 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Feasibility of Multilingual Grammatical Error Correction with a Single LLM up to 9B parameters: A Comparative Study of 17 Models
May 09, 2025Recent language models can successfully solve various language-related tasks, and many understand inputs stated in different languages. In this paper, we explore the performance of 17 popular models used to correct grammatical issues in texts stated in English, German, Italian, and Swedish when using a single model to correct texts in all those languages. We analyze the outputs generated by these models, focusing on decreasing the number of grammatical errors while keeping the changes small. The conclusions drawn help us understand what problems occur among those models and which models can be recommended for multilingual grammatical error correction tasks. We list six models that improve grammatical correctness in all four languages and show that Gemma 9B is currently the best performing one for the languages considered.
Do Not Change Me: On Transferring Entities Without Modification in Neural Machine Translation -- a Multilingual Perspective
May 09, 2025



Current machine translation models provide us with high-quality outputs in most scenarios. However, they still face some specific problems, such as detecting which entities should not be changed during translation. In this paper, we explore the abilities of popular NMT models, including models from the OPUS project, Google Translate, MADLAD, and EuroLLM, to preserve entities such as URL addresses, IBAN numbers, or emails when producing translations between four languages: English, German, Polish, and Ukrainian. We investigate the quality of popular NMT models in terms of accuracy, discuss errors made by the models, and examine the reasons for errors. Our analysis highlights specific categories, such as emojis, that pose significant challenges for many models considered. In addition to the analysis, we propose a new multilingual synthetic dataset of 36,000 sentences that can help assess the quality of entity transfer across nine categories and four aforementioned languages.
Competency Questions and SPARQL-OWL Queries Dataset and Analysis
Nov 23, 2018
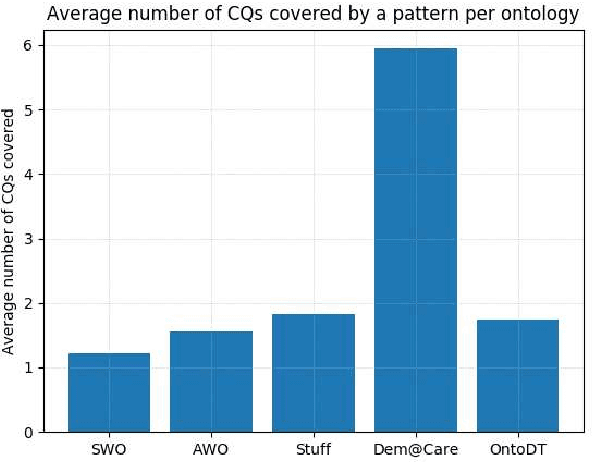
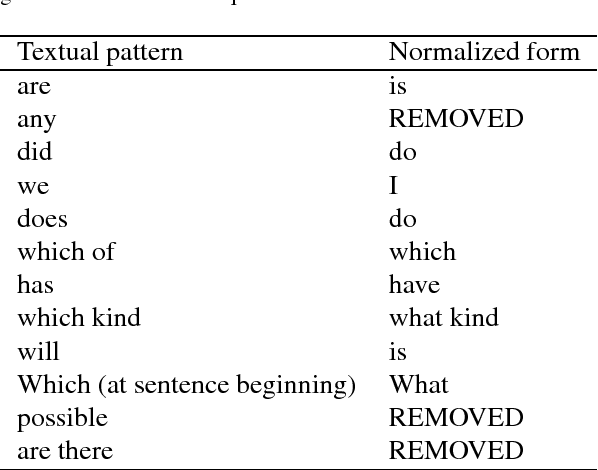
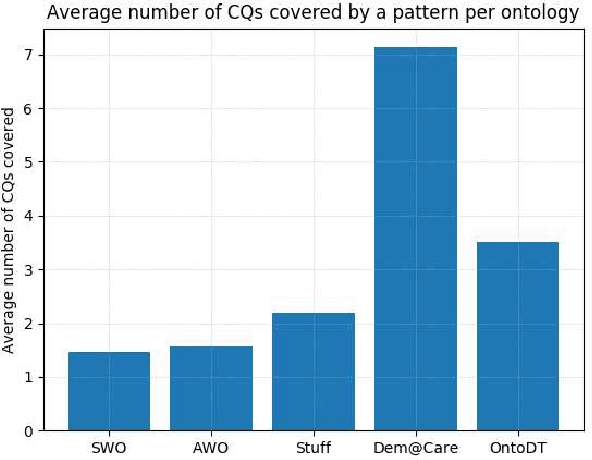
Competency Questions (CQs) are natural language questions outlining and constraining the scope of knowledge represented by an ontology. Despite that CQs are a part of several ontology engineering methodologies, we have observed that the actual publication of CQs for the available ontologies is very limited and even scarcer is the publication of their respective formalisations in terms of, e.g., SPARQL queries. This paper aims to contribute to addressing the engineering shortcomings of using CQs in ontology development, to facilitate wider use of CQs. In order to understand the relation between CQs and the queries over the ontology to test the CQs on an ontology, we gather, analyse, and publicly release a set of 234 CQs and their translations to SPARQL-OWL for several ontologies in different domains developed by different groups. We analysed the CQs in two principal ways. The first stage focused on a linguistic analysis of the natural language text itself, i.e., a lexico-syntactic analysis without any presuppositions of ontology elements, and a subsequent step of semantic analysis in order to find patterns. This increased diversity of CQ sources resulted in a 5-fold increase of hitherto published patterns, to 106 distinct CQ patterns, which have a limited subset of few patterns shared across the CQ sets from the different ontologies. Next, we analysed the relation between the found CQ patterns and the 46 SPARQL-OWL query signatures, which revealed that one CQ pattern may be realised by more than one SPARQL-OWL query signature, and vice versa. We hope that our work will contribute to establishing common practices, templates, automation, and user tools that will support CQ formulation, formalisation, execution, and general management.