 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Potential Exomoon Signals with Convolutional Neural Networks
Sep 22, 2021



Targeted observations of possible exomoon host systems will remain difficult to obtain and time-consuming to analyze in the foreseeable future. As such, time-domain surveys such as Kepler, K2 and TESS will continue to play a critical role as the first step in identifying candidate exomoon systems, which may then be followed-up with premier ground- or space-based telescopes. In this work, we train an ensemble of convolutional neural networks (CNNs) to identify candidate exomoon signals in single-transit events observed by Kepler. Our training set consists of ${\sim}$27,000 examples of synthetic, planet-only and planet+moon single transits, injected into Kepler light curves. We achieve up to 88\% classification accuracy with individual CNN architectures and 97\% precision in identifying the moons in the validation set when the CNN ensemble is in total agreement. We then apply the CNN ensemble to light curves from 1880 Kepler Objects of Interest with periods $>10$ days ($\sim$57,000 individual transits), and further test the accuracy of the CNN classifier by injecting planet transits into each light curve, thus quantifying the extent to which residual stellar activity may result in false positive classifications. We find a small fraction of these transits contain moon-like signals, though we caution against strong inferences of the exomoon occurrence rate from this result. We conclude by discussing some ongoing challenges to utilizing neural networks for the exomoon search.
On planetary systems as ordered sequences
May 20, 2021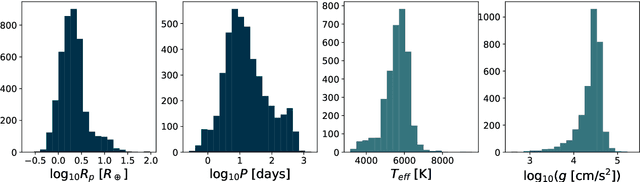

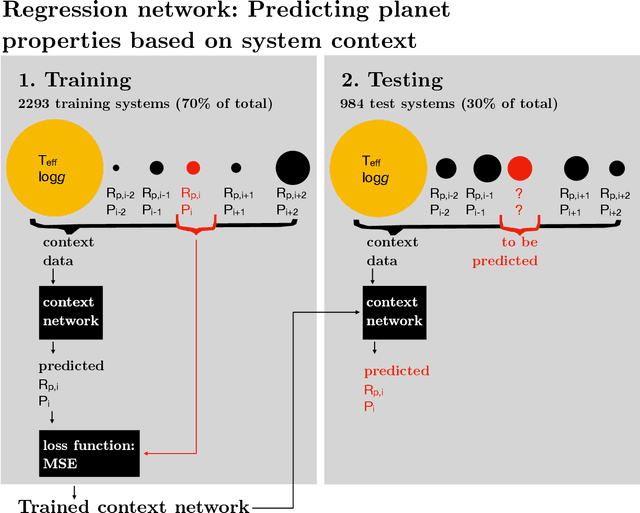
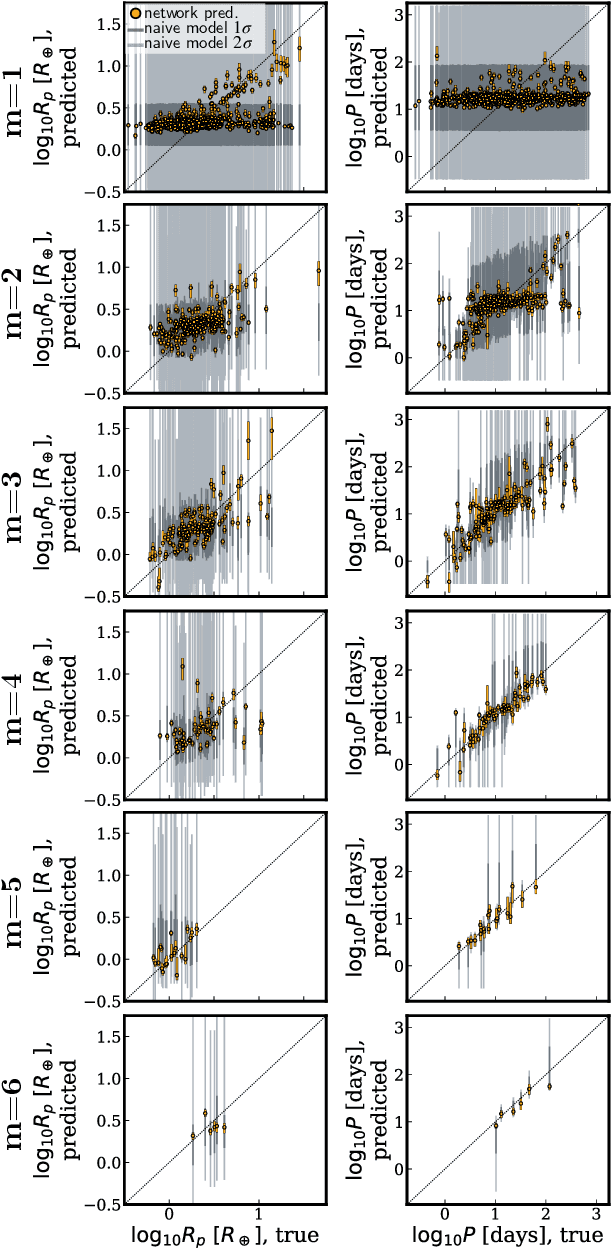
A planetary system consists of a host star and one or more planets, arranged into a particular configuration. Here, we consider what information belongs to the configuration, or ordering, of 4286 Kepler planets in their 3277 planetary systems. First, we train a neural network model to predict the radius and period of a planet based on the properties of its host star and the radii and period of its neighbors. The mean absolute error of the predictions of the trained model is a factor of 2.1 better than the MAE of the predictions of a naive model which draws randomly from dynamically allowable periods and radii. Second, we adapt a model used for unsupervised part-of-speech tagging in computational linguistics to investigate whether planets or planetary systems fall into natural categories with physically interpretable "grammatical rules." The model identifies two robust groups of planetary systems: (1) compact multi-planet systems and (2) systems around giant stars ($\log{g} \lesssim 4.0$), although the latter group is strongly sculpted by the selection bias of the transit method. These results reinforce the idea that planetary systems are not random sequences -- instead, as a population, they contain predictable patterns that can provide insight into the formation and evolution of planetary systems.