 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCWD: A Machine Learning based Approach to Detect Unknown Cloud Workloads
Nov 28, 2022



Workloads in modern cloud data centers are becoming increasingly complex. The number of workloads running in cloud data centers has been growing exponentially for the last few years, and cloud service providers (CSP) have been supporting on-demand services in real-time. Realizing the growing complexity of cloud environment and cloud workloads, hardware vendors such as Intel and AMD are increasingly introducing cloud-specific workload acceleration features in their CPU platforms. These features are typically targeted towards popular and commonly-used cloud workloads. Nonetheless, uncommon, customer-specific workloads (unknown workloads), if their characteristics are different from common workloads (known workloads), may not realize the potential of the underlying platform. To address this problem of realizing the full potential of the underlying platform, we develop a machine learning based technique to characterize, profile and predict workloads running in the cloud environment. Experimental evaluation of our technique demonstrates good prediction performance. We also develop techniques to analyze the performance of the model in a standalone manner.
Automatic Tuning of Tensorflow's CPU Backend using Gradient-Free Optimization Algorithms
Sep 13, 2021
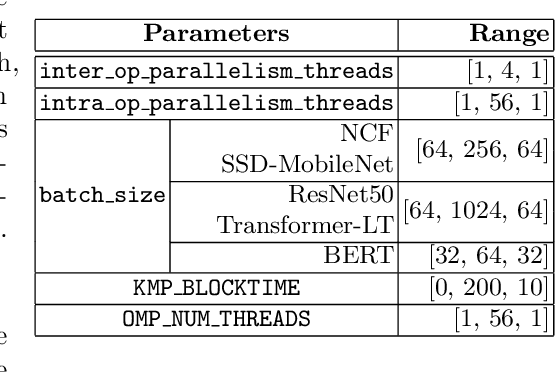
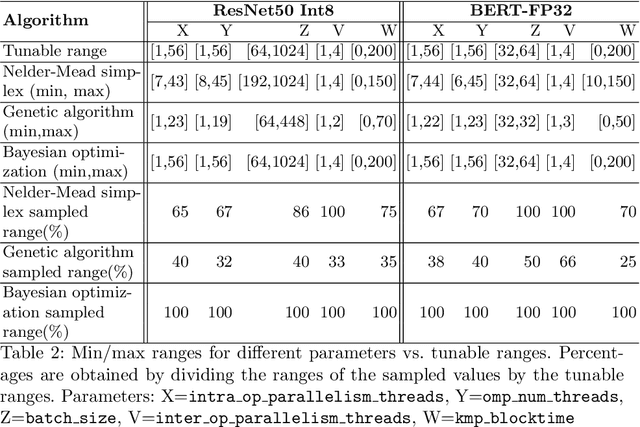
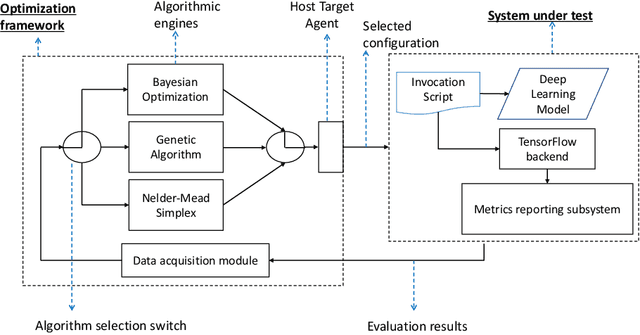
Modern deep learning (DL) applications are built using DL libraries and frameworks such as TensorFlow and PyTorch. These frameworks have complex parameters and tuning them to obtain good training and inference performance is challenging for typical users, such as DL developers and data scientists. Manual tuning requires deep knowledge of the user-controllable parameters of DL frameworks as well as the underlying hardware. It is a slow and tedious process, and it typically delivers sub-optimal solutions. In this paper, we treat the problem of tuning parameters of DL frameworks to improve training and inference performance as a black-box optimization problem. We then investigate applicability and effectiveness of Bayesian optimization (BO), genetic algorithm (GA), and Nelder-Mead simplex (NMS) to tune the parameters of TensorFlow's CPU backend. While prior work has already investigated the use of Nelder-Mead simplex for a similar problem, it does not provide insights into the applicability of other more popular algorithms. Towards that end, we provide a systematic comparative analysis of all three algorithms in tuning TensorFlow's CPU backend on a variety of DL models. Our findings reveal that Bayesian optimization performs the best on the majority of models. There are, however, cases where it does not deliver the best results.