 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross Modality Image Translation In Medical Imaging Using Generative Frameworks
May 13, 2026Medical image-to-image (I2I) translation enables virtual scanning, i.e. the synthesis of a target imaging modality from a source one without additional acquisitions. Despite growing interest, most proposed methods operate on 2D slices, are evaluated on isolated tasks with different experimental set-ups and lack clinical validation. The primary contribution of this work is a reproducible, standardized comparative evaluation of 3D I2I translation methods in oncological imaging, designed to standardize preprocessing, splitting, inference, and multi-level evaluation across heterogeneous clinical tasks. Within this framework, we compare seven generative models, three Generative Adversarial Networks (GANs: Pix2Pix, CycleGAN, SRGAN) and four latent generative models (Latent Diffusion Model, Latent Diffusion Model+ControlNet, Brownian Bridge, Flow Matching), across eleven datasets spanning three anatomical regions (head/neck, lung, pelvis) and four translation directions (cone-beam CT to CT, MRI to CT, CT to PET, MRI T2-weighted to T2-FLAIR), for a total of 77 experiments under uniform training, inference, and evaluation conditions. The results show that GANs outperform latent generative models across all tasks, with SRGAN achieving statistically significant superiority. Our lesion-level analysis reveals that all models struggle with small lesions and that, in CT to PET synthesis, models reproduce lesion shape more reliably than absolute uptake-related intensity. We also performed a Visual Turing test administered to 17 physicians, including 15 radiologists, which shows near-chance classification accuracy (56.7%), confirming that synthetic volumes are largely indistinguishable from real acquisitions, while exposing a dissociation between quantitative metrics and clinical preference.
MedCoDi-M: A Multi-Prompt Foundation Model for Multimodal Medical Data Generation
Jan 08, 2025



Artificial Intelligence is revolutionizing medical practice, enhancing diagnostic accuracy and healthcare delivery. However, its adaptation in medical settings still faces significant challenges, related to data availability and privacy constraints. Synthetic data has emerged as a promising solution to mitigate these issues, addressing data scarcity while preserving privacy. Recently, Latent Diffusion Models have emerged as a powerful tool for generating high-quality synthetic data. Meanwhile, the integration of different modalities has gained interest, emphasizing the need of models capable of handle multimodal medical data.Existing approaches struggle to integrate complementary information and lack the ability to generate modalities simultaneously. To address this challenge, we present MedCoDi-M, a 6.77-billion-parameter model, designed for multimodal medical data generation, that, following Foundation Model paradigm, exploits contrastive learning and large quantity of data to build a shared latent space which capture the relationships between different data modalities. Further, we introduce the Multi-Prompt training technique, which significantly boosts MedCoDi-M's generation under different settings. We extensively validate MedCoDi-M: first we benchmark it against five competitors on the MIMIC-CXR dataset, a state-of-the-art dataset for Chest X-ray and radiological report generation. Secondly, we perform a Visual Turing Test with expert radiologists to assess the realism and clinical relevance of the generated data, ensuring alignment with real-world scenarios. Finally, we assess the utility of MedCoDi-M in addressing key challenges in the medical field, such as anonymization, data scarcity and imbalance learning. The results are promising, demonstrating the applicability of MedCoDi-M in medical contexts. Project page is at https://cosbidev.github.io/MedCoDi-M/.
Multimodal Explainability via Latent Shift applied to COVID-19 stratification
Dec 28, 2022



We are witnessing a widespread adoption of artificial intelligence in healthcare. However, most of the advancements in deep learning (DL) in this area consider only unimodal data, neglecting other modalities. Their multimodal interpretation necessary for supporting diagnosis, prognosis and treatment decisions. In this work we present a deep architecture, explainable by design, which jointly learns modality reconstructions and sample classifications using tabular and imaging data. The explanation of the decision taken is computed by applying a latent shift that, simulates a counterfactual prediction revealing the features of each modality that contribute the most to the decision and a quantitative score indicating the modality importance. We validate our approach in the context of COVID-19 pandemic using the AIforCOVID dataset, which contains multimodal data for the early identification of patients at risk of severe outcome. The results show that the proposed method provides meaningful explanations without degrading the classification performance.
AIforCOVID: predicting the clinical outcomes in patients with COVID-19 applying AI to chest-X-rays. An Italian multicentre study
Dec 11, 2020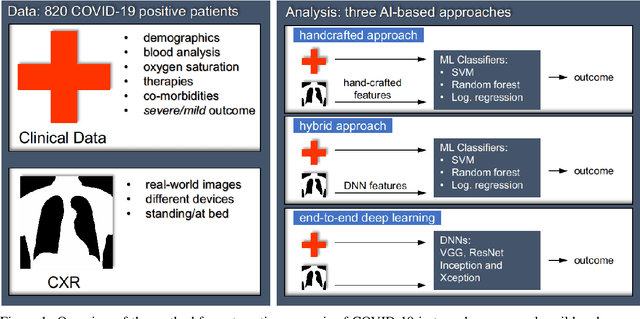
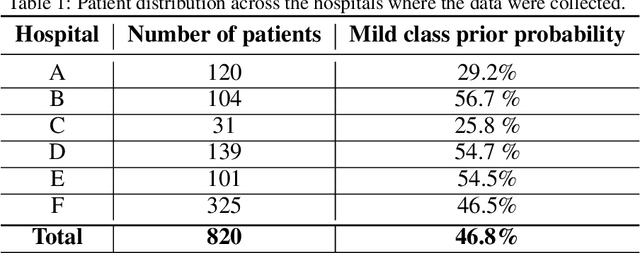
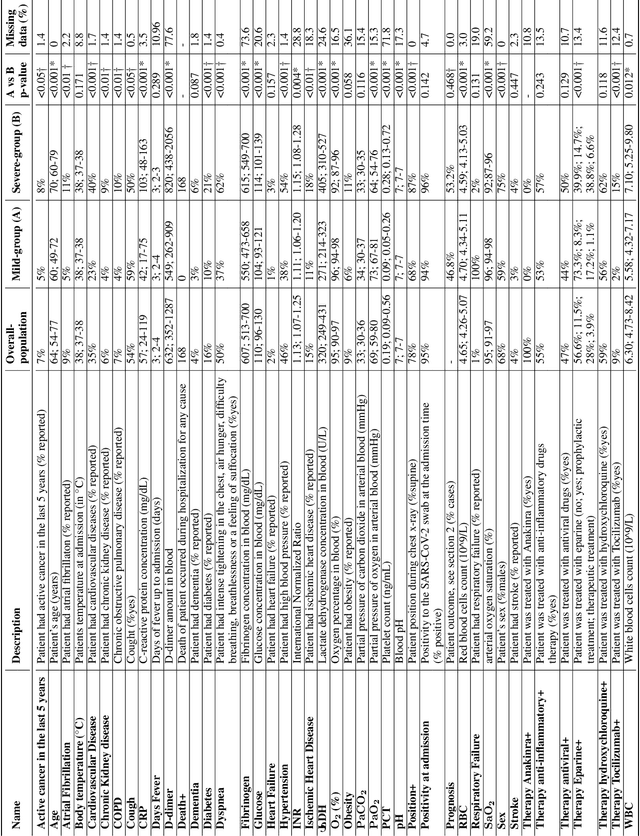
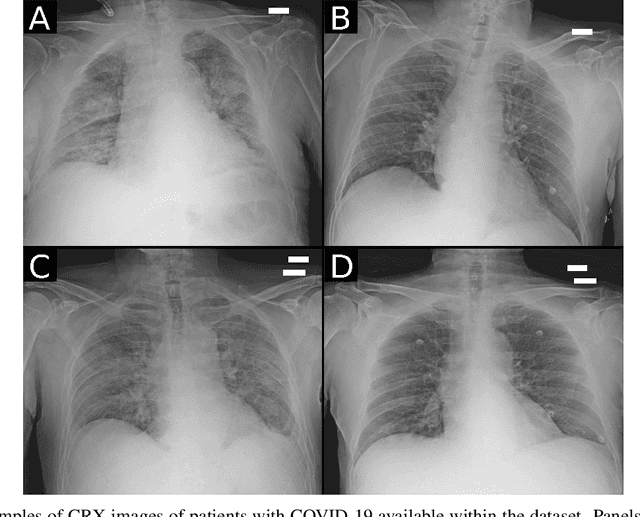
Recent epidemiological data report that worldwide more than 53 million people have been infected by SARS-CoV-2, resulting in 1.3 million deaths. The disease has been spreading very rapidly and few months after the identification of the first infected, shortage of hospital resources quickly became a problem. In this work we investigate whether chest X-ray (CXR) can be used as a possible tool for the early identification of patients at risk of severe outcome, like intensive care or death. CXR is a radiological technique that compared to computed tomography (CT) it is simpler, faster, more widespread and it induces lower radiation dose. We present a dataset including data collected from 820 patients by six Italian hospitals in spring 2020 during the first COVID-19 emergency. The dataset includes CXR images, several clinical attributes and clinical outcomes. We investigate the potential of artificial intelligence to predict the prognosis of such patients, distinguishing between severe and mild cases, thus offering a baseline reference for other researchers and practitioners. To this goal, we present three approaches that use features extracted from CXR images, either handcrafted or automatically by convolutional neuronal networks, which are then integrated with the clinical data. Exhaustive evaluation shows promising performance both in 10-fold and leave-one-centre-out cross-validation, implying that clinical data and images have the potential to provide useful information for the management of patients and hospital resources.