 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Scale Error Control in Low Light Image and Video Enhancement Using Equivariance
Jun 02, 2022
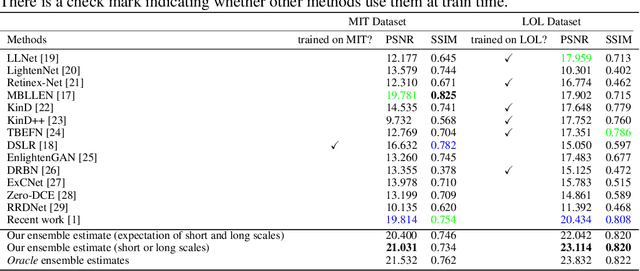


Image frames obtained in darkness are special. Just multiplying by a constant doesn't restore the image. Shot noise, quantization effects and camera non-linearities mean that colors and relative light levels are estimated poorly. Current methods learn a mapping using real dark-bright image pairs. These are very hard to capture. A recent paper has shown that simulated data pairs produce real improvements in restoration, likely because huge volumes of simulated data are easy to obtain. In this paper, we show that respecting equivariance -- the color of a restored pixel should be the same, however the image is cropped -- produces real improvements over the state of the art for restoration. We show that a scale selection mechanism can be used to improve reconstructions. Finally, we show that our approach produces improvements on video restoration as well. Our methods are evaluated both quantitatively and qualitatively.
Towards Robust Low Light Image Enhancement
May 17, 2022
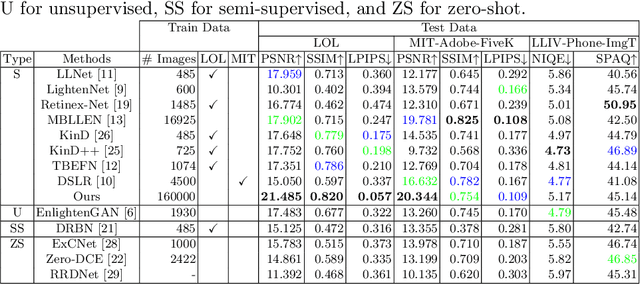

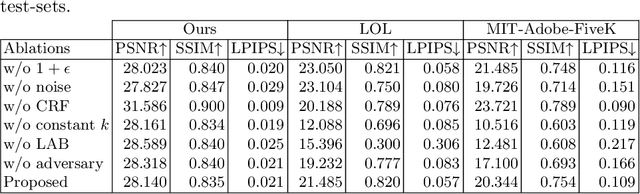
In this paper, we study the problem of making brighter images from dark images found in the wild. The images are dark because they are taken in dim environments. They suffer from color shifts caused by quantization and from sensor noise. We don't know the true camera reponse function for such images and they are not RAW. We use a supervised learning method, relying on a straightforward simulation of an imaging pipeline to generate usable dataset for training and testing. On a number of standard datasets, our approach outperforms the state of the art quantitatively. Qualitative comparisons suggest strong improvements in reconstruction accuracy.
JoJoGAN: One Shot Face Stylization
Dec 22, 2021
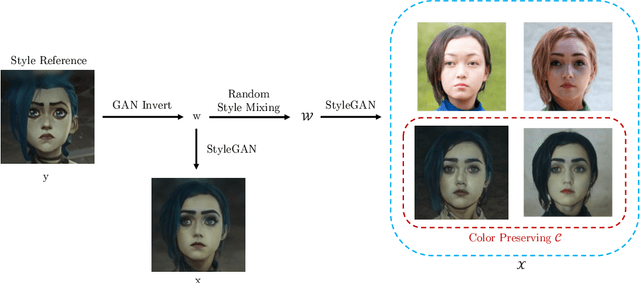


While there have been recent advances in few-shot image stylization, these methods fail to capture stylistic details that are obvious to humans. Details such as the shape of the eyes, the boldness of the lines, are especially difficult for a model to learn, especially so under a limited data setting. In this work, we aim to perform one-shot image stylization that gets the details right. Given a reference style image, we approximate paired real data using GAN inversion and finetune a pretrained StyleGAN using that approximate paired data. We then encourage the StyleGAN to generalize so that the learned style can be applied to all other images.
DIVeR: Real-time and Accurate Neural Radiance Fields with Deterministic Integration for Volume Rendering
Nov 19, 2021
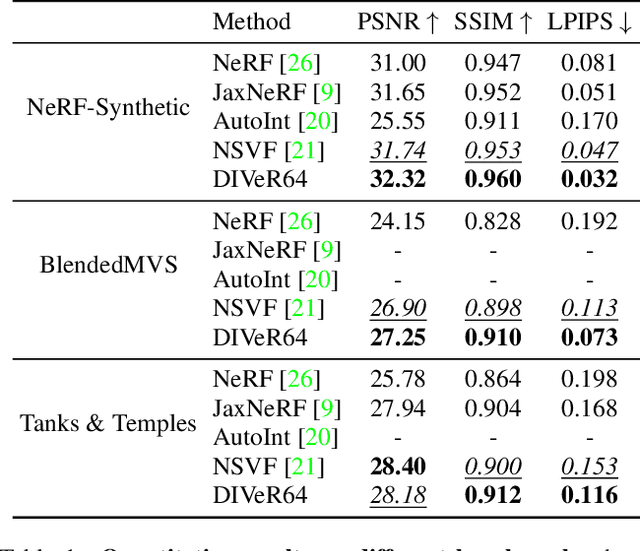
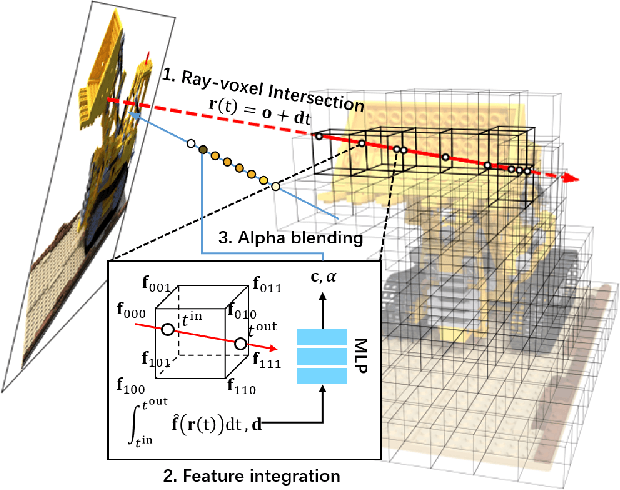
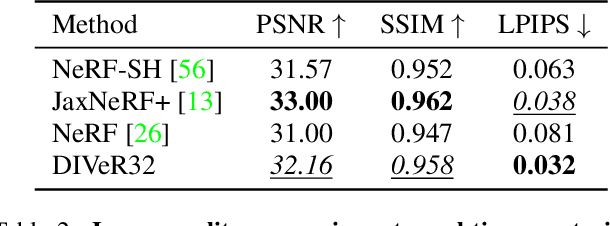
DIVeR builds on the key ideas of NeRF and its variants -- density models and volume rendering -- to learn 3D object models that can be rendered realistically from small numbers of images. In contrast to all previous NeRF methods, DIVeR uses deterministic rather than stochastic estimates of the volume rendering integral. DIVeR's representation is a voxel based field of features. To compute the volume rendering integral, a ray is broken into intervals, one per voxel; components of the volume rendering integral are estimated from the features for each interval using an MLP, and the components are aggregated. As a result, DIVeR can render thin translucent structures that are missed by other integrators. Furthermore, DIVeR's representation has semantics that is relatively exposed compared to other such methods -- moving feature vectors around in the voxel space results in natural edits. Extensive qualitative and quantitative comparisons to current state-of-the-art methods show that DIVeR produces models that (1) render at or above state-of-the-art quality, (2) are very small without being baked, (3) render very fast without being baked, and (4) can be edited in natural ways.
StyleGAN of All Trades: Image Manipulation with Only Pretrained StyleGAN
Nov 02, 2021
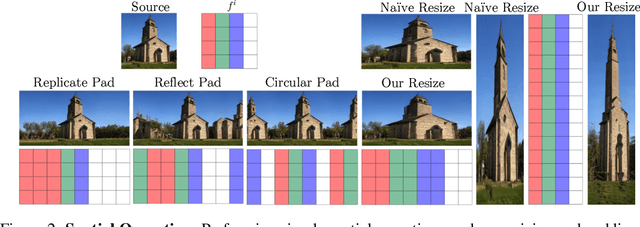


Recently, StyleGAN has enabled various image manipulation and editing tasks thanks to the high-quality generation and the disentangled latent space. However, additional architectures or task-specific training paradigms are usually required for different tasks. In this work, we take a deeper look at the spatial properties of StyleGAN. We show that with a pretrained StyleGAN along with some operations, without any additional architecture, we can perform comparably to the state-of-the-art methods on various tasks, including image blending, panorama generation, generation from a single image, controllable and local multimodal image to image translation, and attributes transfer. The proposed method is simple, effective, efficient, and applicable to any existing pretrained StyleGAN model.
On the Importance of Firth Bias Reduction in Few-Shot Classification
Oct 06, 2021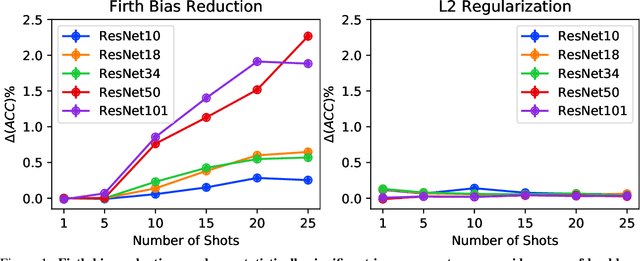
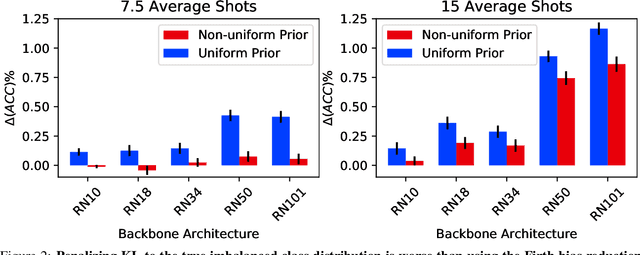
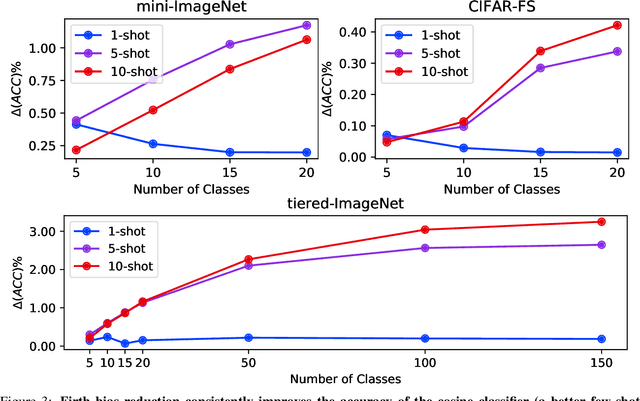
Learning accurate classifiers for novel categories from very few examples, known as few-shot image classification, is a challenging task in statistical machine learning and computer vision. The performance in few-shot classification suffers from the bias in the estimation of classifier parameters; however, an effective underlying bias reduction technique that could alleviate this issue in training few-shot classifiers has been overlooked. In this work, we demonstrate the effectiveness of Firth bias reduction in few-shot classification. Theoretically, Firth bias reduction removes the first order term $O(N^{-1})$ from the small-sample bias of the Maximum Likelihood Estimator. Here we show that the general Firth bias reduction technique simplifies to encouraging uniform class assignment probabilities for multinomial logistic classification, and almost has the same effect in cosine classifiers. We derive the optimization objective for Firth penalized multinomial logistic and cosine classifiers, and empirically evaluate that it is consistently effective across the board for few-shot image classification, regardless of (1) the feature representations from different backbones, (2) the number of samples per class, and (3) the number of classes. Finally, we show the robustness of Firth bias reduction, in the case of imbalanced data distribution. Our implementation is available at https://github.com/ehsansaleh/firth_bias_reduction
LSD-StructureNet: Modeling Levels of Structural Detail in 3D Part Hierarchies
Sep 07, 2021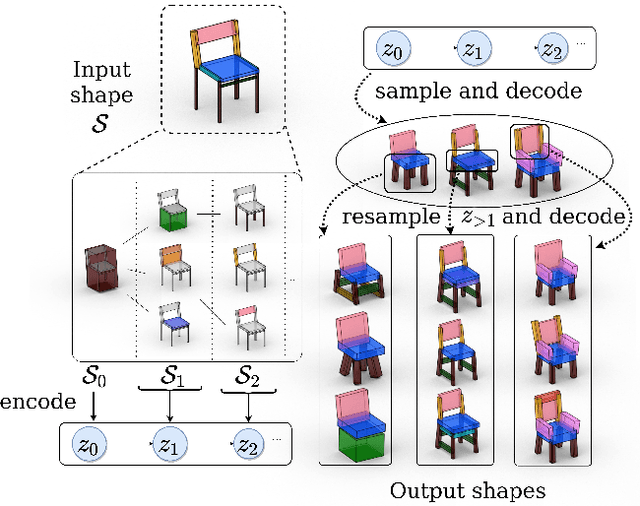
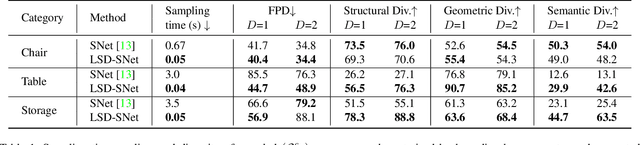
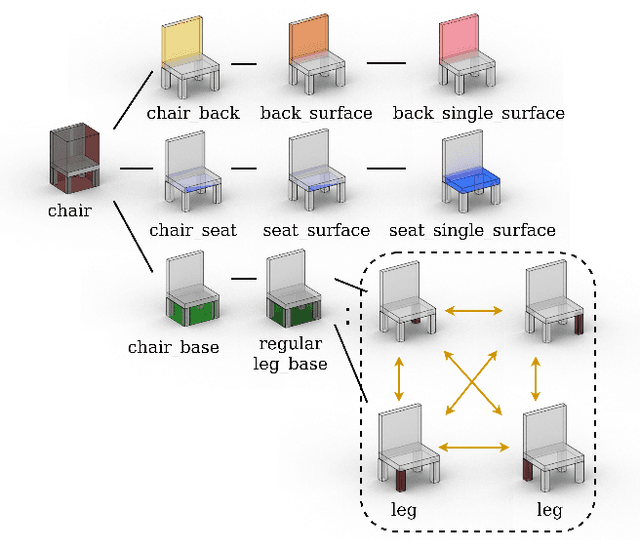
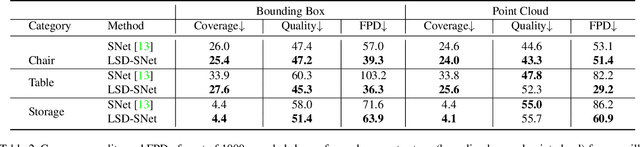
Generative models for 3D shapes represented by hierarchies of parts can generate realistic and diverse sets of outputs. However, existing models suffer from the key practical limitation of modelling shapes holistically and thus cannot perform conditional sampling, i.e. they are not able to generate variants on individual parts of generated shapes without modifying the rest of the shape. This is limiting for applications such as 3D CAD design that involve adjusting created shapes at multiple levels of detail. To address this, we introduce LSD-StructureNet, an augmentation to the StructureNet architecture that enables re-generation of parts situated at arbitrary positions in the hierarchies of its outputs. We achieve this by learning individual, probabilistic conditional decoders for each hierarchy depth. We evaluate LSD-StructureNet on the PartNet dataset, the largest dataset of 3D shapes represented by hierarchies of parts. Our results show that contrarily to existing methods, LSD-StructureNet can perform conditional sampling without impacting inference speed or the realism and diversity of its outputs.
Controlled GAN-Based Creature Synthesis via a Challenging Game Art Dataset -- Addressing the Noise-Latent Trade-Off
Aug 19, 2021


The state-of-the-art StyleGAN2 network supports powerful methods to create and edit art, including generating random images, finding images "like" some query, and modifying content or style. Further, recent advancements enable training with small datasets. We apply these methods to synthesize card art, by training on a novel Yu-Gi-Oh dataset. While noise inputs to StyleGAN2 are essential for good synthesis, we find that, for small datasets, coarse-scale noise interferes with latent variables because both control long-scale image effects. We observe over-aggressive variation in art with changes in noise and weak content control via latent variable edits. Here, we demonstrate that training a modified StyleGAN2, where coarse-scale noise is suppressed, removes these unwanted effects. We obtain a superior FID; changes in noise result in local exploration of style; and identity control is markedly improved. These results and analysis lead towards a GAN-assisted art synthesis tool for digital artists of all skill levels, which can be used in film, games, or any creative industry for artistic ideation.
Retrieve in Style: Unsupervised Facial Feature Transfer and Retrieval
Jul 17, 2021
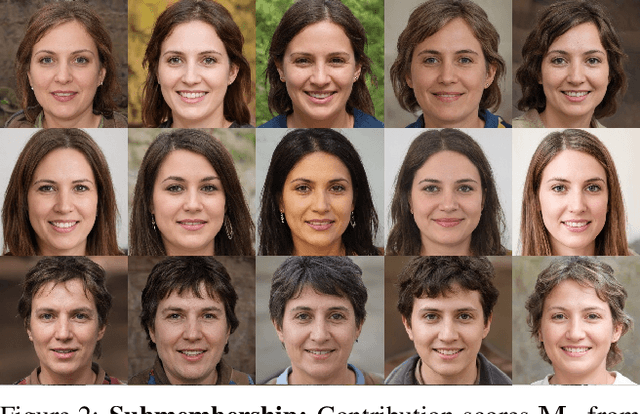
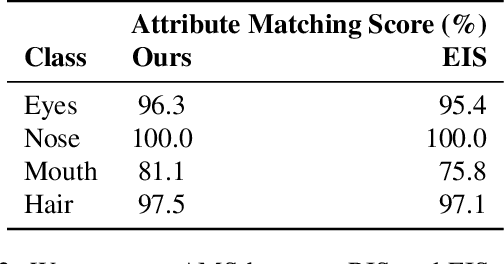

We present Retrieve in Style (RIS), an unsupervised framework for fine-grained facial feature transfer and retrieval on real images. Recent work shows that it is possible to learn a catalog that allows local semantic transfers of facial features on generated images by capitalizing on the disentanglement property of the StyleGAN latent space. RIS improves existing art on: 1) feature disentanglement and allows for challenging transfers (i.e., hair and pose) that were not shown possible in SoTA methods. 2) eliminating the need for per-image hyperparameter tuning, and for computing a catalog over a large batch of images. 3) enabling face retrieval using the proposed facial features (e.g., eyes), and to our best knowledge, is the first work to retrieve face images at the fine-grained level. 4) robustness and natural application to real images. Our qualitative and quantitative analyses show RIS achieves both high-fidelity feature transfers and accurate fine-grained retrievals on real images. We discuss the responsible application of RIS.
GANs N' Roses: Stable, Controllable, Diverse Image to Image Translation (works for videos too!)
Jun 11, 2021
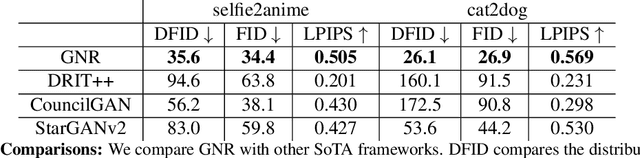
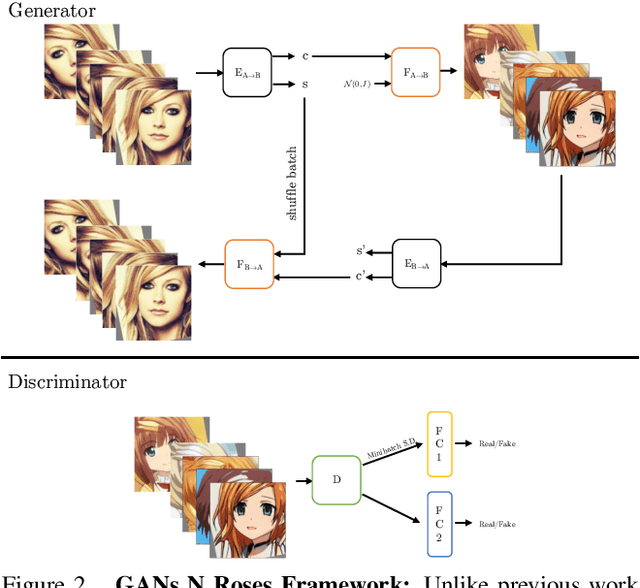

We show how to learn a map that takes a content code, derived from a face image, and a randomly chosen style code to an anime image. We derive an adversarial loss from our simple and effective definitions of style and content. This adversarial loss guarantees the map is diverse -- a very wide range of anime can be produced from a single content code. Under plausible assumptions, the map is not just diverse, but also correctly represents the probability of an anime, conditioned on an input face. In contrast, current multimodal generation procedures cannot capture the complex styles that appear in anime. Extensive quantitative experiments support the idea the map is correct. Extensive qualitative results show that the method can generate a much more diverse range of styles than SOTA comparisons. Finally, we show that our formalization of content and style allows us to perform video to video translation without ever training on videos.