 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Deep Modeling of Music Semantics using EEG Regularizers
Dec 15, 2017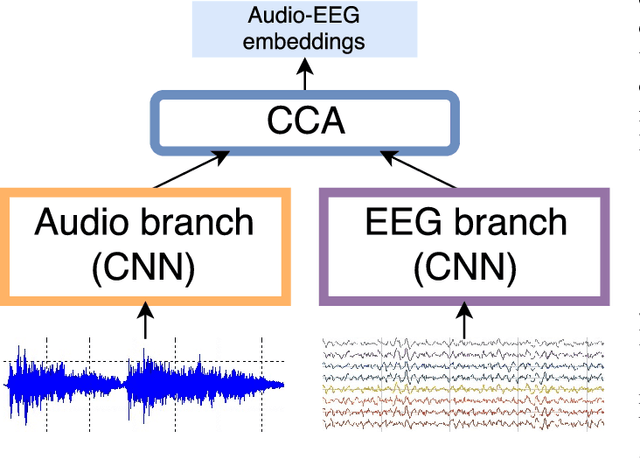
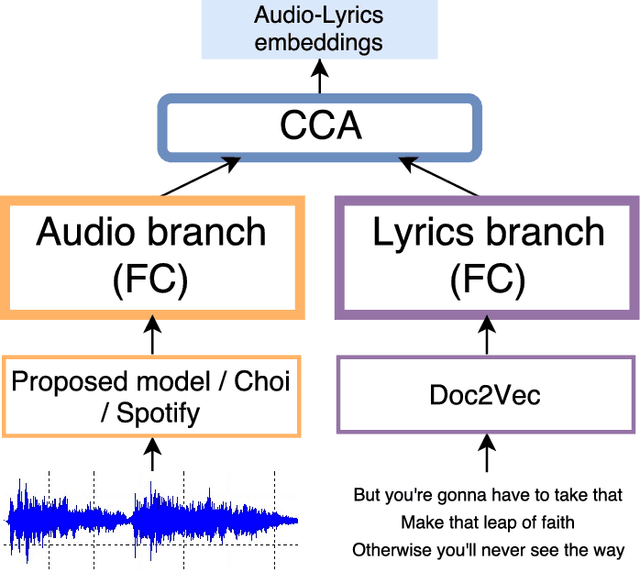

Modeling of music audio semantics has been previously tackled through learning of mappings from audio data to high-level tags or latent unsupervised spaces. The resulting semantic spaces are theoretically limited, either because the chosen high-level tags do not cover all of music semantics or because audio data itself is not enough to determine music semantics. In this paper, we propose a generic framework for semantics modeling that focuses on the perception of the listener, through EEG data, in addition to audio data. We implement this framework using a novel end-to-end 2-view Neural Network (NN) architecture and a Deep Canonical Correlation Analysis (DCCA) loss function that forces the semantic embedding spaces of both views to be maximally correlated. We also detail how the EEG dataset was collected and use it to train our proposed model. We evaluate the learned semantic space in a transfer learning context, by using it as an audio feature extractor in an independent dataset and proxy task: music audio-lyrics cross-modal retrieval. We show that our embedding model outperforms Spotify features and performs comparably to a state-of-the-art embedding model that was trained on 700 times more data. We further discuss improvements to the model that are likely to improve its performance.
Assessing User Expertise in Spoken Dialog System Interactions
Jan 18, 2017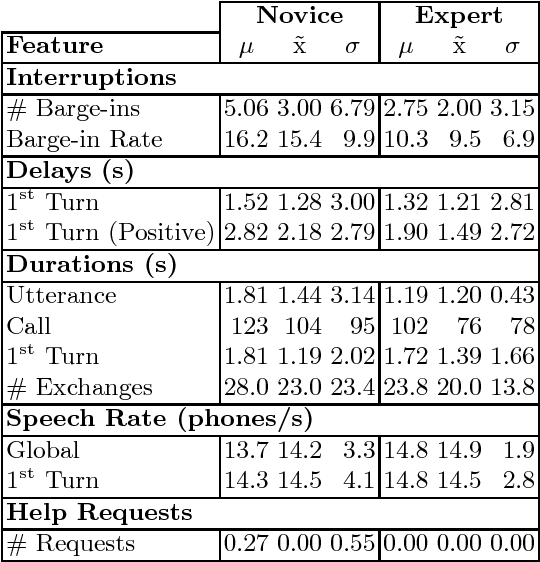
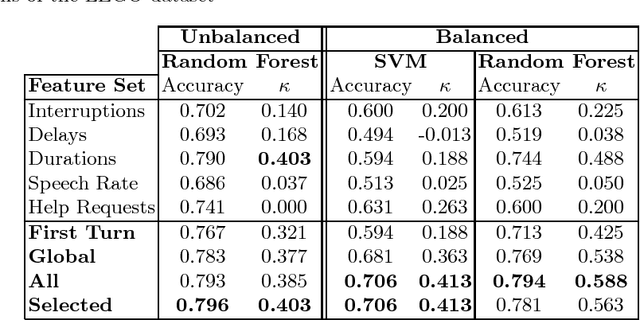
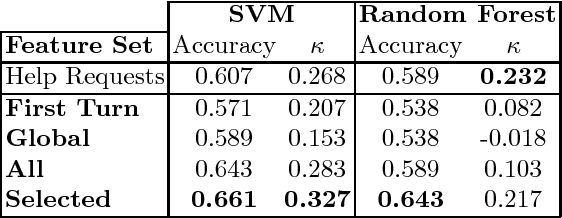
Identifying the level of expertise of its users is important for a system since it can lead to a better interaction through adaptation techniques. Furthermore, this information can be used in offline processes of root cause analysis. However, not much effort has been put into automatically identifying the level of expertise of an user, especially in dialog-based interactions. In this paper we present an approach based on a specific set of task related features. Based on the distribution of the features among the two classes - Novice and Expert - we used Random Forests as a classification approach. Furthermore, we used a Support Vector Machine classifier, in order to perform a result comparison. By applying these approaches on data from a real system, Let's Go, we obtained preliminary results that we consider positive, given the difficulty of the task and the lack of competing approaches for comparison.
* 10 pages
The Influence of Context on Dialogue Act Recognition
Jan 09, 2017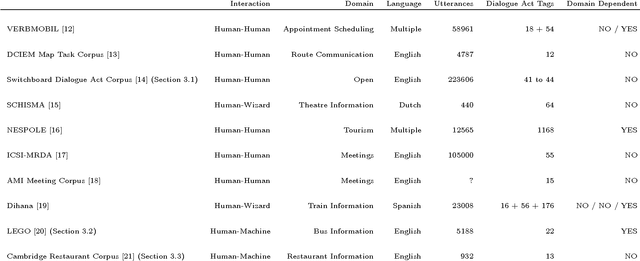
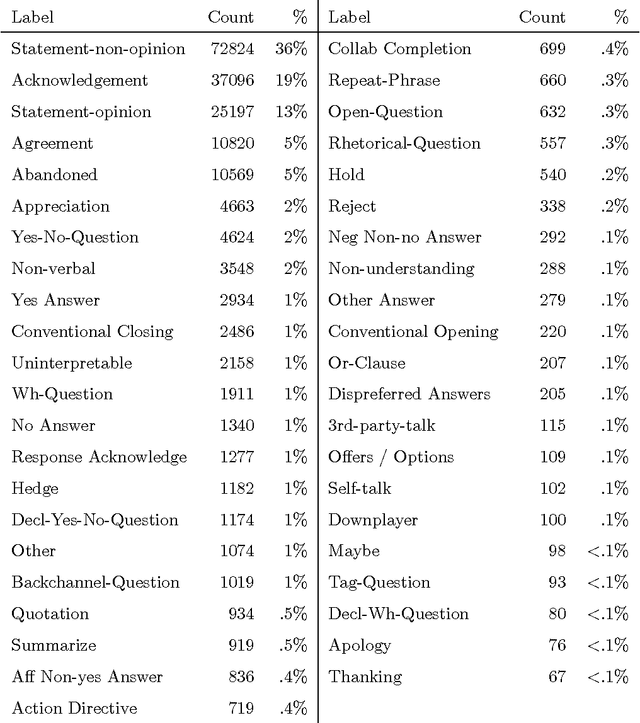
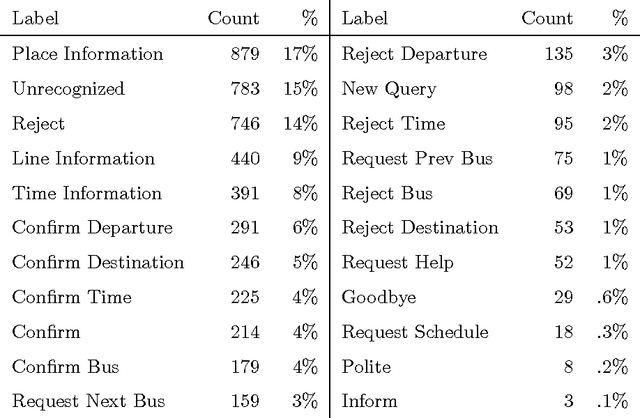
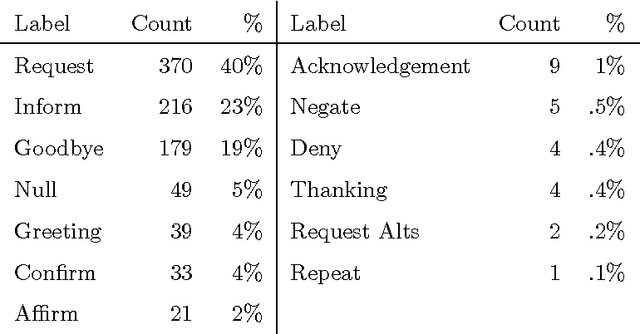
This article presents an analysis of the influence of context information on dialog act recognition. We performed experiments on the widely explored Switchboard corpus, as well as on data annotated according to the recent ISO 24617-2 standard. The latter was obtained from the Tilburg DialogBank and through the mapping of the annotations of a subset of the Let's Go corpus. We used a classification approach based on SVMs, which had proved successful in previous work and allowed us to limit the amount of context information provided. This way, we were able to observe the influence patterns as the amount of context information increased. Our base features consisted of n-grams, punctuation, and wh-words. Context information was obtained from one to five preceding segments and provided either as n-grams or dialog act classifications, with the latter typically leading to better results and more stable influence patterns. In addition to the conclusions about the importance and influence of context information, our experiments on the Switchboard corpus also led to results that advanced the state-of-the-art on the dialog act recognition task on that corpus. Furthermore, the results obtained on data annotated according to the ISO 24617-2 standard define a baseline for future work and contribute for the standardization of experiments in the area.
Mapping the Dialog Act Annotations of the LEGO Corpus into the Communicative Functions of ISO 24617-2
Dec 05, 2016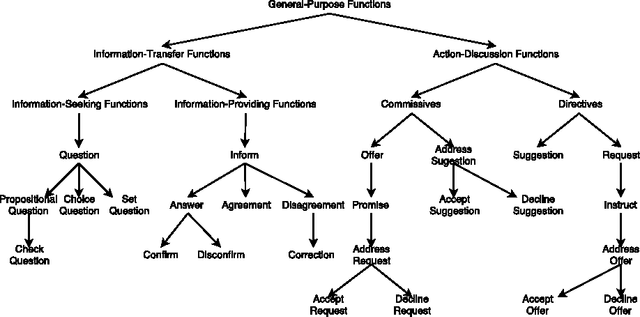
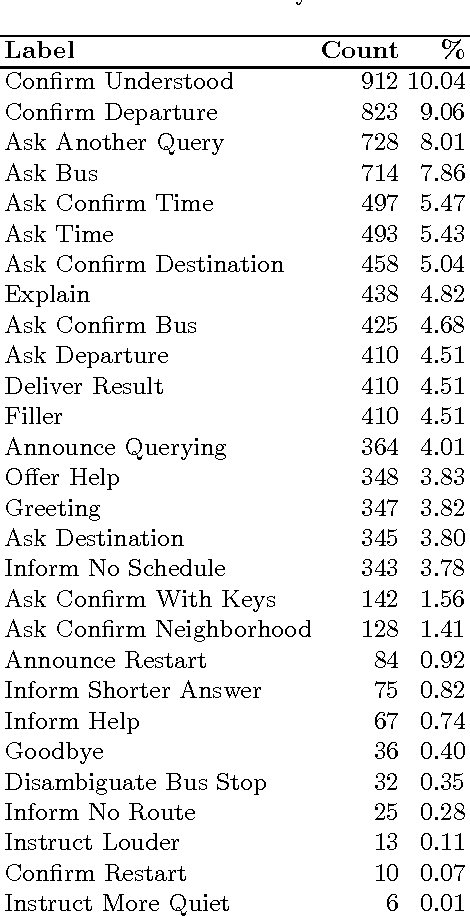
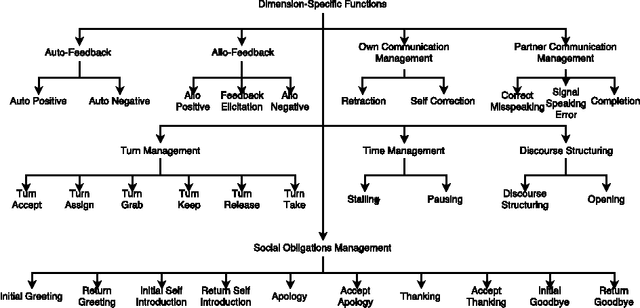
In this paper we present strategies for mapping the dialog act annotations of the LEGO corpus into the communicative functions of the ISO 24617-2 standard. Using these strategies, we obtained an additional 347 dialogs annotated according to the standard. This is particularly important given the reduced amount of existing data in those conditions due to the recency of the standard. Furthermore, these are dialogs from a widely explored corpus for dialog related tasks. However, its dialog annotations have been neglected due to their high domain-dependency, which renders them unuseful outside the context of the corpus. Thus, through our mapping process, we both obtain more data annotated according to a recent standard and provide useful dialog act annotations for a widely explored corpus in the context of dialog research.
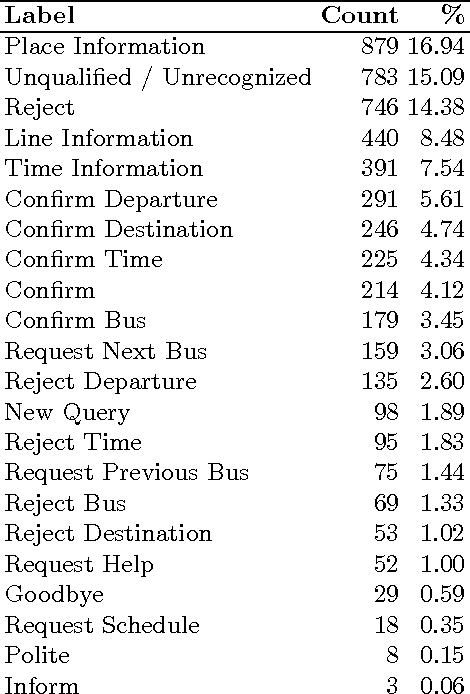
Fast and Extensible Online Multivariate Kernel Density Estimation
Jun 08, 2016
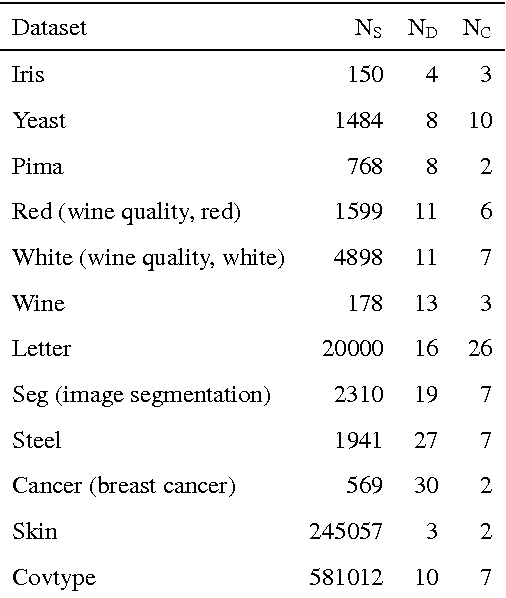
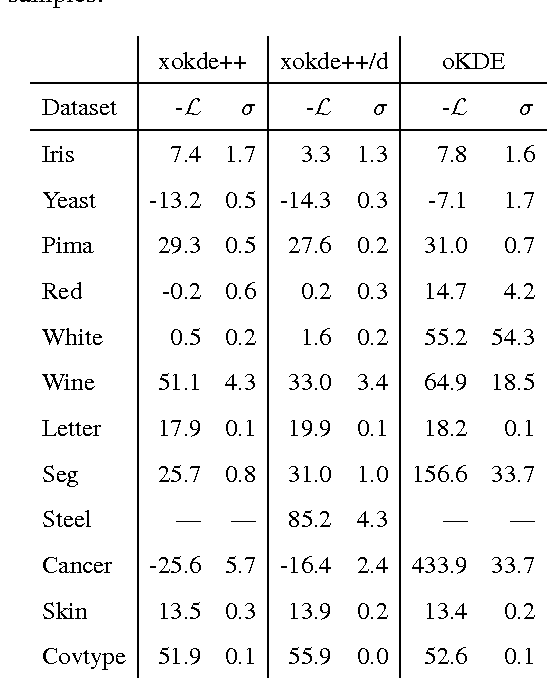
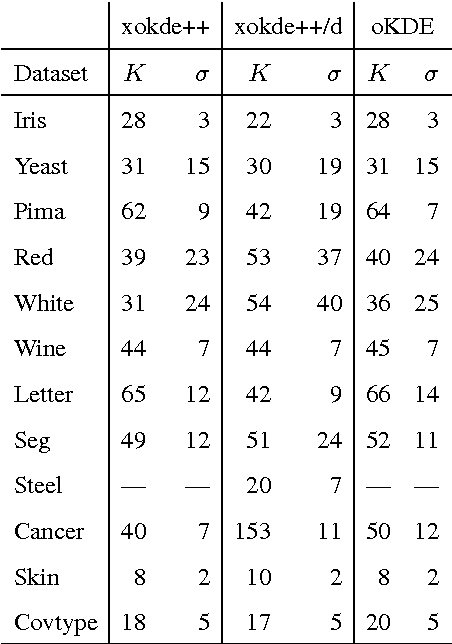
We present xokde++, a state-of-the-art online kernel density estimation approach that maintains Gaussian mixture models input data streams. The approach follows state-of-the-art work on online density estimation, but was redesigned with computational efficiency, numerical robustness, and extensibility in mind. Our approach produces comparable or better results than the current state-of-the-art, while achieving significant computational performance gains and improved numerical stability. The use of diagonal covariance Gaussian kernels, which further improve performance and stability, at a small loss of modelling quality, is also explored. Our approach is up to 40 times faster, while requiring 90\% less memory than the closest state-of-the-art counterpart.
Summarization of Films and Documentaries Based on Subtitles and Scripts
Mar 09, 2016
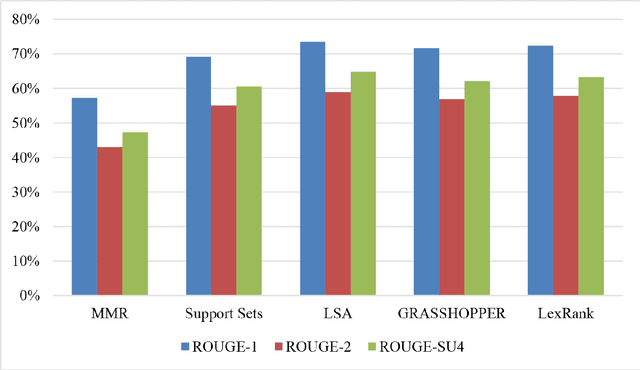
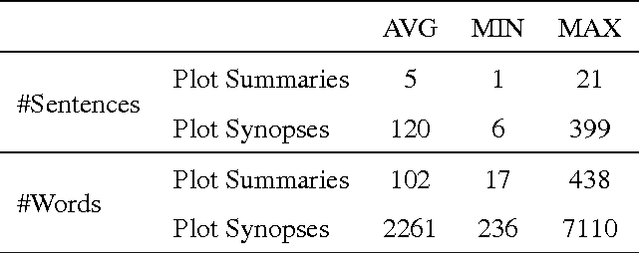
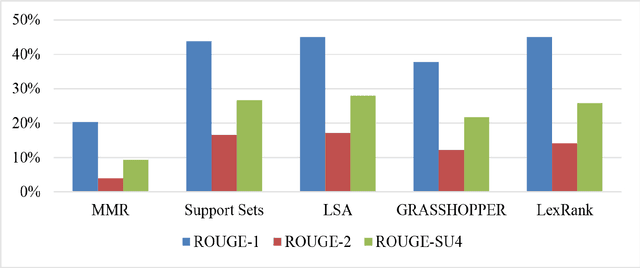
We assess the performance of generic text summarization algorithms applied to films and documentaries, using the well-known behavior of summarization of news articles as reference. We use three datasets: (i) news articles, (ii) film scripts and subtitles, and (iii) documentary subtitles. Standard ROUGE metrics are used for comparing generated summaries against news abstracts, plot summaries, and synopses. We show that the best performing algorithms are LSA, for news articles and documentaries, and LexRank and Support Sets, for films. Despite the different nature of films and documentaries, their relative behavior is in accordance with that obtained for news articles.
* 7 pages, 9 tables, 4 figures, submitted to Pattern Recognition Letters (Elsevier)
Using Generic Summarization to Improve Music Information Retrieval Tasks
Mar 09, 2016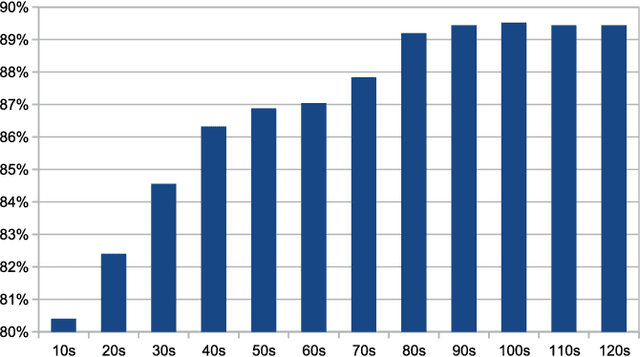
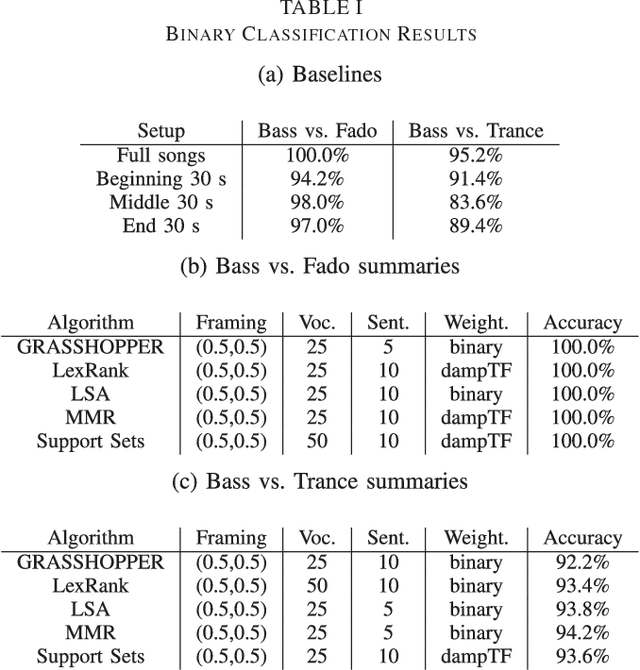
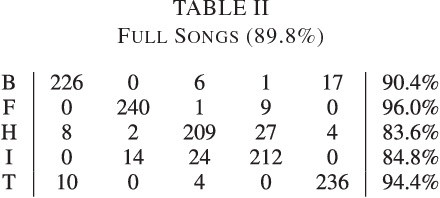
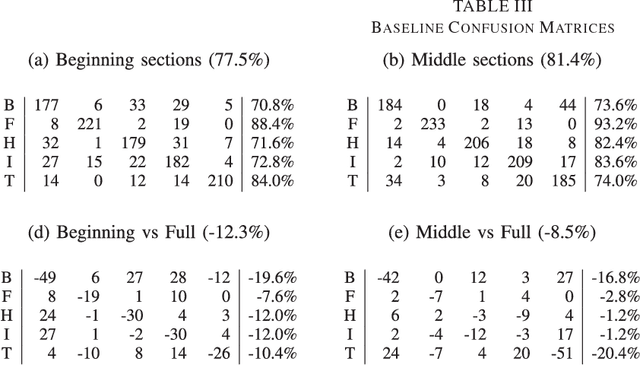
In order to satisfy processing time constraints, many MIR tasks process only a segment of the whole music signal. This practice may lead to decreasing performance, since the most important information for the tasks may not be in those processed segments. In this paper, we leverage generic summarization algorithms, previously applied to text and speech summarization, to summarize items in music datasets. These algorithms build summaries, that are both concise and diverse, by selecting appropriate segments from the input signal which makes them good candidates to summarize music as well. We evaluate the summarization process on binary and multiclass music genre classification tasks, by comparing the performance obtained using summarized datasets against the performances obtained using continuous segments (which is the traditional method used for addressing the previously mentioned time constraints) and full songs of the same original dataset. We show that GRASSHOPPER, LexRank, LSA, MMR, and a Support Sets-based Centrality model improve classification performance when compared to selected 30-second baselines. We also show that summarized datasets lead to a classification performance whose difference is not statistically significant from using full songs. Furthermore, we make an argument stating the advantages of sharing summarized datasets for future MIR research.
* 24 pages, 10 tables; Submitted to IEEE/ACM Transactions on Audio, Speech and Language Processing
Generation of Multimedia Artifacts: An Extractive Summarization-based Approach
Aug 13, 2015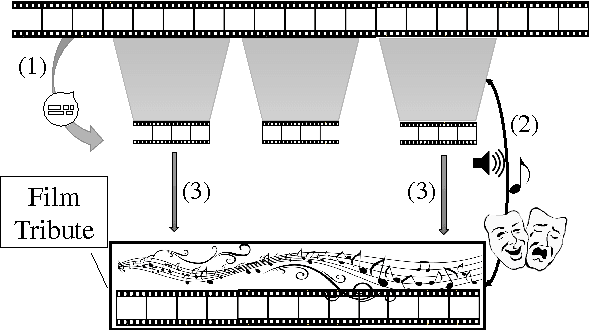
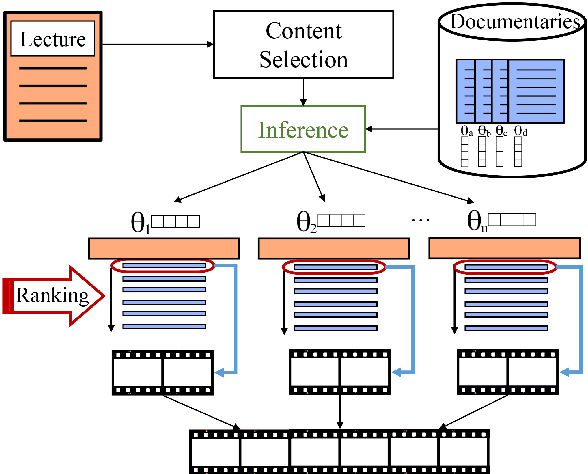
We explore methods for content selection and address the issue of coherence in the context of the generation of multimedia artifacts. We use audio and video to present two case studies: generation of film tributes, and lecture-driven science talks. For content selection, we use centrality-based and diversity-based summarization, along with topic analysis. To establish coherence, we use the emotional content of music, for film tributes, and ensure topic similarity between lectures and documentaries, for science talks. Composition techniques for the production of multimedia artifacts are addressed as a means of organizing content, in order to improve coherence. We discuss our results considering the above aspects.
Privacy-Preserving Multi-Document Summarization
Aug 06, 2015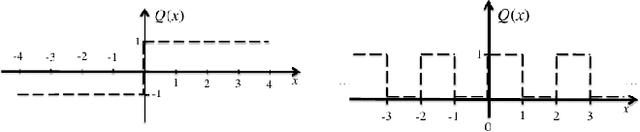

State-of-the-art extractive multi-document summarization systems are usually designed without any concern about privacy issues, meaning that all documents are open to third parties. In this paper we propose a privacy-preserving approach to multi-document summarization. Our approach enables other parties to obtain summaries without learning anything else about the original documents' content. We use a hashing scheme known as Secure Binary Embeddings to convert documents representation containing key phrases and bag-of-words into bit strings, allowing the computation of approximate distances, instead of exact ones. Our experiments indicate that our system yields similar results to its non-private counterpart on standard multi-document evaluation datasets.
Extending a Single-Document Summarizer to Multi-Document: a Hierarchical Approach
Jul 10, 2015
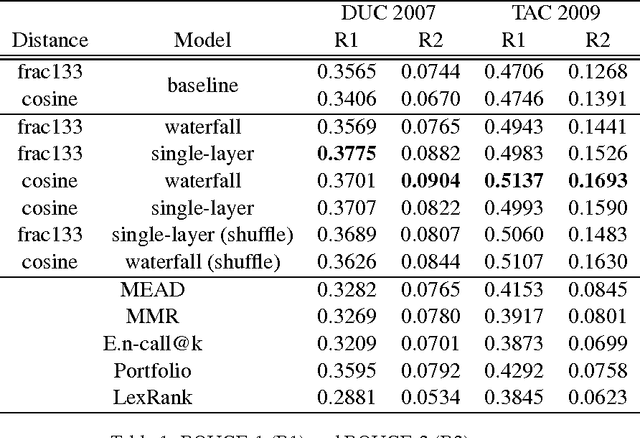
The increasing amount of online content motivated the development of multi-document summarization methods. In this work, we explore straightforward approaches to extend single-document summarization methods to multi-document summarization. The proposed methods are based on the hierarchical combination of single-document summaries, and achieves state of the art results.