 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Counting and Identification of Train Wagons Based on Computer Vision and Deep Learning
Oct 30, 2020
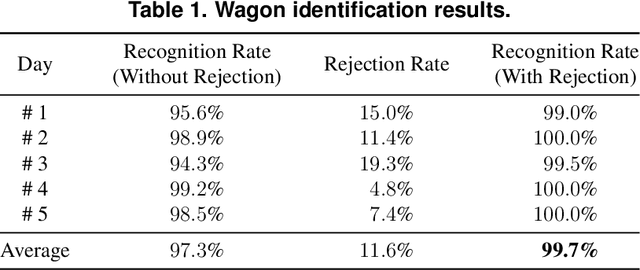


In this work, we present a robust and efficient solution for counting and identifying train wagons using computer vision and deep learning. The proposed solution is cost-effective and can easily replace solutions based on radiofrequency identification (RFID), which are known to have high installation and maintenance costs. According to our experiments, our two-stage methodology achieves impressive results on real-world scenarios, i.e., 100% accuracy in the counting stage and 99.7% recognition rate in the identification one. Moreover, the system is able to automatically reject some of the train wagons successfully counted, as they have damaged identification codes. The results achieved were surprising considering that the proposed system requires low processing power (i.e., it can run in low-end setups) and that we used a relatively small number of images to train our Convolutional Neural Network (CNN) for character recognition. The proposed method is registered, under number BR512020000808-9, with the National Institute of Industrial Property (Brazil).
Towards image-based automatic meter reading in unconstrained scenarios: A robust and efficient approach
Sep 21, 2020


Existing approaches for image-based Automatic Meter Reading (AMR) have been evaluated on images captured in well-controlled scenarios. However, real-world meter reading presents unconstrained scenarios that are way more challenging due to dirt, various lighting conditions, scale variations, in-plane and out-of-plane rotations, among other factors. In this work, we present an end-to-end approach for AMR focusing on unconstrained scenarios. Our main contribution is the insertion of a new stage in the AMR pipeline, called corner detection and counter classification, which enables the counter region to be rectified -- as well as the rejection of illegible/faulty meters -- prior to the recognition stage. We also introduce a publicly available dataset, called Copel-AMR, that contains 12,500 meter images acquired in the field by the service company's employees themselves, including 2,500 images of faulty meters or cases where the reading is illegible due to occlusions. Experimental evaluation demonstrates that the proposed system outperforms six baselines in terms of recognition rate while still being quite efficient. Moreover, as very few reading errors are tolerated in real-world applications, we show that our AMR system achieves impressive recognition rates (i.e., > 99%) when rejecting readings made with lower confidence values.
Deep Learning for Image-based Automatic Dial Meter Reading: Dataset and Baselines
May 08, 2020

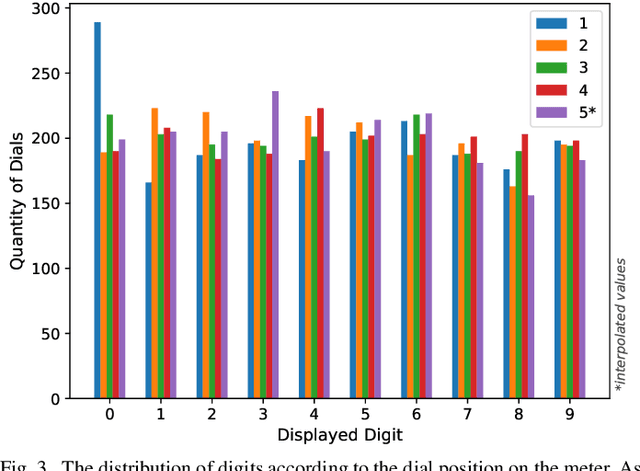

Smart meters enable remote and automatic electricity, water and gas consumption reading and are being widely deployed in developed countries. Nonetheless, there is still a huge number of non-smart meters in operation. Image-based Automatic Meter Reading (AMR) focuses on dealing with this type of meter readings. We estimate that the Energy Company of Paran\'a (Copel), in Brazil, performs more than 850,000 readings of dial meters per month. Those meters are the focus of this work. Our main contributions are: (i) a public real-world dial meter dataset (shared upon request) called UFPR-ADMR; (ii) a deep learning-based recognition baseline on the proposed dataset; and (iii) a detailed error analysis of the main issues present in AMR for dial meters. To the best of our knowledge, this is the first work to introduce deep learning approaches to multi-dial meter reading, and perform experiments on unconstrained images. We achieved a 100.0% F1-score on the dial detection stage with both Faster R-CNN and YOLO, while the recognition rates reached 93.6% for dials and 75.25% for meters using Faster R-CNN (ResNext-101).
Towards an Effective and Efficient Deep Learning Model for COVID-19 Patterns Detection in X-ray Images
Apr 28, 2020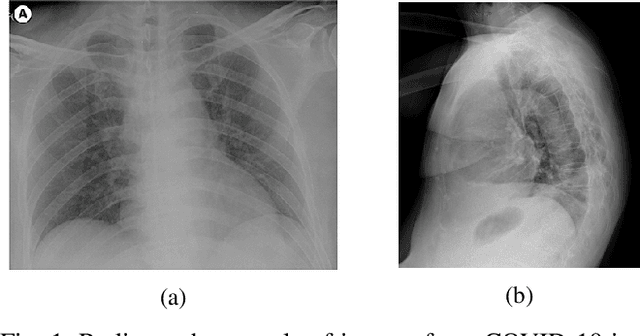
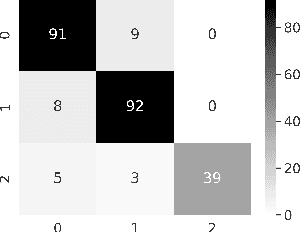
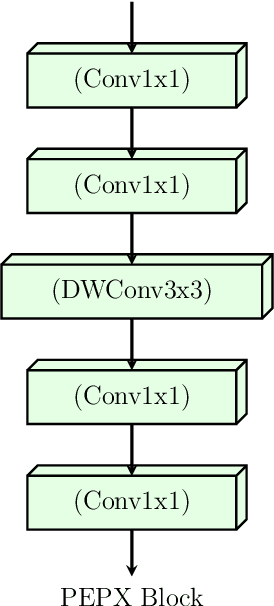
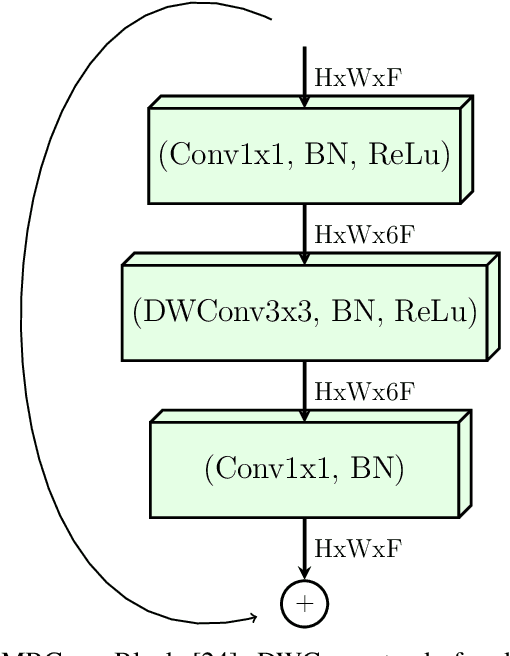
Confronting the pandemic of COVID-19 caused by the new coronavirus, the SARS-CoV-2, is nowadays one of the most prominent challenges of the human species. A key factor in slowing down the virus propagation is the rapid diagnosis and isolation of infected patients. Nevertheless, the standard method for COVID-19 identification, the Reverse transcription polymerase chain reaction (RT-PCR) method, is time-consuming and in short supply due to the pandemic. Researchers around the world have been looking for alternative screening methods. In this context, deep learning applied to chest X-rays of patients has been showing promising results in the identification of COVID-19. Despite their success, the computational cost of these methods remains high, which imposes difficulties in their accessibility and availability. Thus, in this work, we propose to explore and extend the EfficientNet family of models using chest X-rays images to perform COVID-19 detection. As a result, we can produce a high-quality model with an overall accuracy of 93.9%, COVID-19, sensitivity of 96.8% and positive prediction of 100% while having about 30 times fewer parameters than the baseline literature model, 28 and 5 times fewer parameters than the popular VGG16 and ResNet50 architectures, respectively. We believe the reported figures represent state-of-the-art results, both in terms of efficiency and effectiveness, for the COVIDx database, a database comprised of 13,800 X-ray images, 183 of which are from patients affected by COVID-19.
CNN Hyperparameter tuning applied to Iris Liveness Detection
Feb 12, 2020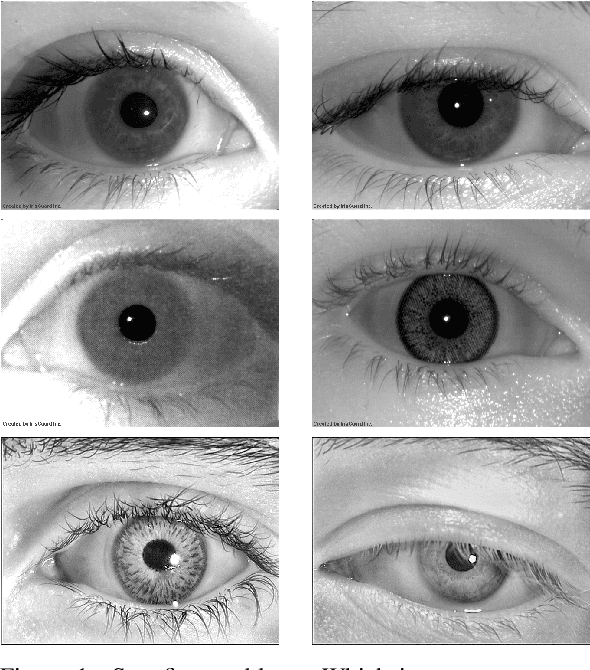
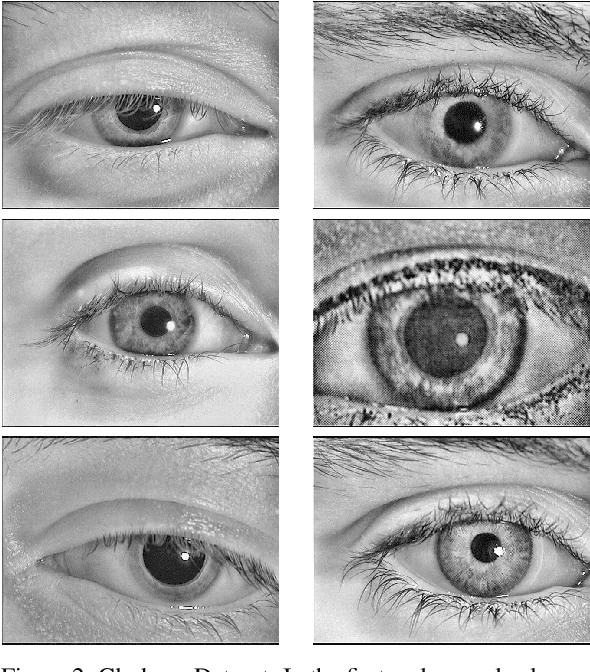
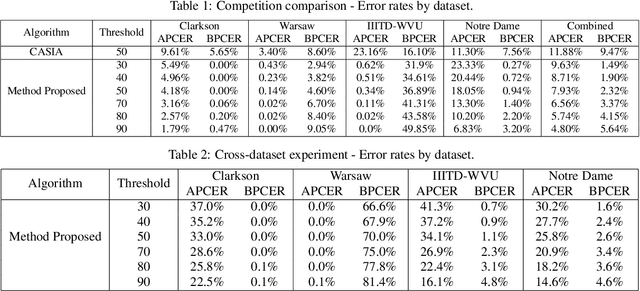
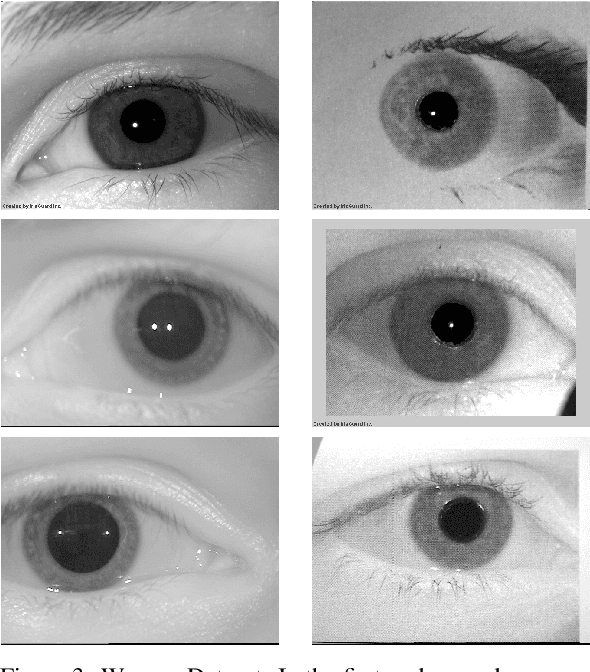
The iris pattern has significantly improved the biometric recognition field due to its high level of stability and uniqueness. Such physical feature has played an important role in security and other related areas. However, presentation attacks, also known as spoofing techniques, can be used to bypass the biometric system with artifacts such as printed images, artificial eyes, and textured contact lenses. To improve the security of these systems, many liveness detection methods have been proposed, and the first Internacional Iris Liveness Detection competition was launched in 2013 to evaluate their effectiveness. In this paper, we propose a hyperparameter tuning of the CASIA algorithm, submitted by the Chinese Academy of Sciences to the third competition of Iris Liveness Detection, in 2017. The modifications proposed promoted an overall improvement, with an 8.48% Attack Presentation Classification Error Rate (APCER) and 0.18% Bonafide Presentation Classification Error Rate (BPCER) for the evaluation of the combined datasets. Other threshold values were evaluated in an attempt to reduce the trade-off between the APCER and the BPCER on the evaluated datasets and worked out successfully.
Unconstrained Periocular Recognition: Using Generative Deep Learning Frameworks for Attribute Normalization
Feb 10, 2020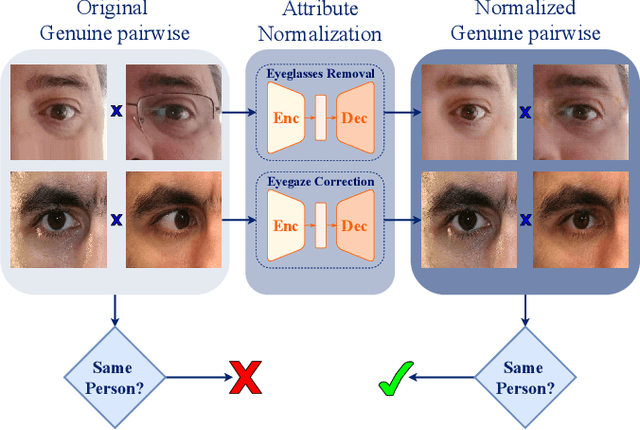
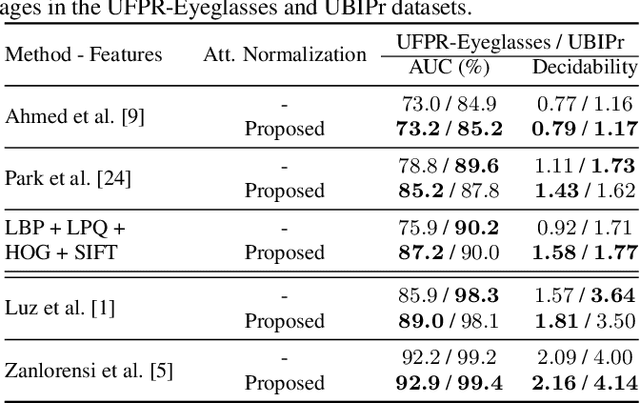

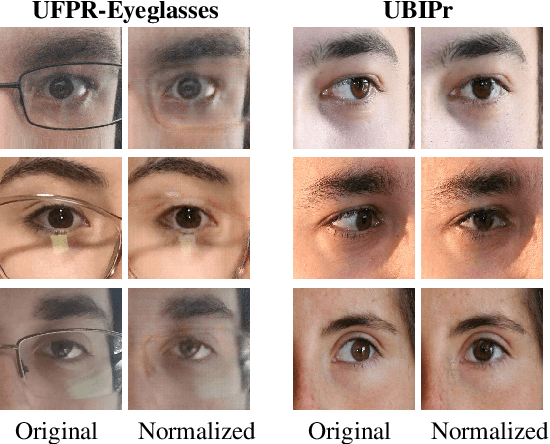
Ocular biometric systems working in unconstrained environments usually face the problem of small within-class compactness caused by the multiple factors that jointly degrade the quality of the obtained data. In this work, we propose an attribute normalization strategy based on deep learning generative frameworks, that reduces the variability of the samples used in pairwise comparisons, without reducing their discriminability. The proposed method can be seen as a preprocessing step that contributes for data regularization and improves the recognition accuracy, being fully agnostic to the recognition strategy used. As proof of concept, we consider the "eyeglasses" and "gaze" factors, comparing the levels of performance of five different recognition methods with/without using the proposed normalization strategy. Also, we introduce a new dataset for unconstrained periocular recognition, composed of images acquired by mobile devices, particularly suited to perceive the impact of "wearing eyeglasses" in recognition effectiveness. Our experiments were performed in two different datasets, and support the usefulness of our attribute normalization scheme to improve the recognition performance.
Ocular Recognition Databases and Competitions: A Survey
Nov 21, 2019
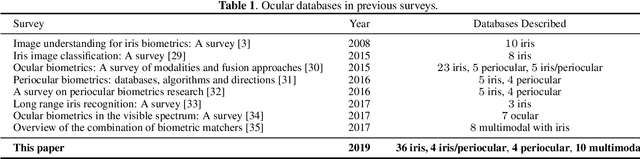
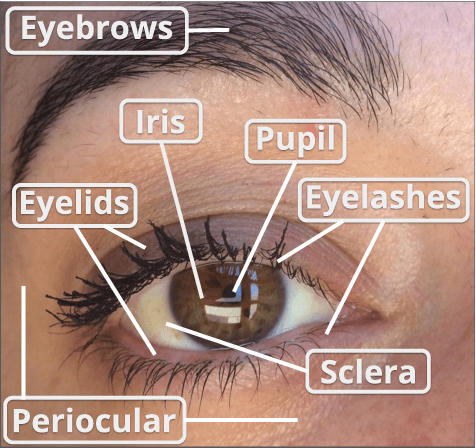
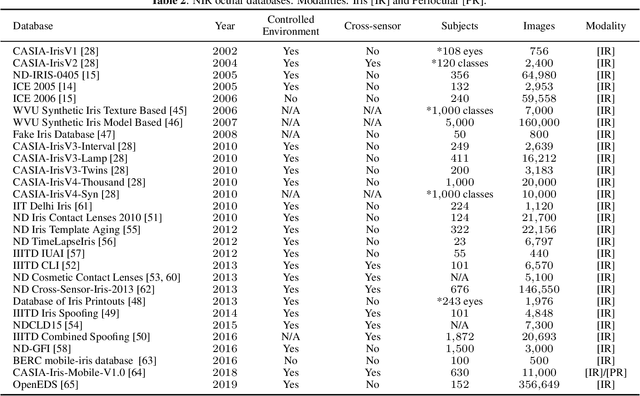
The use of the iris and periocular region as biometric traits has been extensively investigated, mainly due to the singularity of the iris features and the use of the periocular region when the image resolution is not sufficient to extract iris information. In addition to providing information about an individual's identity, features extracted from these traits can also be explored to obtain other information such as the individual's gender, the influence of drug use, the use of contact lenses, spoofing, among others. This work presents a survey of the databases created for ocular recognition, detailing their protocols and how their images were acquired. We also describe and discuss the most popular ocular recognition competitions (contests), highlighting the submitted algorithms that achieved the best results using only iris trait and also fusing iris and periocular region information. Finally, we describe some relevant works applying deep learning techniques to ocular recognition and point out new challenges and future directions. Considering that there are a large number of ocular databases, and each one is usually designed for a specific problem, we believe this survey can provide a broad overview of the challenges in ocular biometrics.
Deep Representations for Cross-spectral Ocular Biometrics
Nov 21, 2019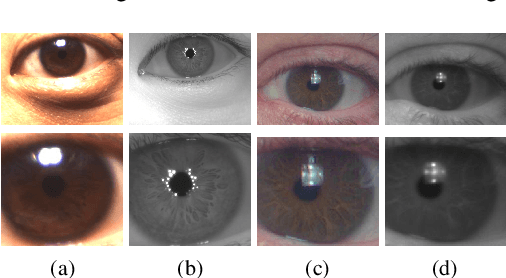
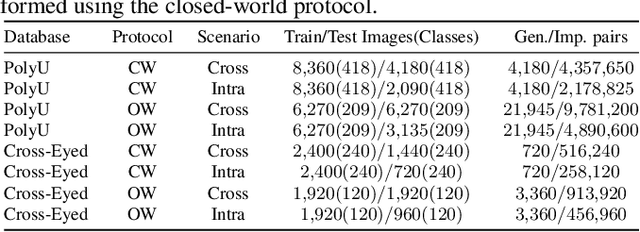
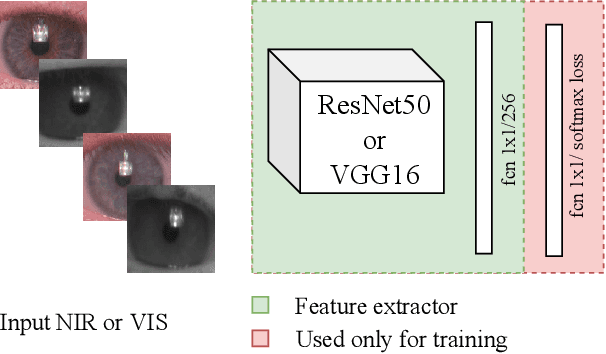
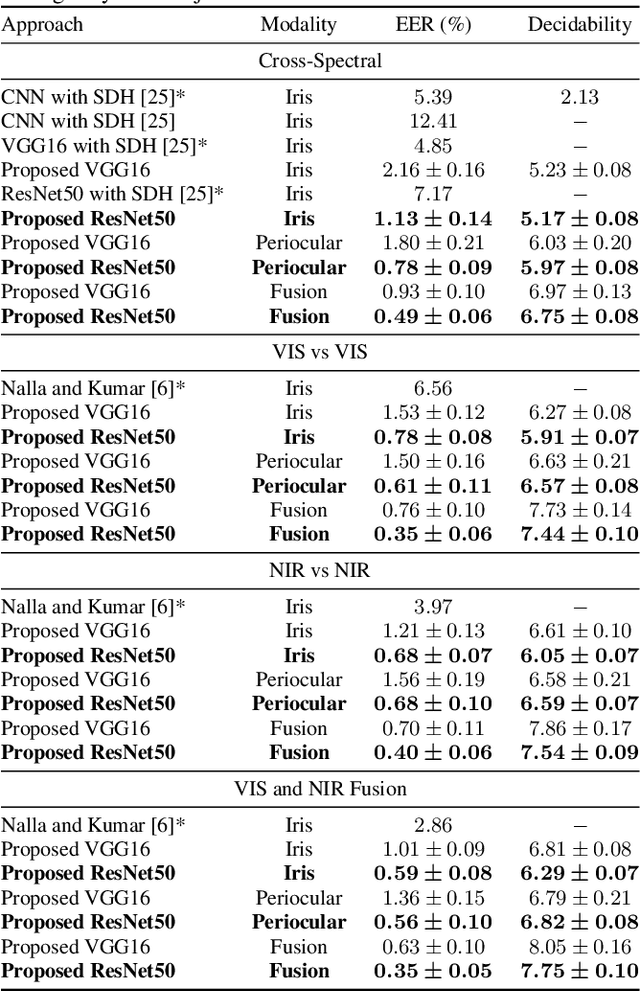
One of the major challenges in ocular biometrics is the cross-spectral scenario, i.e., how to match images acquired in different wavelengths (typically visible (VIS) against near-infrared (NIR)). This article designs and extensively evaluates cross-spectral ocular verification methods, for both the closed and open-world settings, using well known deep learning representations based on the iris and periocular regions. Using as inputs the bounding boxes of non-normalized iris/periocular regions, we fine-tune Convolutional Neural Network(CNN) models (based either on VGG16 or ResNet-50 architectures), originally trained for face recognition. Based on the experiments carried out in two publicly available cross-spectral ocular databases, we report results for intra-spectral and cross-spectral scenarios, with the best performance being observed when fusing ResNet-50 deep representations from both the periocular and iris regions. When compared to the state-of-the-art, we observed that the proposed solution consistently reduces the Equal Error Rate(EER) values by 90% / 93% / 96% and 61% / 77% / 83% on the cross-spectral scenario and in the PolyU Bi-spectral and Cross-eye-cross-spectral datasets. Lastly, we evaluate the effect that the "deepness" factor of feature representations has in recognition effectiveness, and - based on a subjective analysis of the most problematic pairwise comparisons - we point out further directions for this field of research.
Vehicle Re-identification: exploring feature fusion using multi-stream convolutional networks
Nov 13, 2019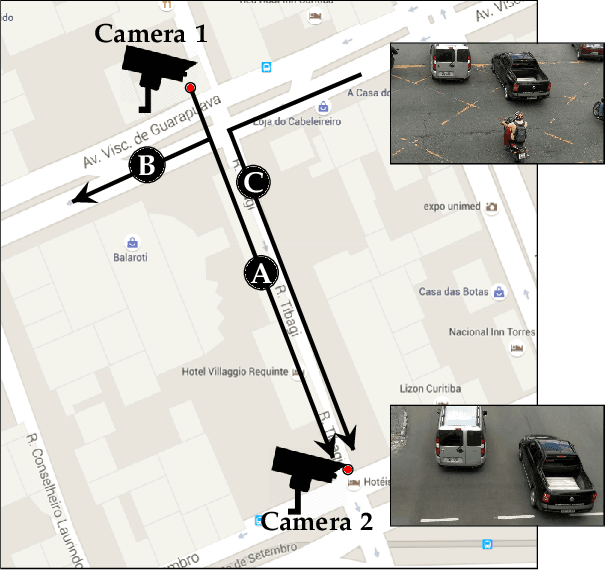

This work addresses the problem of vehicle re-identification through a network of non-overlapping cameras. As our main contribution, we propose a novel two-stream convolutional neural network (CNN) that simultaneously uses two of the most distinctive and persistent features available: the vehicle appearance and its license plate. This is an attempt to tackle a major problem, false alarms caused by vehicles with similar design or by very close license plate identifiers. In the first network stream, shape similarities are identified by a Siamese CNN that uses a pair of low-resolution vehicle patches recorded by two different cameras. In the second stream, we use a CNN for optical character recognition (OCR) to extract textual information, confidence scores, and string similarities from a pair of high-resolution license plate patches. Then, features from both streams are merged by a sequence of fully connected layers for decision. As part of this work, we created an important dataset for vehicle re-identification with more than three hours of videos spanning almost 3,000 vehicles. In our experiments, we achieved a precision, recall and F -score values of 99.6%, 99.2% and 99.4%, respectively. As another contribution, we discuss and compare three alternative architectures that explore the same features but using additional streams and temporal information. The proposed architectures, trained models, and dataset are publicly available at https://github.com/icarofua/vehicle-ReId .
Zero-Shot Action Recognition in Videos: A Survey
Sep 13, 2019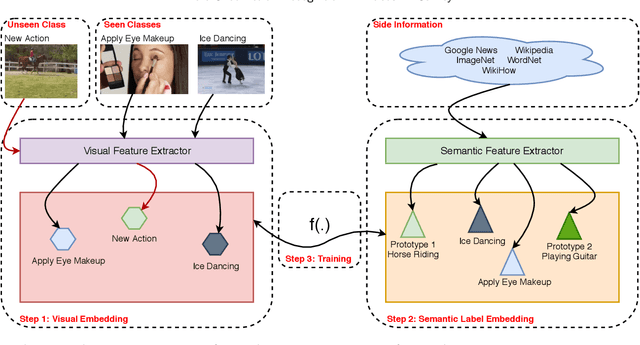

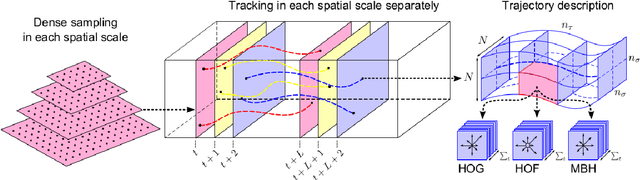
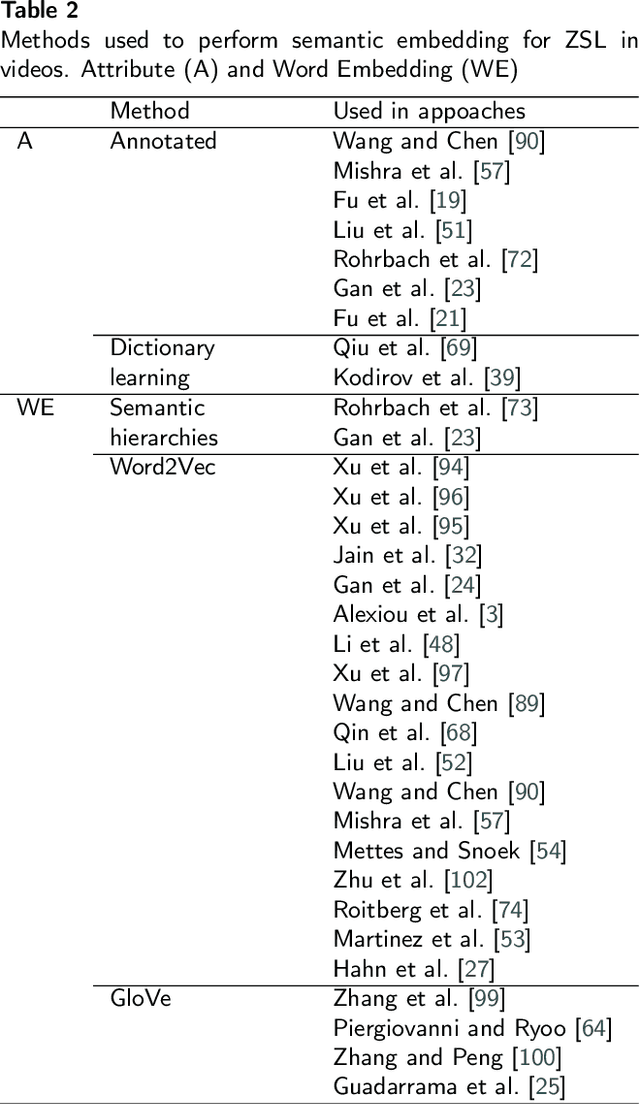
Zero-Shot Action Recognition has attracted attention in the last years, and many approaches have been proposed for recognition of objects, events, and actions in images and videos. There is a demand for methods that can classify instances from classes that are not present in the training of models, especially in the complex task of automatic video understanding, since collecting, annotating, and labeling videos are difficult and laborious tasks. We identify that there are many methods available in the literature, however, it is difficult to categorize which techniques can be considered state of the art. Despite the existence of some surveys about zero-shot action recognition in still images and experimental protocol, there is no work focusing on videos. Hence, in this paper, we present a survey of the methods comprising techniques to perform visual feature extraction and semantic feature extraction as well to learn the mapping between these features considering specifically zero-shot action recognition in videos. We also provide a complete description of datasets, experiments, and protocols, presenting open issues and directions for future work essential for the development of the computer vision research field.