 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Connectivity in Centroid Clustering
Oct 11, 2020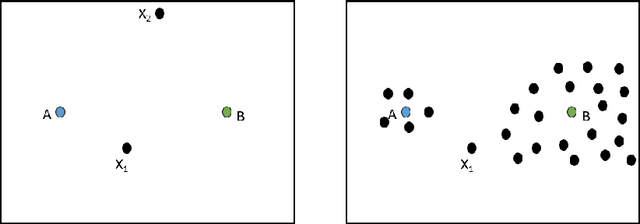
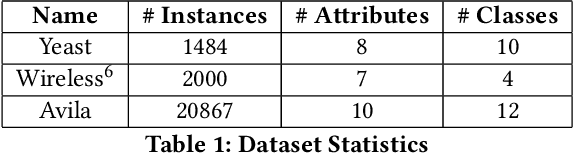
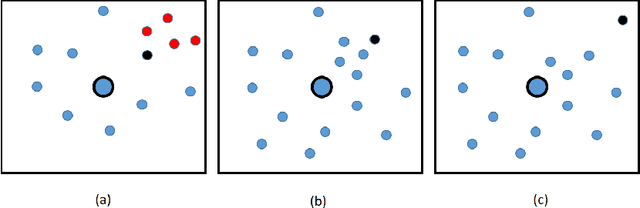
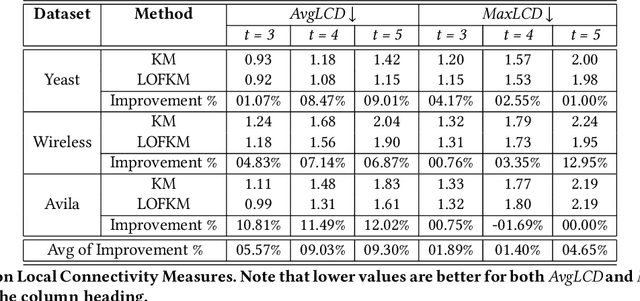
Clustering is a fundamental task in unsupervised learning, one that targets to group a dataset into clusters of similar objects. There has been recent interest in embedding normative considerations around fairness within clustering formulations. In this paper, we propose 'local connectivity' as a crucial factor in assessing membership desert in centroid clustering. We use local connectivity to refer to the support offered by the local neighborhood of an object towards supporting its membership to the cluster in question. We motivate the need to consider local connectivity of objects in cluster assignment, and provide ways to quantify local connectivity in a given clustering. We then exploit concepts from density-based clustering and devise LOFKM, a clustering method that seeks to deepen local connectivity in clustering outputs, while staying within the framework of centroid clustering. Through an empirical evaluation over real-world datasets, we illustrate that LOFKM achieves notable improvements in local connectivity at reasonable costs to clustering quality, illustrating the effectiveness of the method.
Representativity Fairness in Clustering
Oct 11, 2020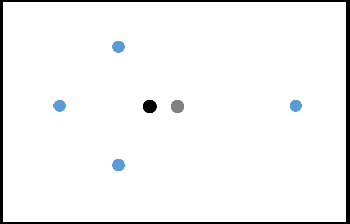
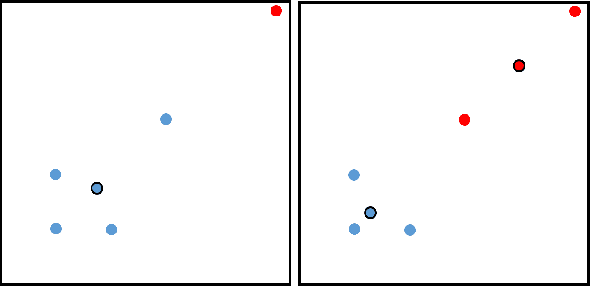
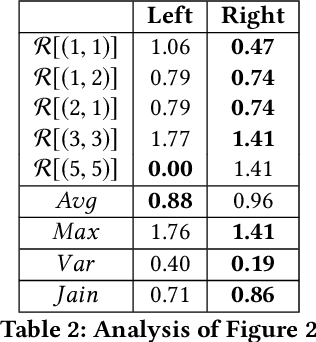
Incorporating fairness constructs into machine learning algorithms is a topic of much societal importance and recent interest. Clustering, a fundamental task in unsupervised learning that manifests across a number of web data scenarios, has also been subject of attention within fair ML research. In this paper, we develop a novel notion of fairness in clustering, called representativity fairness. Representativity fairness is motivated by the need to alleviate disparity across objects' proximity to their assigned cluster representatives, to aid fairer decision making. We illustrate the importance of representativity fairness in real-world decision making scenarios involving clustering and provide ways of quantifying objects' representativity and fairness over it. We develop a new clustering formulation, RFKM, that targets to optimize for representativity fairness along with clustering quality. Inspired by the $K$-Means framework, RFKM incorporates novel loss terms to formulate an objective function. The RFKM objective and optimization approach guides it towards clustering configurations that yield higher representativity fairness. Through an empirical evaluation over a variety of public datasets, we establish the effectiveness of our method. We illustrate that we are able to significantly improve representativity fairness at only marginal impact to clustering quality.
Whither Fair Clustering?
Jul 08, 2020Within the relatively busy area of fair machine learning that has been dominated by classification fairness research, fairness in clustering has started to see some recent attention. In this position paper, we assess the existing work in fair clustering and observe that there are several directions that are yet to be explored, and postulate that the state-of-the-art in fair clustering has been quite parochial in outlook. We posit that widening the normative principles to target for, characterizing shortfalls where the target cannot be achieved fully, and making use of knowledge of downstream processes can significantly widen the scope of research in fair clustering research. At a time when clustering and unsupervised learning are being increasingly used to make and influence decisions that matter significantly to human lives, we believe that widening the ambit of fair clustering is of immense significance.
Fair Outlier Detection
May 20, 2020
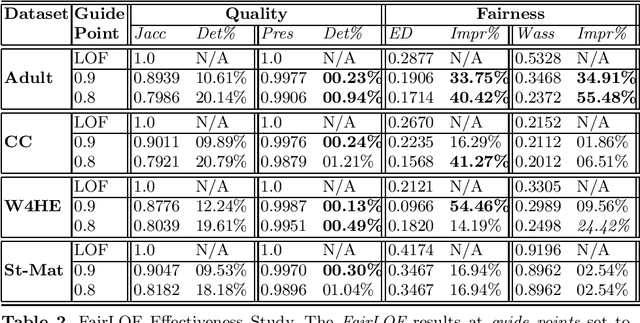
An outlier detection method may be considered fair over specified sensitive attributes if the results of outlier detection are not skewed towards particular groups defined on such sensitive attributes. In this task, we consider, for the first time to our best knowledge, the task of fair outlier detection. In this work, we consider the task of fair outlier detection over multiple multi-valued sensitive attributes (e.g., gender, race, religion, nationality, marital status etc.). We propose a fair outlier detection method, FairLOF, that is inspired by the popular LOF formulation for neighborhood-based outlier detection. We outline ways in which unfairness could be induced within LOF and develop three heuristic principles to enhance fairness, which form the basis of the FairLOF method. Being a novel task, we develop an evaluation framework for fair outlier detection, and use that to benchmark FairLOF on quality and fairness of results. Through an extensive empirical evaluation over real-world datasets, we illustrate that FairLOF is able to achieve significant improvements in fairness at sometimes marginal degradations on result quality as measured against the fairness-agnostic LOF method.
Unsupervised Separation of Native and Loanwords for Malayalam and Telugu
Feb 12, 2020
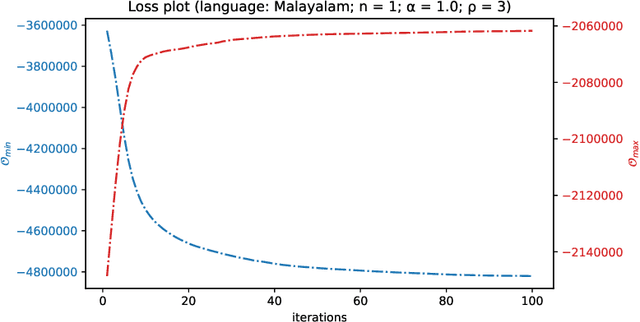
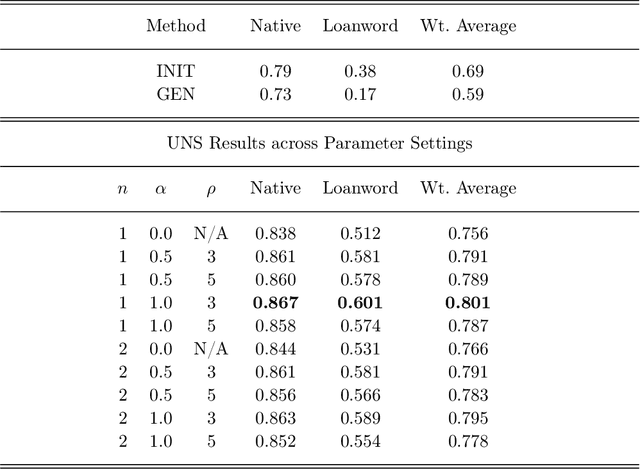
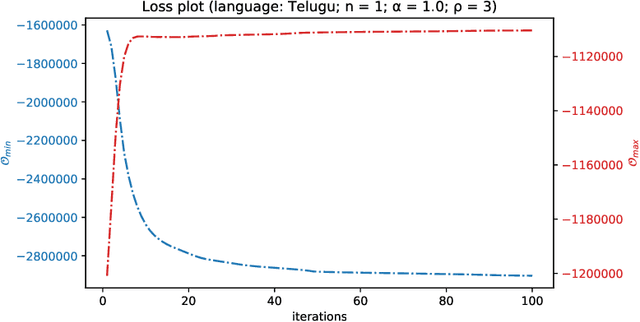
Quite often, words from one language are adopted within a different language without translation; these words appear in transliterated form in text written in the latter language. This phenomenon is particularly widespread within Indian languages where many words are loaned from English. In this paper, we address the task of identifying loanwords automatically and in an unsupervised manner, from large datasets of words from agglutinative Dravidian languages. We target two specific languages from the Dravidian family, viz., Malayalam and Telugu. Based on familiarity with the languages, we outline an observation that native words in both these languages tend to be characterized by a much more versatile stem - stem being a shorthand to denote the subword sequence formed by the first few characters of the word - than words that are loaned from other languages. We harness this observation to build an objective function and an iterative optimization formulation to optimize for it, yielding a scoring of each word's nativeness in the process. Through an extensive empirical analysis over real-world datasets from both Malayalam and Telugu, we illustrate the effectiveness of our method in quantifying nativeness effectively over available baselines for the task.
Fairness in Clustering with Multiple Sensitive Attributes
Oct 11, 2019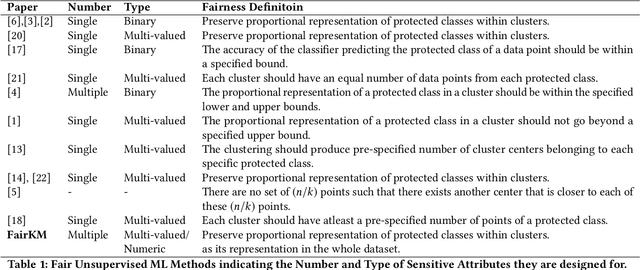
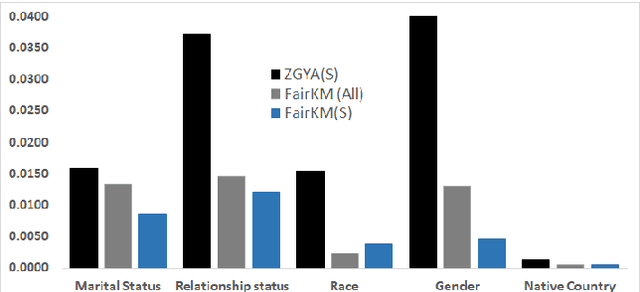

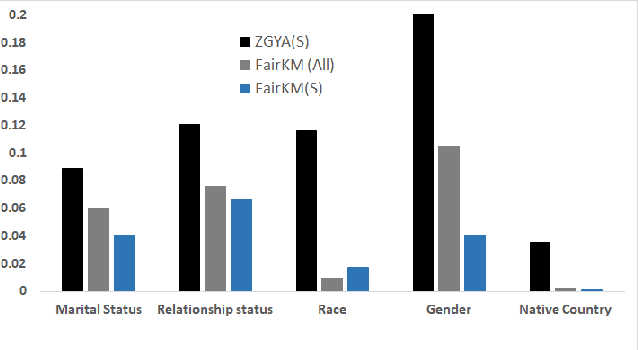
A clustering may be considered as fair on pre-specified sensitive attributes if the proportions of sensitive attribute groups in each cluster reflect that in the dataset. In this paper, we consider the task of fair clustering for scenarios involving multiple multi-valued or numeric sensitive attributes. We propose a fair clustering method, FairKM (Fair K-Means), that is inspired by the popular K-Means clustering formulation. We outline a computational notion of fairness which is used along with a cluster coherence objective, to yield the FairKM clustering method. We empirically evaluate our approach, wherein we quantify both the quality and fairness of clusters, over real-world datasets. Our experimental evaluation illustrates that the clusters generated by FairKM fare significantly better on both clustering quality and fair representation of sensitive attribute groups compared to the clusters from a state-of-the-art baseline fair clustering method.
On the Coherence of Fake News Articles
Jun 26, 2019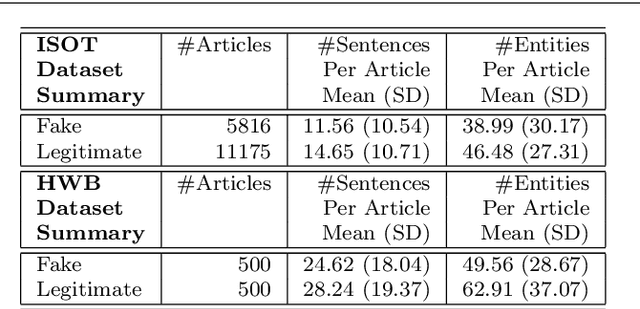
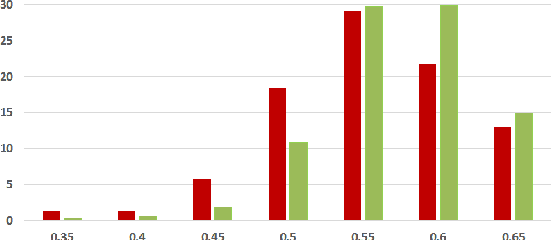
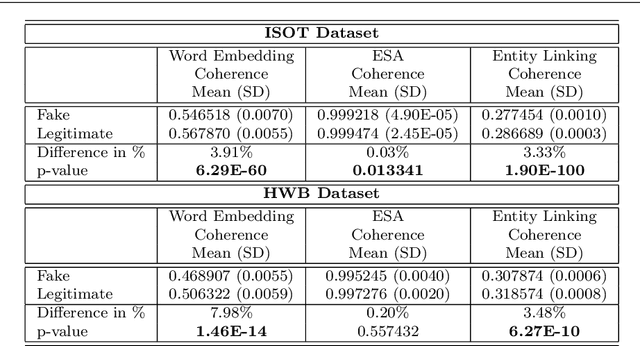
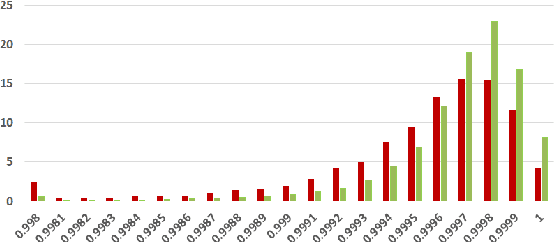
The generation and spread of fake news within new and online media sources is emerging as a phenomenon of high societal significance. Combating them using data-driven analytics has been attracting much recent scholarly interest. In this study, we analyze the textual coherence of fake news articles vis-a-vis legitimate ones. We develop three computational formulations of textual coherence drawing upon the state-of-the-art methods in natural language processing and data science. Two real-world datasets from widely different domains which have fake/legitimate article labellings are then analyzed with respect to textual coherence. We observe apparent differences in textual coherence across fake and legitimate news articles, with fake news articles consistently scoring lower on coherence as compared to legitimate news ones. While the relative coherence shortfall of fake news articles as compared to legitimate ones form the main observation from our study, we analyze several aspects of the differences and outline potential avenues of further inquiry.
Warping Resilient Time Series Embeddings
Jun 12, 2019
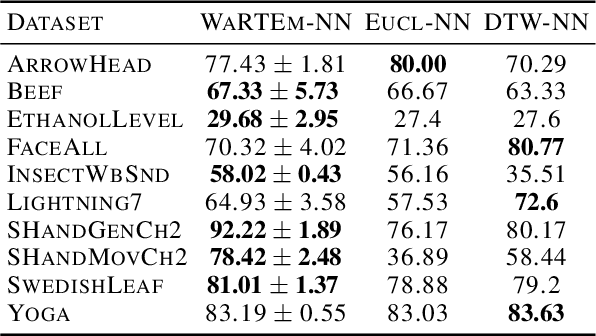
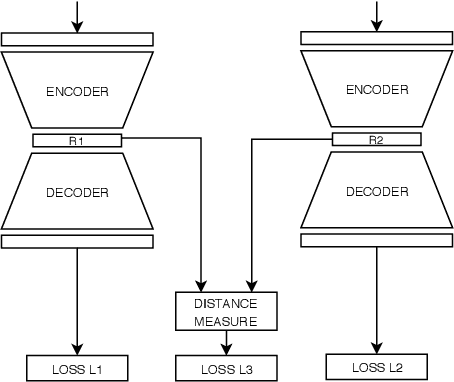
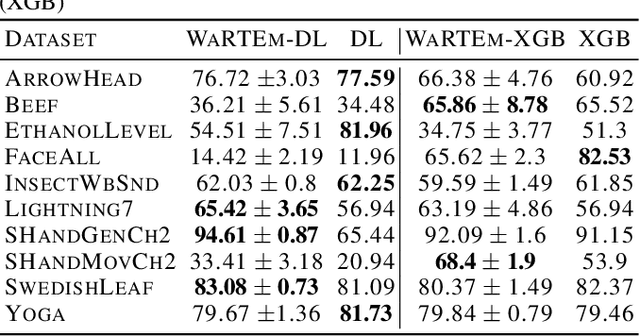
Time series are ubiquitous in real world problems and computing distance between two time series is often required in several learning tasks. Computing similarity between time series by ignoring variations in speed or warping is often encountered and dynamic time warping (DTW) is the state of the art. However DTW is not applicable in algorithms which require kernel or vectors. In this paper, we propose a mechanism named WaRTEm to generate vector embeddings of time series such that distance measures in the embedding space exhibit resilience to warping. Therefore, WaRTEm is more widely applicable than DTW. WaRTEm is based on a twin auto-encoder architecture and a training strategy involving warping operators for generating warping resilient embeddings for time series datasets. We evaluate the performance of WaRTEm and observed more than $20\%$ improvement over DTW in multiple real-world datasets.
Topic-Specific Sentiment Analysis Can Help Identify Political Ideology
Oct 30, 2018
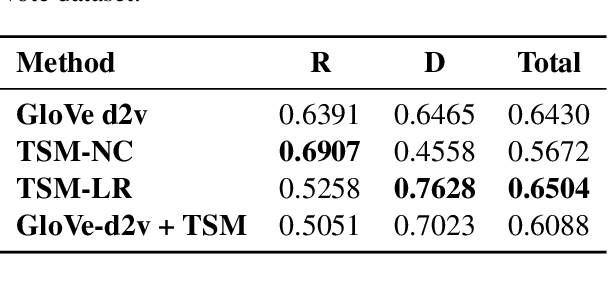
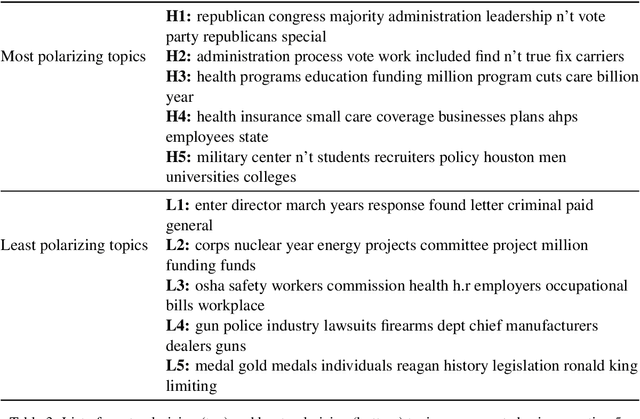
Ideological leanings of an individual can often be gauged by the sentiment one expresses about different issues. We propose a simple framework that represents a political ideology as a distribution of sentiment polarities towards a set of topics. This representation can then be used to detect ideological leanings of documents (speeches, news articles, etc.) based on the sentiments expressed towards different topics. Experiments performed using a widely used dataset show the promise of our proposed approach that achieves comparable performance to other methods despite being much simpler and more interpretable.
Unsupervised Separation of Transliterable and Native Words for Malayalam
Mar 26, 2018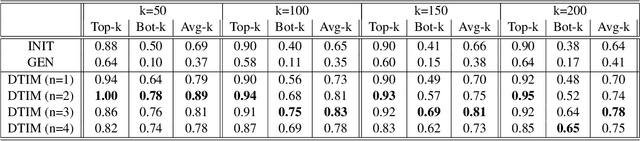
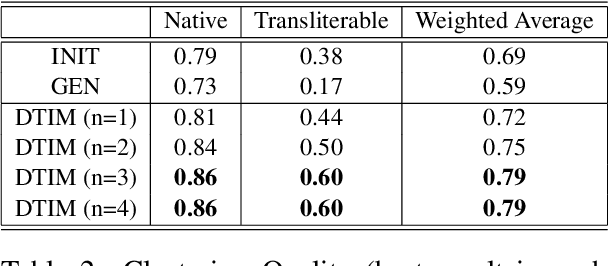
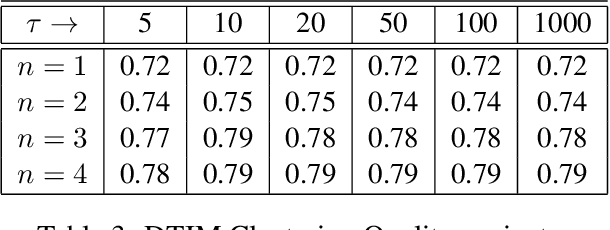
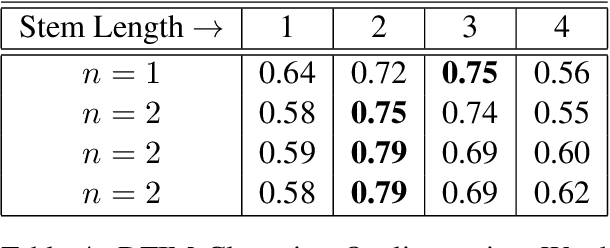
Differentiating intrinsic language words from transliterable words is a key step aiding text processing tasks involving different natural languages. We consider the problem of unsupervised separation of transliterable words from native words for text in Malayalam language. Outlining a key observation on the diversity of characters beyond the word stem, we develop an optimization method to score words based on their nativeness. Our method relies on the usage of probability distributions over character n-grams that are refined in step with the nativeness scorings in an iterative optimization formulation. Using an empirical evaluation, we illustrate that our method, DTIM, provides significant improvements in nativeness scoring for Malayalam, establishing DTIM as the preferred method for the task.