 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting and Mitigating Group Bias in Heterogeneous Treatment Effects
Feb 23, 2026Heterogeneous treatment effects (HTEs) are increasingly estimated using machine learning models that produce highly personalized predictions of treatment effects. In practice, however, predicted treatment effects are rarely interpreted, reported, or audited at the individual level but, instead, are often aggregated to broader subgroups, such as demographic segments, risk strata, or markets. We show that such aggregation can induce systematic bias of the group-level causal effect: even when models for predicting the individual-level conditional average treatment effect (CATE) are correctly specified and trained on data from randomized experiments, aggregating the predicted CATEs up to the group level does not, in general, recover the corresponding group average treatment effect (GATE). We develop a unified statistical framework to detect and mitigate this form of group bias in randomized experiments. We first define group bias as the discrepancy between the model-implied and experimentally identified GATEs, derive an asymptotically normal estimator, and then provide a simple-to-implement statistical test. For mitigation, we propose a shrinkage-based bias-correction, and show that the theoretically optimal and empirically feasible solutions have closed-form expressions. The framework is fully general, imposes minimal assumptions, and only requires computing sample moments. We analyze the economic implications of mitigating detected group bias for profit-maximizing personalized targeting, thereby characterizing when bias correction alters targeting decisions and profits, and the trade-offs involved. Applications to large-scale experimental data at major digital platforms validate our theoretical results and demonstrate empirical performance.
A/B/n Testing with Control in the Presence of Subpopulations
Oct 29, 2021
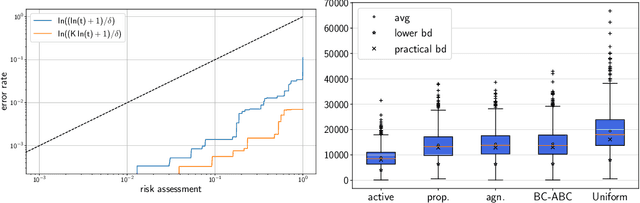
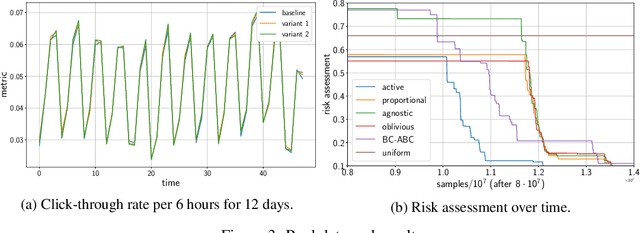

Motivated by A/B/n testing applications, we consider a finite set of distributions (called \emph{arms}), one of which is treated as a \emph{control}. We assume that the population is stratified into homogeneous subpopulations. At every time step, a subpopulation is sampled and an arm is chosen: the resulting observation is an independent draw from the arm conditioned on the subpopulation. The quality of each arm is assessed through a weighted combination of its subpopulation means. We propose a strategy for sequentially choosing one arm per time step so as to discover as fast as possible which arms, if any, have higher weighted expectation than the control. This strategy is shown to be asymptotically optimal in the following sense: if $\tau_\delta$ is the first time when the strategy ensures that it is able to output the correct answer with probability at least $1-\delta$, then $\mathbb{E}[\tau_\delta]$ grows linearly with $\log(1/\delta)$ at the exact optimal rate. This rate is identified in the paper in three different settings: (1) when the experimenter does not observe the subpopulation information, (2) when the subpopulation of each sample is observed but not chosen, and (3) when the experimenter can select the subpopulation from which each response is sampled. We illustrate the efficiency of the proposed strategy with numerical simulations on synthetic and real data collected from an A/B/n experiment.