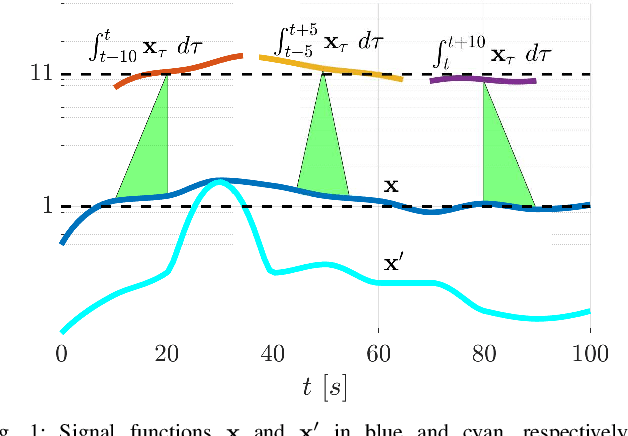
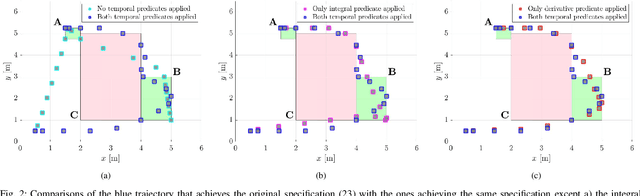
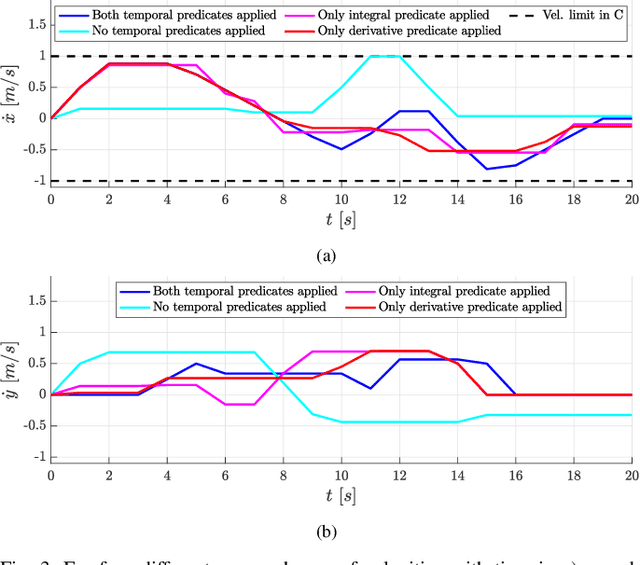
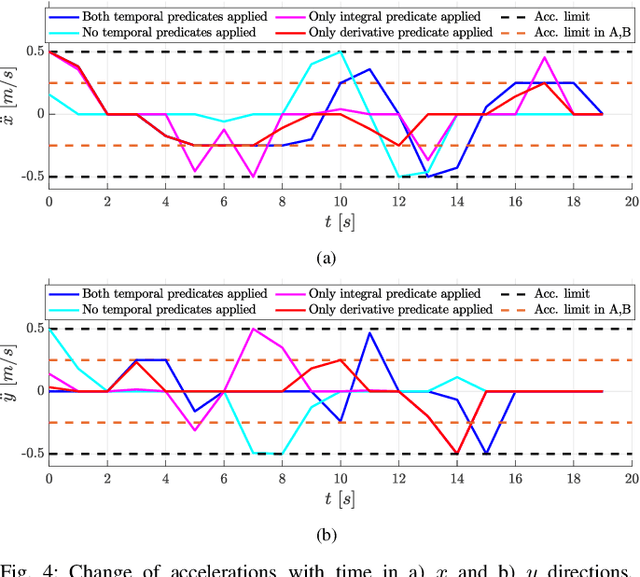
In many applications, the integrals and derivatives of signals carry valuable information (e.g., cumulative success over a time window, the rate of change) regarding the behavior of the underlying system. In this paper, we extend the expressiveness of Signal Temporal Logic (STL) by introducing predicates that can define rich properties related to the integral and derivative of a signal. For control synthesis, the new predicates are encoded into mixed-integer linear inequalities and are used in the formulation of a mixed-integer linear program to find a trajectory that satisfies an STL specification. We discuss the benefits of using the new predicates and illustrate them in a case study showing the influence of the new predicates on the trajectories of an autonomous robot.
Probabilistically Guaranteed Satisfaction of Temporal Logic Constraints During Reinforcement Learning
Feb 19, 2021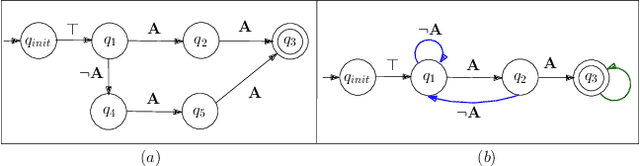
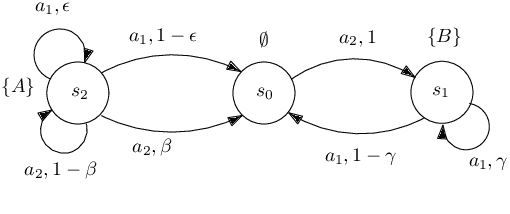
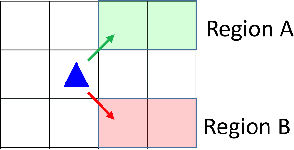
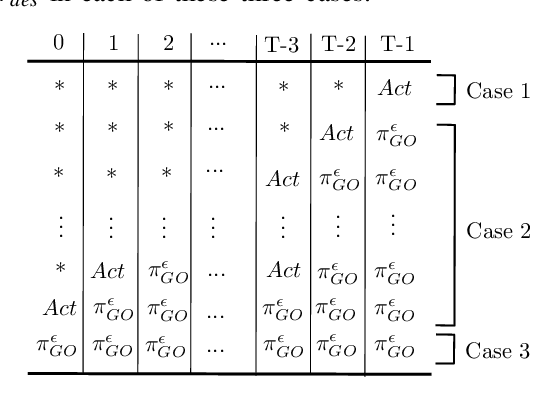
We present a novel reinforcement learning algorithm for finding optimal policies in Markov Decision Processes while satisfying temporal logic constraints with a desired probability throughout the learning process. An automata-theoretic approach is proposed to ensure probabilistic satisfaction of the constraint in each episode, which is different from penalizing violations to achieve constraint satisfaction after a sufficiently large number of episodes. The proposed approach is based on computing a lower bound on the probability of constraint satisfaction and adjusting the exploration behavior as needed. We present theoretical results on the probabilistic constraint satisfaction achieved by the proposed approach. We also numerically demonstrate the proposed idea in a drone scenario, where the constraint is to perform periodically arriving pick-up and delivery tasks and the objective is to fly over high-reward zones to simultaneously perform aerial monitoring.