 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCuratr: A Platform for Semantic Analysis and Curation of Historical Literary Texts
Jun 13, 2023The increasing availability of digital collections of historical and contemporary literature presents a wealth of possibilities for new research in the humanities. The scale and diversity of such collections however, presents particular challenges in identifying and extracting relevant content. This paper presents Curatr, an online platform for the exploration and curation of literature with machine learning-supported semantic search, designed within the context of digital humanities scholarship. The platform provides a text mining workflow that combines neural word embeddings with expert domain knowledge to enable the generation of thematic lexicons, allowing researches to curate relevant sub-corpora from a large corpus of 18th and 19th century digitised texts.
* 12 pages
Topic-Centric Explanations for News Recommendation
Jun 13, 2023



News recommender systems (NRS) have been widely applied for online news websites to help users find relevant articles based on their interests. Recent methods have demonstrated considerable success in terms of recommendation performance. However, the lack of explanation for these recommendations can lead to mistrust among users and lack of acceptance of recommendations. To address this issue, we propose a new explainable news model to construct a topic-aware explainable recommendation approach that can both accurately identify relevant articles and explain why they have been recommended, using information from associated topics. Additionally, our model incorporates two coherence metrics applied to assess topic quality, providing measure of the interpretability of these explanations. The results of our experiments on the MIND dataset indicate that the proposed explainable NRS outperforms several other baseline systems, while it is also capable of producing interpretable topics compared to those generated by a classical LDA topic model. Furthermore, we present a case study through a real-world example showcasing the usefulness of our NRS for generating explanations.
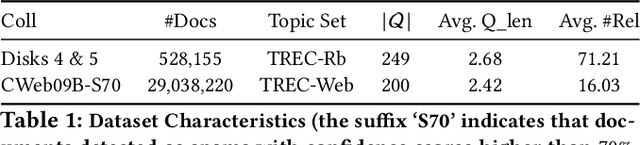
On the Feasibility and Robustness of Pointwise Evaluation of Query Performance Prediction
Apr 01, 2023Despite the retrieval effectiveness of queries being mutually independent of one another, the evaluation of query performance prediction (QPP) systems has been carried out by measuring rank correlation over an entire set of queries. Such a listwise approach has a number of disadvantages, notably that it does not support the common requirement of assessing QPP for individual queries. In this paper, we propose a pointwise QPP framework that allows us to evaluate the quality of a QPP system for individual queries by measuring the deviations between each prediction versus the corresponding true value, and then aggregating the results over a set of queries. Our experiments demonstrate that this new approach leads to smaller variances in QPP evaluations across a range of different target metrics and retrieval models.
Counterfactual Explanations for Misclassified Images: How Human and Machine Explanations Differ
Dec 16, 2022



Counterfactual explanations have emerged as a popular solution for the eXplainable AI (XAI) problem of elucidating the predictions of black-box deep-learning systems due to their psychological validity, flexibility across problem domains and proposed legal compliance. While over 100 counterfactual methods exist, claiming to generate plausible explanations akin to those preferred by people, few have actually been tested on users ($\sim7\%$). So, the psychological validity of these counterfactual algorithms for effective XAI for image data is not established. This issue is addressed here using a novel methodology that (i) gathers ground truth human-generated counterfactual explanations for misclassified images, in two user studies and, then, (ii) compares these human-generated ground-truth explanations to computationally-generated explanations for the same misclassifications. Results indicate that humans do not "minimally edit" images when generating counterfactual explanations. Instead, they make larger, "meaningful" edits that better approximate prototypes in the counterfactual class.
A Novel Perspective to Look At Attention: Bi-level Attention-based Explainable Topic Modeling for News Classification
Mar 14, 2022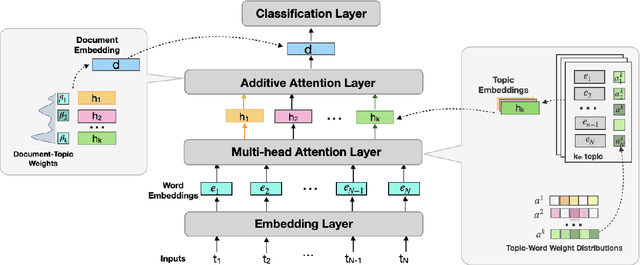

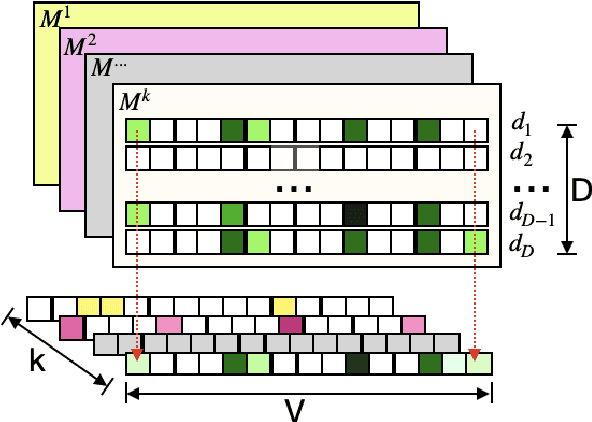
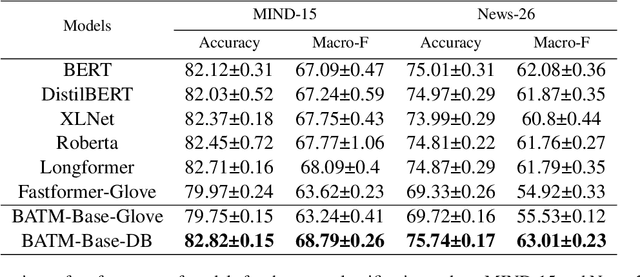
Many recent deep learning-based solutions have widely adopted the attention-based mechanism in various tasks of the NLP discipline. However, the inherent characteristics of deep learning models and the flexibility of the attention mechanism increase the models' complexity, thus leading to challenges in model explainability. In this paper, to address this challenge, we propose a novel practical framework by utilizing a two-tier attention architecture to decouple the complexity of explanation and the decision-making process. We apply it in the context of a news article classification task. The experiments on two large-scaled news corpora demonstrate that the proposed model can achieve competitive performance with many state-of-the-art alternatives and illustrate its appropriateness from an explainability perspective.
Deep-QPP: A Pairwise Interaction-based Deep Learning Model for Supervised Query Performance Prediction
Feb 15, 2022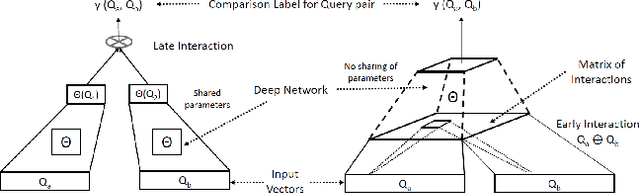
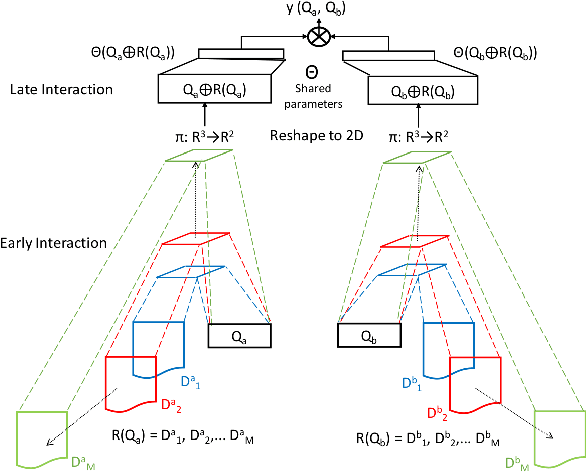
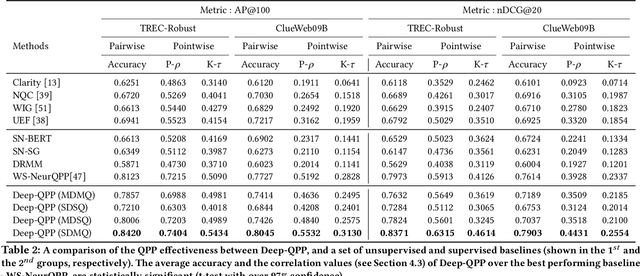
Motivated by the recent success of end-to-end deep neural models for ranking tasks, we present here a supervised end-to-end neural approach for query performance prediction (QPP). In contrast to unsupervised approaches that rely on various statistics of document score distributions, our approach is entirely data-driven. Further, in contrast to weakly supervised approaches, our method also does not rely on the outputs from different QPP estimators. In particular, our model leverages information from the semantic interactions between the terms of a query and those in the top-documents retrieved with it. The architecture of the model comprises multiple layers of 2D convolution filters followed by a feed-forward layer of parameters. Experiments on standard test collections demonstrate that our proposed supervised approach outperforms other state-of-the-art supervised and unsupervised approaches.
An Analysis of Variations in the Effectiveness of Query Performance Prediction
Feb 13, 2022
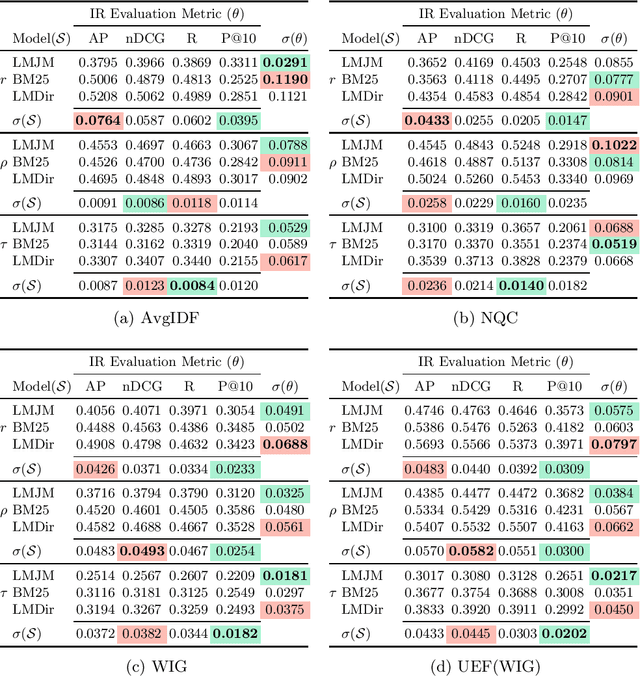
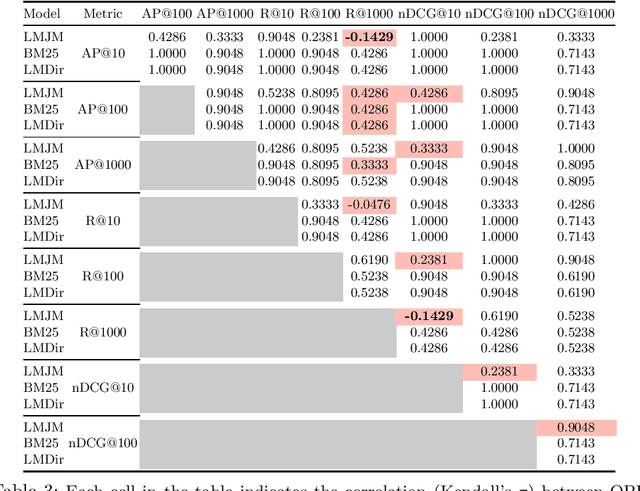
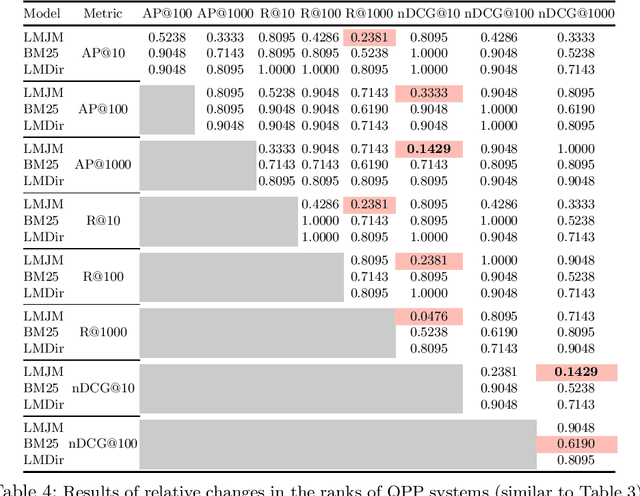
A query performance predictor estimates the retrieval effectiveness of an IR system for a given query. An important characteristic of QPP evaluation is that, since the ground truth retrieval effectiveness for QPP evaluation can be measured with different metrics, the ground truth itself is not absolute, which is in contrast to other retrieval tasks, such as that of ad-hoc retrieval. Motivated by this argument, the objective of this paper is to investigate how such variances in the ground truth for QPP evaluation can affect the outcomes of QPP experiments. We consider this not only in terms of the absolute values of the evaluation metrics being reported (e.g. Pearson's $r$, Kendall's $\tau$), but also with respect to the changes in the ranks of different QPP systems when ordered by the QPP metric scores. Our experiments reveal that the observed QPP outcomes can vary considerably, both in terms of the absolute evaluation metric values and also in terms of the relative system ranks. Through our analysis, we report the optimal combinations of QPP evaluation metric and experimental settings that are likely to lead to smaller variations in the observed results.
Uncertainty Estimation and Out-of-Distribution Detection for Counterfactual Explanations: Pitfalls and Solutions
Jul 20, 2021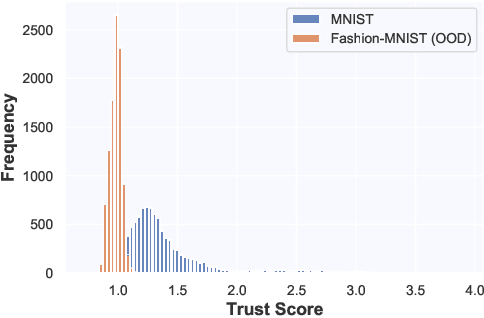
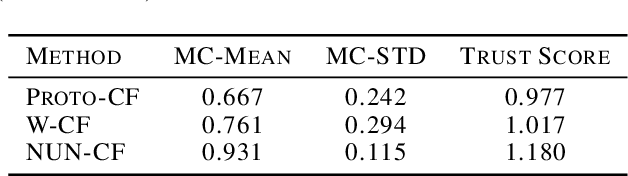
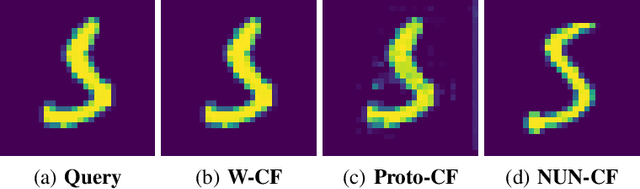
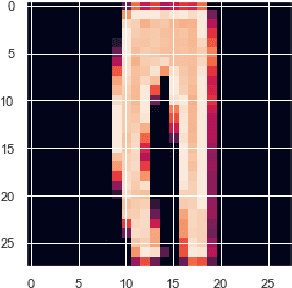
Whilst an abundance of techniques have recently been proposed to generate counterfactual explanations for the predictions of opaque black-box systems, markedly less attention has been paid to exploring the uncertainty of these generated explanations. This becomes a critical issue in high-stakes scenarios, where uncertain and misleading explanations could have dire consequences (e.g., medical diagnosis and treatment planning). Moreover, it is often difficult to determine if the generated explanations are well grounded in the training data and sensitive to distributional shifts. This paper proposes several practical solutions that can be leveraged to solve these problems by establishing novel connections with other research works in explainability (e.g., trust scores) and uncertainty estimation (e.g., Monte Carlo Dropout). Two experiments demonstrate the utility of our proposed solutions.
Twin Systems for DeepCBR: A Menagerie of Deep Learning and Case-Based Reasoning Pairings for Explanation and Data Augmentation
Apr 29, 2021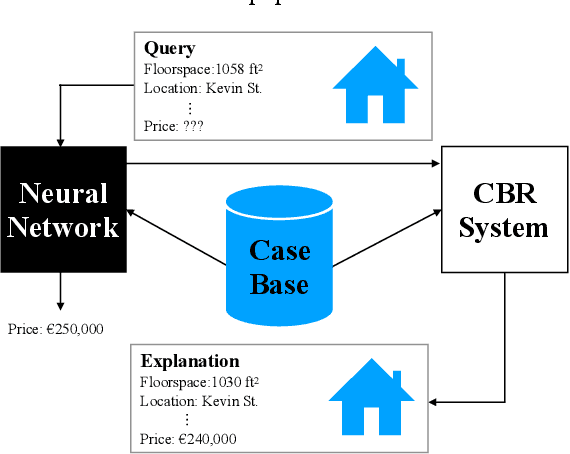
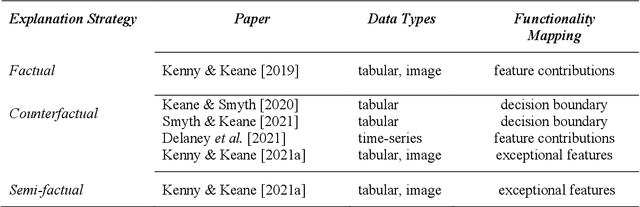
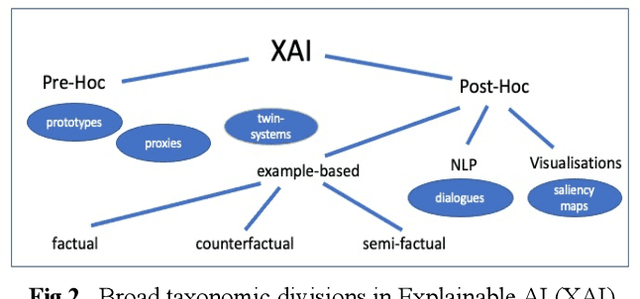

Recently, it has been proposed that fruitful synergies may exist between Deep Learning (DL) and Case Based Reasoning (CBR); that there are insights to be gained by applying CBR ideas to problems in DL (what could be called DeepCBR). In this paper, we report on a program of research that applies CBR solutions to the problem of Explainable AI (XAI) in the DL. We describe a series of twin-systems pairings of opaque DL models with transparent CBR models that allow the latter to explain the former using factual, counterfactual and semi-factual explanation strategies. This twinning shows that functional abstractions of DL (e.g., feature weights, feature importance and decision boundaries) can be used to drive these explanatory solutions. We also raise the prospect that this research also applies to the problem of Data Augmentation in DL, underscoring the fecundity of these DeepCBR ideas.
Instance-Based Counterfactual Explanations for Time Series Classification
Sep 28, 2020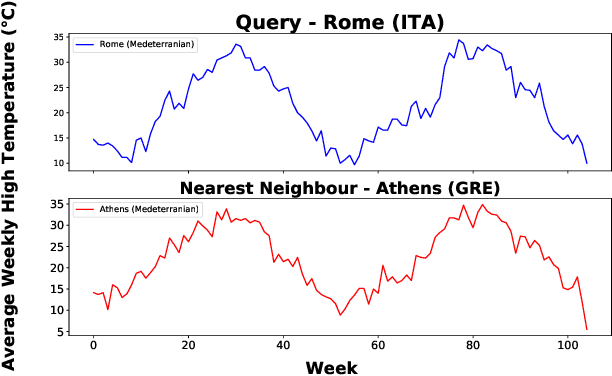

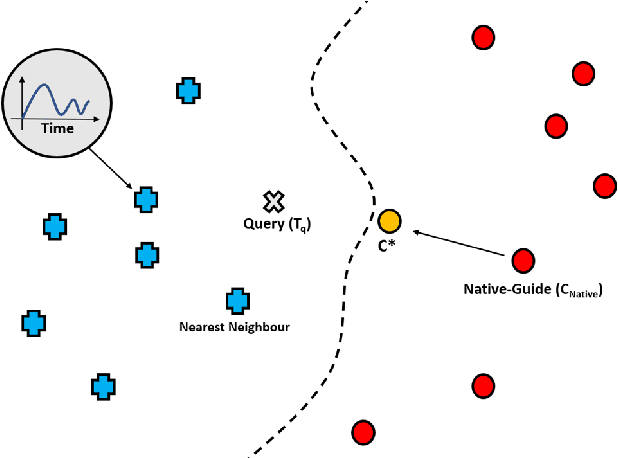
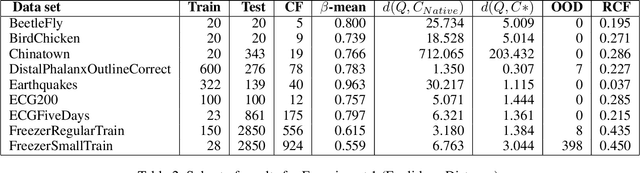
In recent years there has been a cascade of research in attempting to make AI systems more interpretable by providing explanations; so-called Explainable AI (XAI). Most of this research has dealt with the challenges that arise in explaining black-box deep learning systems in classification and regression tasks, with a focus on tabular and image data; for example, there is a rich seam of work on post-hoc counterfactual explanations for a variety of black-box classifiers (e.g., when a user is refused a loan, the counterfactual explanation tells the user about the conditions under which they would get the loan). However, less attention has been paid to the parallel interpretability challenges arising in AI systems dealing with time series data. This paper advances a novel technique, called Native-Guide, for the generation of proximal and plausible counterfactual explanations for instance-based time series classification tasks (e.g., where users are provided with alternative time series to explain how a classification might change). The Native-Guide method retrieves and uses native in-sample counterfactuals that already exist in the training data as "guides" for perturbation in time series counterfactual generation. This method can be coupled with both Euclidean and Dynamic Time Warping (DTW) distance measures. After illustrating the technique on a case study involving a climate classification task, we reported on a comprehensive series of experiments on both real-world and synthetic data sets from the UCR archive. These experiments provide computational evidence of the quality of the counterfactual explanations generated.