 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Initial Exploration Problem in Knowledge Graph Exploration
Feb 24, 2026Knowledge Graphs (KGs) enable the integration and representation of complex information across domains, but their semantic richness and structural complexity create substantial barriers for lay users without expertise in semantic web technologies. When encountering an unfamiliar KG, such users face a distinct orientation challenge: they do not know what questions are possible, how the knowledge is structured, or how to begin exploration. This paper identifies and theorises this phenomenon as the Initial Exploration Problem (IEP). Drawing on theories from information behaviour and human-computer interaction, including ASK, exploratory search, information foraging, and cognitive load theory, we develop a conceptual framing of the IEP characterised by three interdependent barriers: scope uncertainty, ontology opacity, and query incapacity. We argue that these barriers converge at the moment of first contact, distinguishing the IEP from related concepts that presuppose an existing starting point or information goal. Analysing KG exploration interfaces at the level of interaction primitives, we suggest that many systems rely on epistemic assumptions that do not hold at first contact. This reveals a structural gap in the design space: the absence of interaction primitives for scope revelation, mechanisms that communicate what a KG contains without requiring users to formulate queries or interpret ontological structures. In articulating the IEP, this paper provides a theoretical lens for evaluating KG interfaces and for designing entry-point scaffolding that supports initial exploration.
Extending TWIG: Zero-Shot Predictive Hyperparameter Selection for KGEs based on Graph Structure
Dec 19, 2024Knowledge Graphs (KGs) have seen increasing use across various domains -- from biomedicine and linguistics to general knowledge modelling. In order to facilitate the analysis of knowledge graphs, Knowledge Graph Embeddings (KGEs) have been developed to automatically analyse KGs and predict new facts based on the information in a KG, a task called "link prediction". Many existing studies have documented that the structure of a KG, KGE model components, and KGE hyperparameters can significantly change how well KGEs perform and what relationships they are able to learn. Recently, the Topologically-Weighted Intelligence Generation (TWIG) model has been proposed as a solution to modelling how each of these elements relate. In this work, we extend the previous research on TWIG and evaluate its ability to simulate the output of the KGE model ComplEx in the cross-KG setting. Our results are twofold. First, TWIG is able to summarise KGE performance on a wide range of hyperparameter settings and KGs being learned, suggesting that it represents a general knowledge of how to predict KGE performance from KG structure. Second, we show that TWIG can successfully predict hyperparameter performance on unseen KGs in the zero-shot setting. This second observation leads us to propose that, with additional research, optimal hyperparameter selection for KGE models could be determined in a pre-hoc manner using TWIG-like methods, rather than by using a full hyperparameter search.
A Survey on Knowledge Graph Structure and Knowledge Graph Embeddings
Dec 13, 2024


Knowledge Graphs (KGs) and their machine learning counterpart, Knowledge Graph Embedding Models (KGEMs), have seen ever-increasing use in a wide variety of academic and applied settings. In particular, KGEMs are typically applied to KGs to solve the link prediction task; i.e. to predict new facts in the domain of a KG based on existing, observed facts. While this approach has been shown substantial power in many end-use cases, it remains incompletely characterised in terms of how KGEMs react differently to KG structure. This is of particular concern in light of recent studies showing that KG structure can be a significant source of bias as well as partially determinant of overall KGEM performance. This paper seeks to address this gap in the state-of-the-art. This paper provides, to the authors' knowledge, the first comprehensive survey exploring established relationships of Knowledge Graph Embedding Models and Graph structure in the literature. It is the hope of the authors that this work will inspire further studies in this area, and contribute to a more holistic understanding of KGs, KGEMs, and the link prediction task.
AI Cards: Towards an Applied Framework for Machine-Readable AI and Risk Documentation Inspired by the EU AI Act
Jun 26, 2024



With the upcoming enforcement of the EU AI Act, documentation of high-risk AI systems and their risk management information will become a legal requirement playing a pivotal role in demonstration of compliance. Despite its importance, there is a lack of standards and guidelines to assist with drawing up AI and risk documentation aligned with the AI Act. This paper aims to address this gap by providing an in-depth analysis of the AI Act's provisions regarding technical documentation, wherein we particularly focus on AI risk management. On the basis of this analysis, we propose AI Cards as a novel holistic framework for representing a given intended use of an AI system by encompassing information regarding technical specifications, context of use, and risk management, both in human- and machine-readable formats. While the human-readable representation of AI Cards provides AI stakeholders with a transparent and comprehensible overview of the AI use case, its machine-readable specification leverages on state of the art Semantic Web technologies to embody the interoperability needed for exchanging documentation within the AI value chain. This brings the flexibility required for reflecting changes applied to the AI system and its context, provides the scalability needed to accommodate potential amendments to legal requirements, and enables development of automated tools to assist with legal compliance and conformity assessment tasks. To solidify the benefits, we provide an exemplar AI Card for an AI-based student proctoring system and further discuss its potential applications within and beyond the context of the AI Act.
TWIG: Towards pre-hoc Hyperparameter Optimisation and Cross-Graph Generalisation via Simulated KGE Models
Feb 08, 2024



In this paper we introduce TWIG (Topologically-Weighted Intelligence Generation), a novel, embedding-free paradigm for simulating the output of KGEs that uses a tiny fraction of the parameters. TWIG learns weights from inputs that consist of topological features of the graph data, with no coding for latent representations of entities or edges. Our experiments on the UMLS dataset show that a single TWIG neural network can predict the results of state-of-the-art ComplEx-N3 KGE model nearly exactly on across all hyperparameter configurations. To do this it uses a total of 2590 learnable parameters, but accurately predicts the results of 1215 different hyperparameter combinations with a combined cost of 29,322,000 parameters. Based on these results, we make two claims: 1) that KGEs do not learn latent semantics, but only latent representations of structural patterns; 2) that hyperparameter choice in KGEs is a deterministic function of the KGE model and graph structure. We further hypothesise that, as TWIG can simulate KGEs without embeddings, that node and edge embeddings are not needed to learn to accurately predict new facts in KGs. Finally, we formulate all of our findings under the umbrella of the ``Structural Generalisation Hypothesis", which suggests that ``twiggy" embedding-free / data-structure-based learning methods can allow a single neural network to simulate KGE performance, and perhaps solve the Link Prediction task, across many KGs from diverse domains and with different semantics.
A semantic web approach to uplift decentralized household energy data
Aug 26, 2022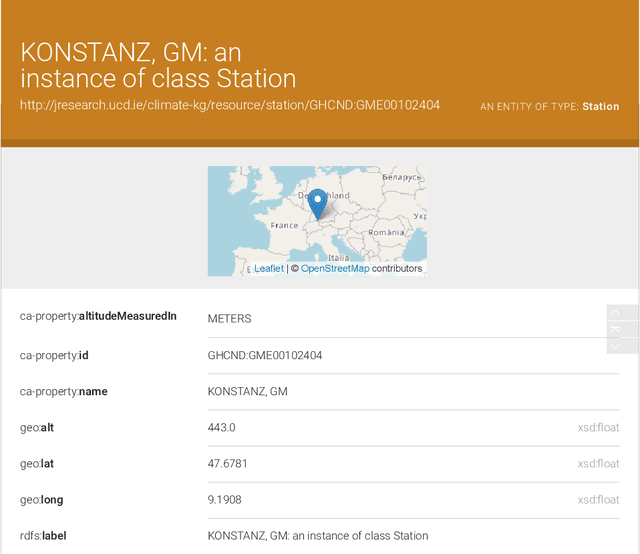

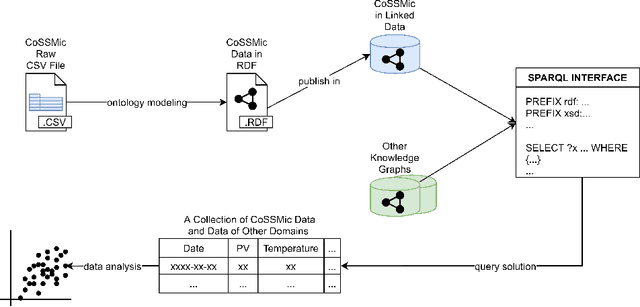

In a decentralized household energy system comprised of various devices such as home appliances, electric vehicles, and solar panels, end-users are able to dig deeper into the system's details and further achieve energy sustainability if they are presented with data on the electric energy consumption and production at the granularity of the device. However, many databases in this field are siloed from other domains, including solely information pertaining to energy. This may result in the loss of information (e.g. weather) on each device's energy use. Meanwhile, a large number of these datasets have been extensively used in computational modeling techniques such as machine learning models. While such computational approaches achieve great accuracy and performance by concentrating only on a local view of datasets, model reliability cannot be guaranteed since such models are very vulnerable to data input fluctuations when information omission is taken into account. This article tackles the data isolation issue in the field of smart energy systems by examining Semantic Web methods on top of a household energy system. We offer an ontology-based approach for managing decentralized data at the device-level resolution in a system. As a consequence, the scope of the data associated with each device may easily be expanded in an interoperable manner throughout the Web, and additional information, such as weather, can be obtained from the Web, provided that the data is organized according to W3C standards.
Poisoning Knowledge Graph Embeddings via Relation Inference Patterns
Nov 11, 2021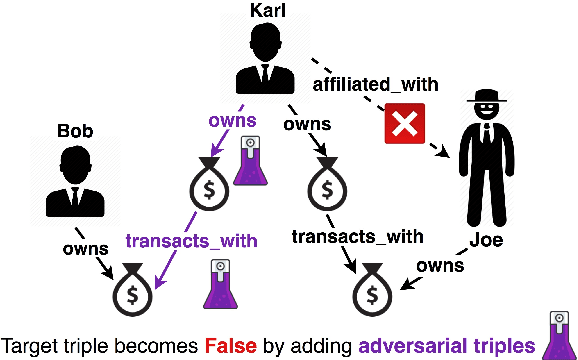

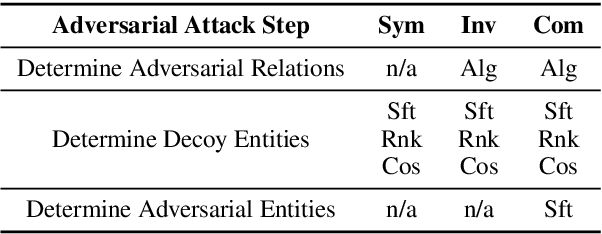
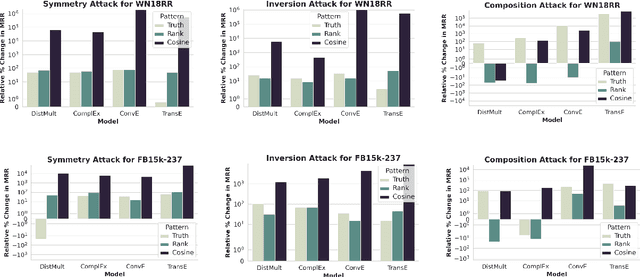
We study the problem of generating data poisoning attacks against Knowledge Graph Embedding (KGE) models for the task of link prediction in knowledge graphs. To poison KGE models, we propose to exploit their inductive abilities which are captured through the relationship patterns like symmetry, inversion and composition in the knowledge graph. Specifically, to degrade the model's prediction confidence on target facts, we propose to improve the model's prediction confidence on a set of decoy facts. Thus, we craft adversarial additions that can improve the model's prediction confidence on decoy facts through different inference patterns. Our experiments demonstrate that the proposed poisoning attacks outperform state-of-art baselines on four KGE models for two publicly available datasets. We also find that the symmetry pattern based attacks generalize across all model-dataset combinations which indicates the sensitivity of KGE models to this pattern.
Adversarial Attacks on Knowledge Graph Embeddings via Instance Attribution Methods
Nov 04, 2021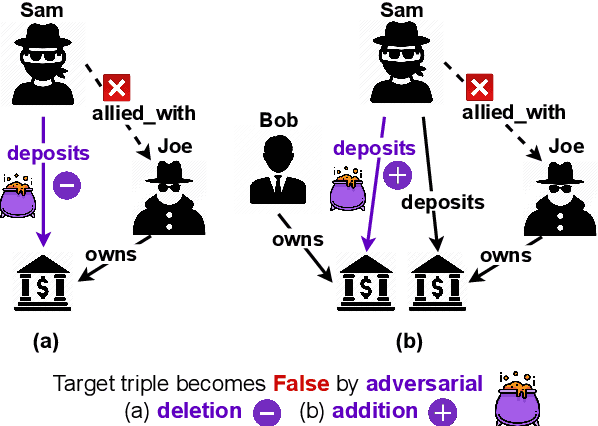

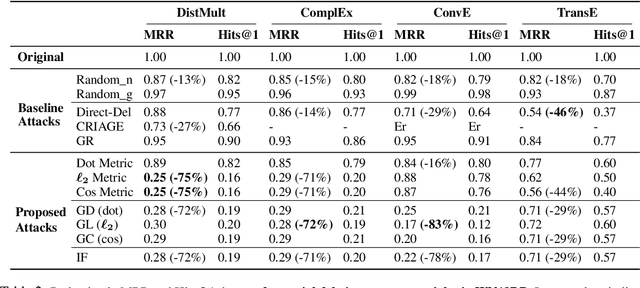
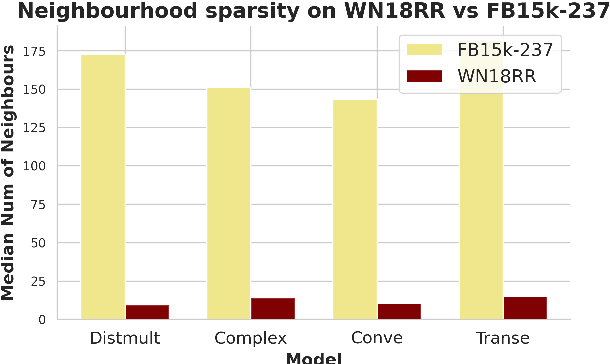
Despite the widespread use of Knowledge Graph Embeddings (KGE), little is known about the security vulnerabilities that might disrupt their intended behaviour. We study data poisoning attacks against KGE models for link prediction. These attacks craft adversarial additions or deletions at training time to cause model failure at test time. To select adversarial deletions, we propose to use the model-agnostic instance attribution methods from Interpretable Machine Learning, which identify the training instances that are most influential to a neural model's predictions on test instances. We use these influential triples as adversarial deletions. We further propose a heuristic method to replace one of the two entities in each influential triple to generate adversarial additions. Our experiments show that the proposed strategies outperform the state-of-art data poisoning attacks on KGE models and improve the MRR degradation due to the attacks by up to 62% over the baselines.
Using Mapping Languages for Building Legal Knowledge Graphs from XML Files
Nov 18, 2019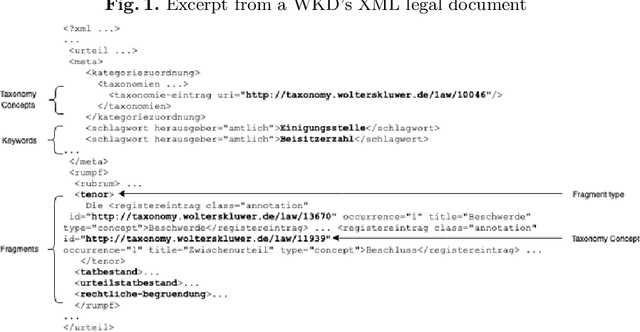
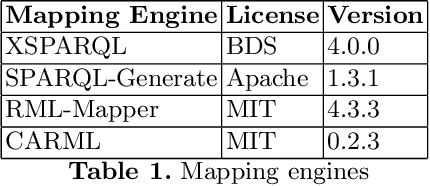
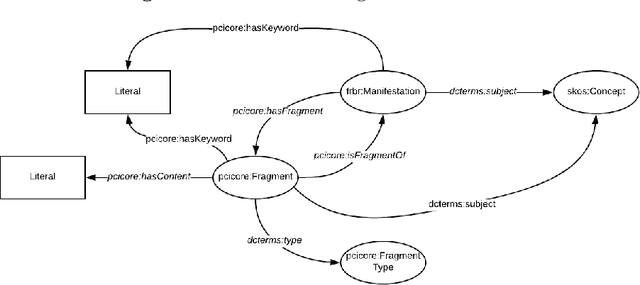
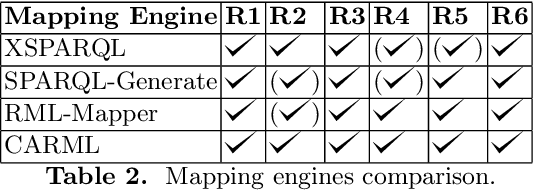
This paper presents our experience on building RDF knowledge graphs for an industrial use case in the legal domain. The information contained in legal information systems are often accessed through simple keyword interfaces and presented as a simple list of hits. In order to improve search accuracy one may avail of knowledge graphs, where the semantics of the data can be made explicit. Significant research effort has been invested in the area of building knowledge graphs from semi-structured text documents, such as XML, with the prevailing approach being the use of mapping languages. In this paper, we present a semantic model for representing legal documents together with an industrial use case. We also present a set of use case requirements based on the proposed semantic model, which are used to compare and discuss the use of state-of-the-art mapping languages for building knowledge graphs for legal data.