 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeam RAS in 10th ABAW Competition: Multimodal Valence and Arousal Estimation Approach
Mar 13, 2026Continuous emotion recognition in terms of valence and arousal under in-the-wild (ITW) conditions remains a challenging problem due to large variations in appearance, head pose, illumination, occlusions, and subject-specific patterns of affective expression. We present a multimodal method for valence-arousal estimation ITW. Our method combines three complementary modalities: face, behavior, and audio. The face modality relies on GRADA-based frame-level embeddings and Transformer-based temporal regression. We use Qwen3-VL-4B-Instruct to extract behavior-relevant information from video segments, while Mamba is used to model temporal dynamics across segments. The audio modality relies on WavLM-Large with attention-statistics pooling and includes a cross-modal filtering stage to reduce the influence of unreliable or non-speech segments. To fuse modalities, we explore two fusion strategies: a Directed Cross-Modal Mixture-of-Experts Fusion Strategy that learns interactions between modalities with adaptive weighting, and a Reliability-Aware Audio-Visual Fusion Strategy that combines visual features at the frame-level while using audio as complementary context. The results are reported on the Aff-Wild2 dataset following the 10th Affective Behavior Analysis in-the-Wild (ABAW) challenge protocol. Experiments demonstrate that the proposed multimodal fusion strategy achieves a Concordance Correlation Coefficient (CCC) of 0.658 on the Aff-Wild2 development set.
SUN Team's Contribution to ABAW 2024 Competition: Audio-visual Valence-Arousal Estimation and Expression Recognition
Mar 19, 2024



As emotions play a central role in human communication, automatic emotion recognition has attracted increasing attention in the last two decades. While multimodal systems enjoy high performances on lab-controlled data, they are still far from providing ecological validity on non-lab-controlled, namely 'in-the-wild' data. This work investigates audiovisual deep learning approaches for emotion recognition in-the-wild problem. We particularly explore the effectiveness of architectures based on fine-tuned Convolutional Neural Networks (CNN) and Public Dimensional Emotion Model (PDEM), for video and audio modality, respectively. We compare alternative temporal modeling and fusion strategies using the embeddings from these multi-stage trained modality-specific Deep Neural Networks (DNN). We report results on the AffWild2 dataset under Affective Behavior Analysis in-the-Wild 2024 (ABAW'24) challenge protocol.
An Audio-Video Deep and Transfer Learning Framework for Multimodal Emotion Recognition in the wild
Oct 20, 2020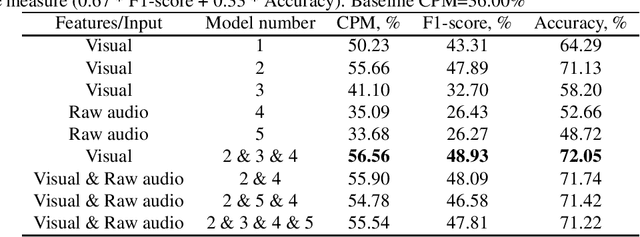
In this paper, we present our contribution to ABAW facial expression challenge. We report the proposed system and the official challenge results adhering to the challenge protocol. Using end-to-end deep learning and benefiting from transfer learning approaches, we reached a test set challenge performance measure of 42.10%.