 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Inference with Gaussian Score Matching
Jul 15, 2023Variational inference (VI) is a method to approximate the computationally intractable posterior distributions that arise in Bayesian statistics. Typically, VI fits a simple parametric distribution to the target posterior by minimizing an appropriate objective such as the evidence lower bound (ELBO). In this work, we present a new approach to VI based on the principle of score matching, that if two distributions are equal then their score functions (i.e., gradients of the log density) are equal at every point on their support. With this, we develop score matching VI, an iterative algorithm that seeks to match the scores between the variational approximation and the exact posterior. At each iteration, score matching VI solves an inner optimization, one that minimally adjusts the current variational estimate to match the scores at a newly sampled value of the latent variables. We show that when the variational family is a Gaussian, this inner optimization enjoys a closed form solution, which we call Gaussian score matching VI (GSM-VI). GSM-VI is also a ``black box'' variational algorithm in that it only requires a differentiable joint distribution, and as such it can be applied to a wide class of models. We compare GSM-VI to black box variational inference (BBVI), which has similar requirements but instead optimizes the ELBO. We study how GSM-VI behaves as a function of the problem dimensionality, the condition number of the target covariance matrix (when the target is Gaussian), and the degree of mismatch between the approximating and exact posterior distribution. We also study GSM-VI on a collection of real-world Bayesian inference problems from the posteriorDB database of datasets and models. In all of our studies we find that GSM-VI is faster than BBVI, but without sacrificing accuracy. It requires 10-100x fewer gradient evaluations to obtain a comparable quality of approximation.
Variational Inference for Infinitely Deep Neural Networks
Sep 21, 2022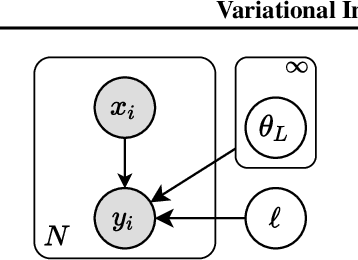
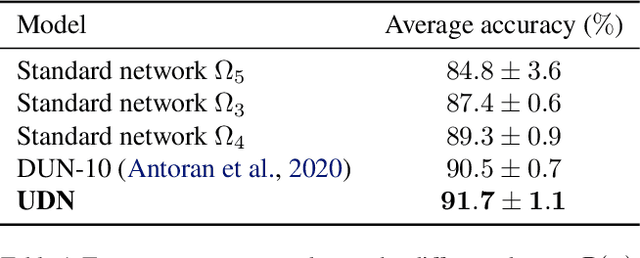
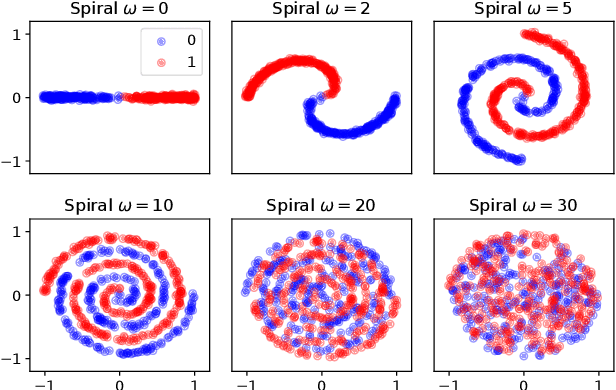
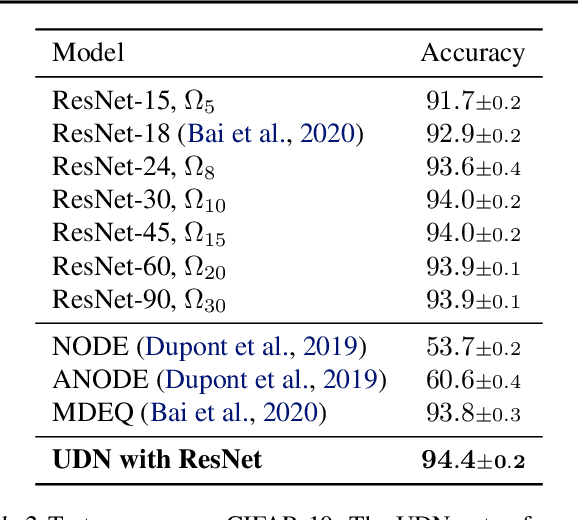
We introduce the unbounded depth neural network (UDN), an infinitely deep probabilistic model that adapts its complexity to the training data. The UDN contains an infinite sequence of hidden layers and places an unbounded prior on a truncation L, the layer from which it produces its data. Given a dataset of observations, the posterior UDN provides a conditional distribution of both the parameters of the infinite neural network and its truncation. We develop a novel variational inference algorithm to approximate this posterior, optimizing a distribution of the neural network weights and of the truncation depth L, and without any upper limit on L. To this end, the variational family has a special structure: it models neural network weights of arbitrary depth, and it dynamically creates or removes free variational parameters as its distribution of the truncation is optimized. (Unlike heuristic approaches to model search, it is solely through gradient-based optimization that this algorithm explores the space of truncations.) We study the UDN on real and synthetic data. We find that the UDN adapts its posterior depth to the dataset complexity; it outperforms standard neural networks of similar computational complexity; and it outperforms other approaches to infinite-depth neural networks.
Forget-me-not! Contrastive Critics for Mitigating Posterior Collapse
Jul 19, 2022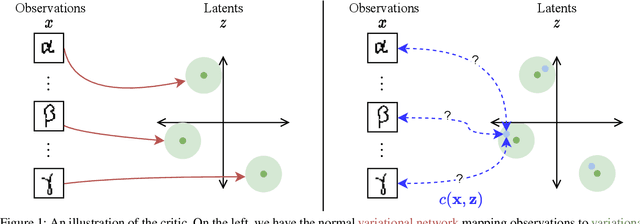
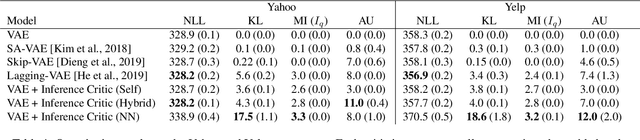
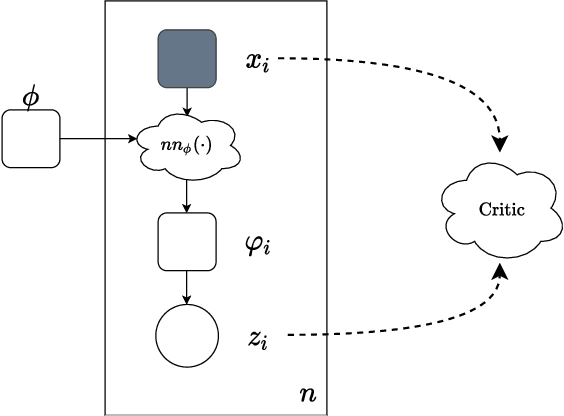
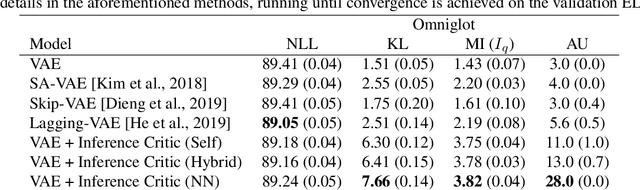
Variational autoencoders (VAEs) suffer from posterior collapse, where the powerful neural networks used for modeling and inference optimize the objective without meaningfully using the latent representation. We introduce inference critics that detect and incentivize against posterior collapse by requiring correspondence between latent variables and the observations. By connecting the critic's objective to the literature in self-supervised contrastive representation learning, we show both theoretically and empirically that optimizing inference critics increases the mutual information between observations and latents, mitigating posterior collapse. This approach is straightforward to implement and requires significantly less training time than prior methods, yet obtains competitive results on three established datasets. Overall, the approach lays the foundation to bridge the previously disconnected frameworks of contrastive learning and probabilistic modeling with variational autoencoders, underscoring the benefits both communities may find at their intersection.
Reconstructing the Universe with Variational self-Boosted Sampling
Jun 28, 2022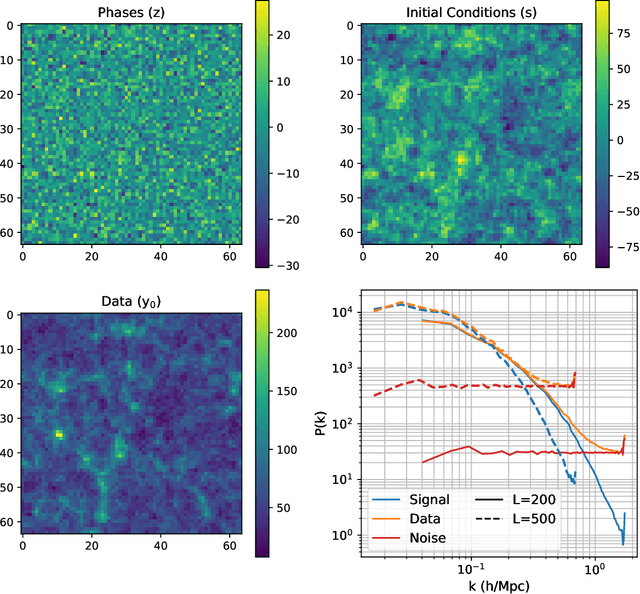
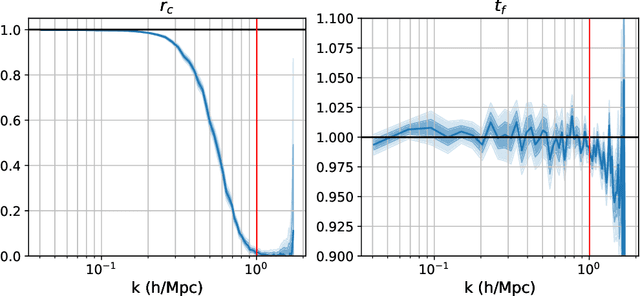
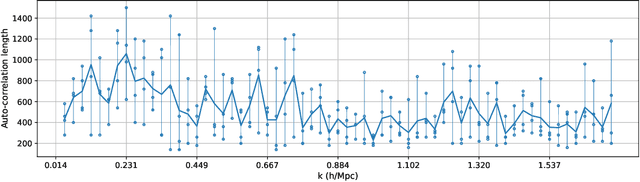
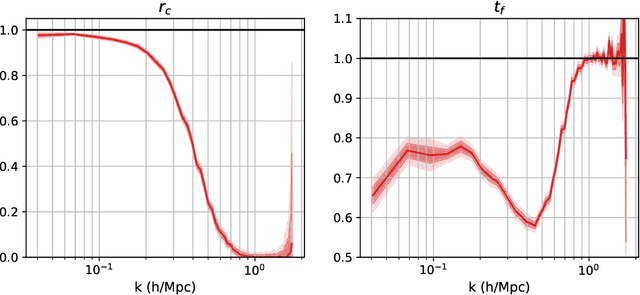
Forward modeling approaches in cosmology have made it possible to reconstruct the initial conditions at the beginning of the Universe from the observed survey data. However the high dimensionality of the parameter space still poses a challenge to explore the full posterior, with traditional algorithms such as Hamiltonian Monte Carlo (HMC) being computationally inefficient due to generating correlated samples and the performance of variational inference being highly dependent on the choice of divergence (loss) function. Here we develop a hybrid scheme, called variational self-boosted sampling (VBS) to mitigate the drawbacks of both these algorithms by learning a variational approximation for the proposal distribution of Monte Carlo sampling and combine it with HMC. The variational distribution is parameterized as a normalizing flow and learnt with samples generated on the fly, while proposals drawn from it reduce auto-correlation length in MCMC chains. Our normalizing flow uses Fourier space convolutions and element-wise operations to scale to high dimensions. We show that after a short initial warm-up and training phase, VBS generates better quality of samples than simple VI approaches and reduces the correlation length in the sampling phase by a factor of 10-50 over using only HMC to explore the posterior of initial conditions in 64$^3$ and 128$^3$ dimensional problems, with larger gains for high signal-to-noise data observations.
Estimating Social Influence from Observational Data
Mar 24, 2022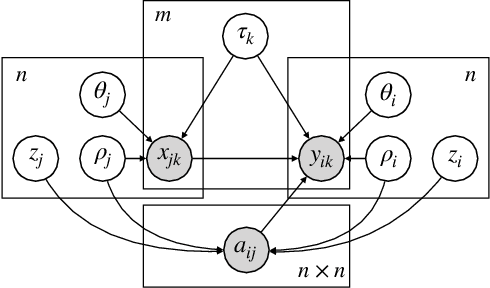
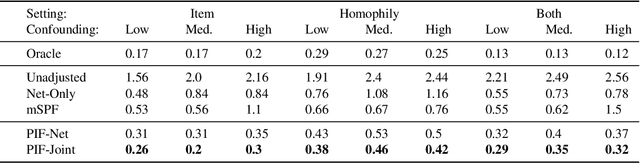
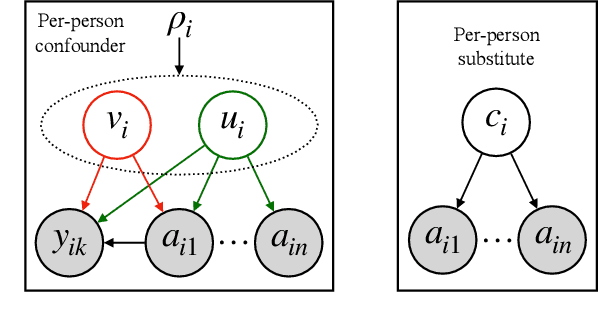
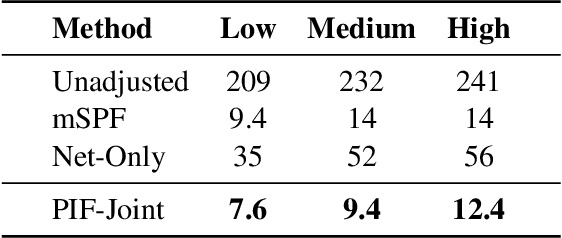
We consider the problem of estimating social influence, the effect that a person's behavior has on the future behavior of their peers. The key challenge is that shared behavior between friends could be equally explained by influence or by two other confounding factors: 1) latent traits that caused people to both become friends and engage in the behavior, and 2) latent preferences for the behavior. This paper addresses the challenges of estimating social influence with three contributions. First, we formalize social influence as a causal effect, one which requires inferences about hypothetical interventions. Second, we develop Poisson Influence Factorization (PIF), a method for estimating social influence from observational data. PIF fits probabilistic factor models to networks and behavior data to infer variables that serve as substitutes for the confounding latent traits. Third, we develop assumptions under which PIF recovers estimates of social influence. We empirically study PIF with semi-synthetic and real data from Last.fm, and conduct a sensitivity analysis. We find that PIF estimates social influence most accurately compared to related methods and remains robust under some violations of its assumptions.
Variational Combinatorial Sequential Monte Carlo Methods for Bayesian Phylogenetic Inference
Jun 17, 2021
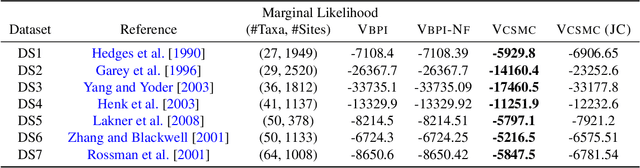
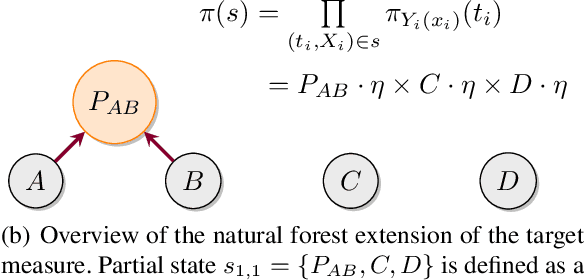
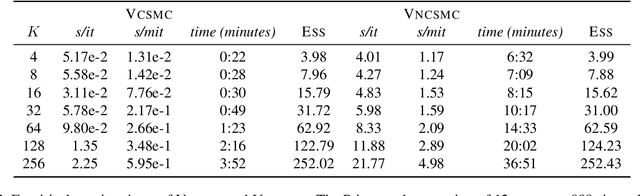
Bayesian phylogenetic inference is often conducted via local or sequential search over topologies and branch lengths using algorithms such as random-walk Markov chain Monte Carlo (MCMC) or Combinatorial Sequential Monte Carlo (CSMC). However, when MCMC is used for evolutionary parameter learning, convergence requires long runs with inefficient exploration of the state space. We introduce Variational Combinatorial Sequential Monte Carlo (VCSMC), a powerful framework that establishes variational sequential search to learn distributions over intricate combinatorial structures. We then develop nested CSMC, an efficient proposal distribution for CSMC and prove that nested CSMC is an exact approximation to the (intractable) locally optimal proposal. We use nested CSMC to define a second objective, VNCSMC which yields tighter lower bounds than VCSMC. We show that VCSMC and VNCSMC are computationally efficient and explore higher probability spaces than existing methods on a range of tasks.
Hierarchical Inducing Point Gaussian Process for Inter-domain Observations
Feb 28, 2021
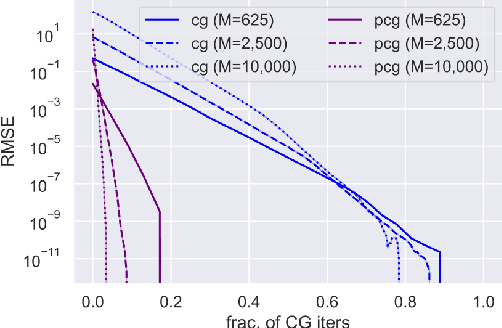
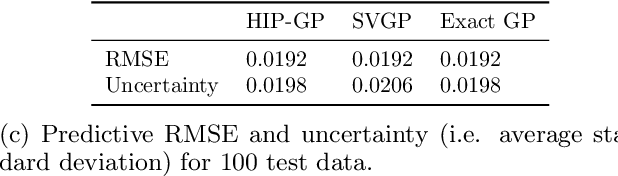
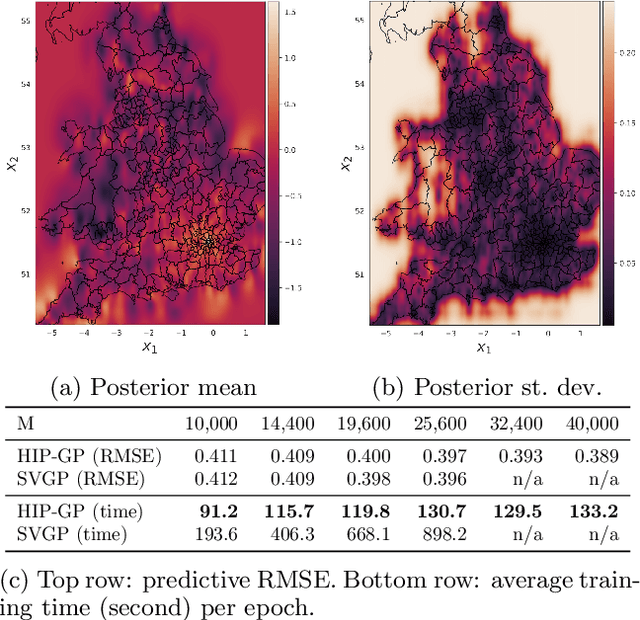
We examine the general problem of inter-domain Gaussian Processes (GPs): problems where the GP realization and the noisy observations of that realization lie on different domains. When the mapping between those domains is linear, such as integration or differentiation, inference is still closed form. However, many of the scaling and approximation techniques that our community has developed do not apply to this setting. In this work, we introduce the hierarchical inducing point GP (HIP-GP), a scalable inter-domain GP inference method that enables us to improve the approximation accuracy by increasing the number of inducing points to the millions. HIP-GP, which relies on inducing points with grid structure and a stationary kernel assumption, is suitable for low-dimensional problems. In developing HIP-GP, we introduce (1) a fast whitening strategy, and (2) a novel preconditioner for conjugate gradients which can be helpful in general GP settings.
Invariant Representation Learning for Treatment Effect Estimation
Nov 24, 2020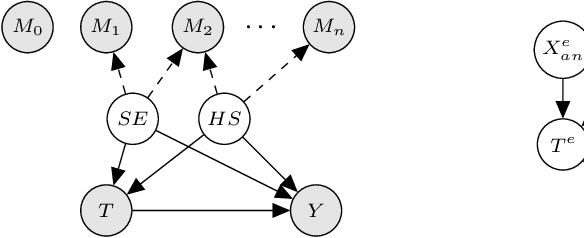
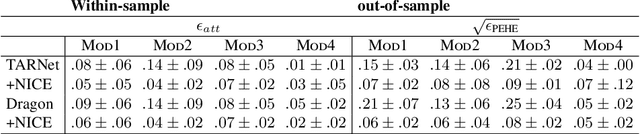
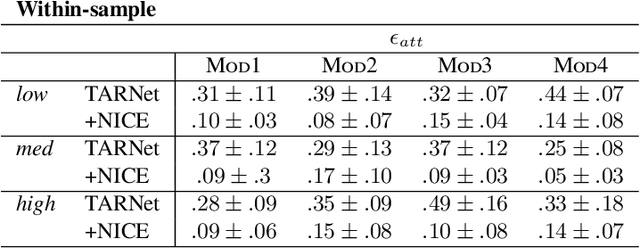
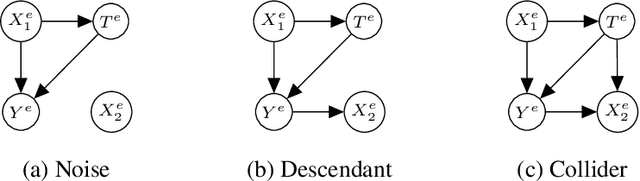
The defining challenge for causal inference from observational data is the presence of `confounders', covariates that affect both treatment assignment and the outcome. To address this challenge, practitioners collect and adjust for the covariates, hoping that they adequately correct for confounding. However, including every observed covariate in the adjustment runs the risk of including `bad controls', variables that \emph{induce} bias when they are conditioned on. The problem is that we do not always know which variables in the covariate set are safe to adjust for and which are not. To address this problem, we develop Nearly Invariant Causal Estimation (NICE). NICE uses invariant risk minimization (IRM) [Arj19] to learn a representation of the covariates that, under some assumptions, strips out bad controls but preserves sufficient information to adjust for confounding. Adjusting for the learned representation, rather than the covariates themselves, avoids the induced bias and provides valid causal inferences. NICE is appropriate in the following setting. i) We observe data from multiple environments that share a common causal mechanism for the outcome, but that differ in other ways. ii) In each environment, the collected covariates are a superset of the causal parents of the outcome, and contain sufficient information for causal identification. iii) But the covariates also may contain bad controls, and it is unknown which covariates are safe to adjust for and which ones induce bias. We evaluate NICE on both synthetic and semi-synthetic data. When the covariates contain unknown collider variables and other bad controls, NICE performs better than existing methods that adjust for all the covariates.
Markovian Score Climbing: Variational Inference with KL(p||q)
Mar 23, 2020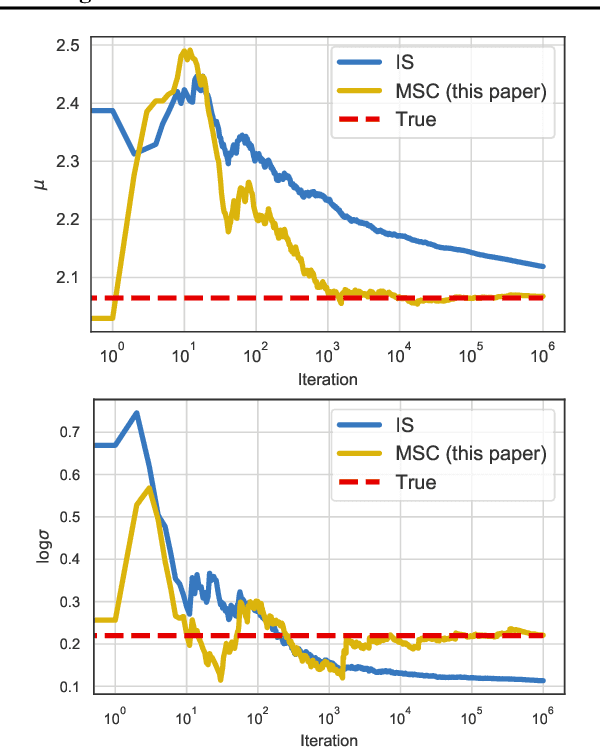

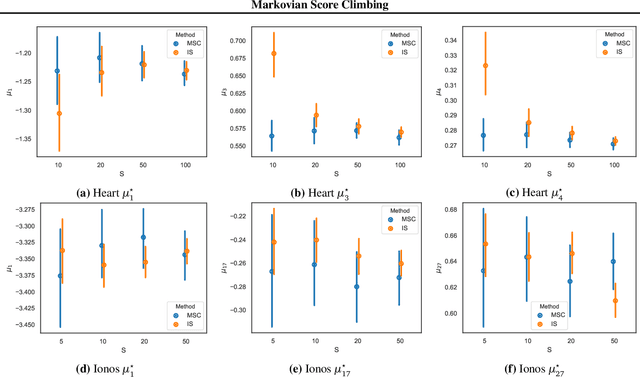
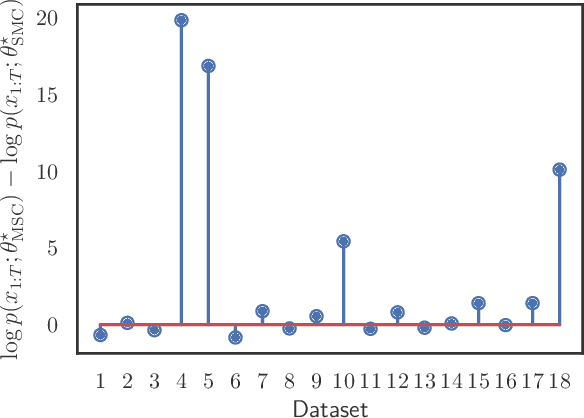
Modern variational inference (VI) uses stochastic gradients to avoid intractable expectations, enabling large-scale probabilistic inference in complex models. VI posits a family of approximating distributions $q$ and then finds the member of that family that is closest to the exact posterior $p$. Traditionally, VI algorithms minimize the "exclusive KL" KL$(q\|p)$, often for computational convenience. Recent research, however, has also focused on the "inclusive KL" KL$(p\|q)$, which has good statistical properties that makes it more appropriate for certain inference problems. This paper develops a simple algorithm for reliably minimizing the inclusive KL. Consider a valid MCMC method, a Markov chain whose stationary distribution is $p$. The algorithm we develop iteratively samples the chain $z[k]$, and then uses those samples to follow the score function of the variational approximation, $\nabla \log q(z[k])$ with a Robbins-Monro step-size schedule. This method, which we call Markovian score climbing (MSC), converges to a local optimum of the inclusive KL. It does not suffer from the systematic errors inherent in existing methods, such as Reweighted Wake-Sleep and Neural Adaptive Sequential Monte Carlo, which lead to bias in their final estimates. In a variant that ties the variational approximation directly to the Markov chain, MSC further provides a new algorithm that melds VI and MCMC. We illustrate convergence on a toy model and demonstrate the utility of MSC on Bayesian probit regression for classification as well as a stochastic volatility model for financial data.
General linear-time inference for Gaussian Processes on one dimension
Mar 11, 2020
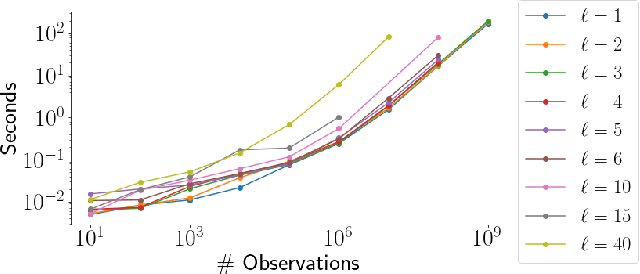
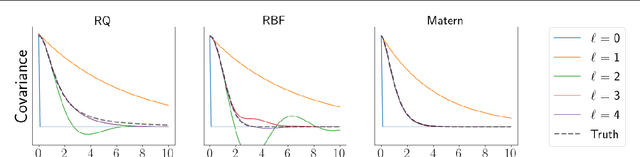
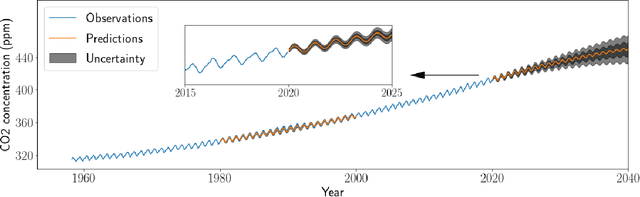
Gaussian Processes (GPs) provide a powerful probabilistic framework for interpolation, forecasting, and smoothing, but have been hampered by computational scaling issues. Here we prove that for data sampled on one dimension (e.g., a time series sampled at arbitrarily-spaced intervals), approximate GP inference at any desired level of accuracy requires computational effort that scales linearly with the number of observations; this new theorem enables inference on much larger datasets than was previously feasible. To achieve this improved scaling we propose a new family of stationary covariance kernels: the Latent Exponentially Generated (LEG) family, which admits a convenient stable state-space representation that allows linear-time inference. We prove that any continuous integrable stationary kernel can be approximated arbitrarily well by some member of the LEG family. The proof draws connections to Spectral Mixture Kernels, providing new insight about the flexibility of this popular family of kernels. We propose parallelized algorithms for performing inference and learning in the LEG model, test the algorithm on real and synthetic data, and demonstrate scaling to datasets with billions of samples.