 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompliance-Aware Bandits
Feb 09, 2016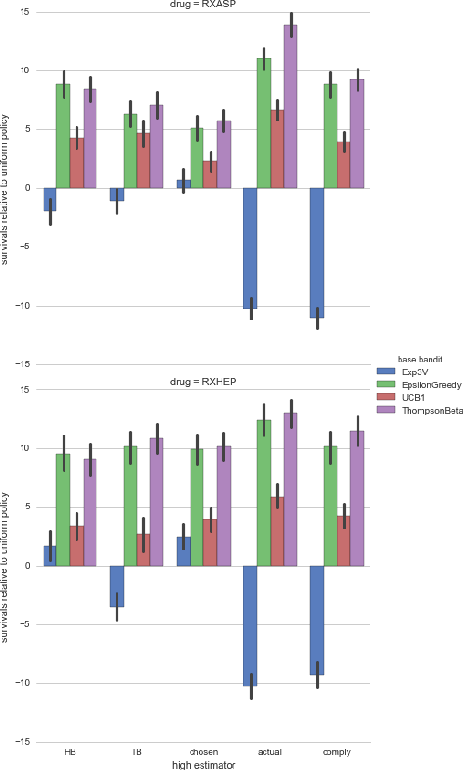
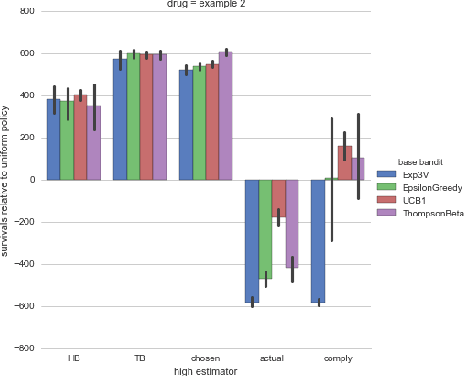
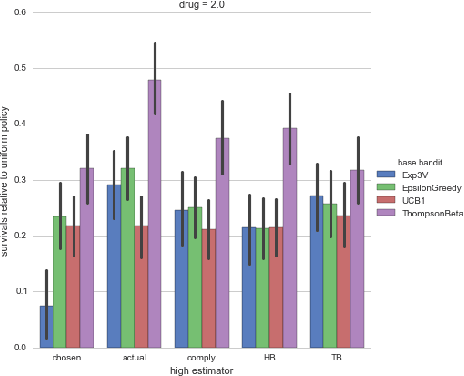
Motivated by clinical trials, we study bandits with observable non-compliance. At each step, the learner chooses an arm, after, instead of observing only the reward, it also observes the action that took place. We show that such noncompliance can be helpful or hurtful to the learner in general. Unfortunately, naively incorporating compliance information into bandit algorithms loses guarantees on sublinear regret. We present hybrid algorithms that maintain regret bounds up to a multiplicative factor and can incorporate compliance information. Simulations based on real data from the International Stoke Trial show the practical potential of these algorithms.
Semantics, Representations and Grammars for Deep Learning
Sep 29, 2015Deep learning is currently the subject of intensive study. However, fundamental concepts such as representations are not formally defined -- researchers "know them when they see them" -- and there is no common language for describing and analyzing algorithms. This essay proposes an abstract framework that identifies the essential features of current practice and may provide a foundation for future developments. The backbone of almost all deep learning algorithms is backpropagation, which is simply a gradient computation distributed over a neural network. The main ingredients of the framework are thus, unsurprisingly: (i) game theory, to formalize distributed optimization; and (ii) communication protocols, to track the flow of zeroth and first-order information. The framework allows natural definitions of semantics (as the meaning encoded in functions), representations (as functions whose semantics is chosen to optimized a criterion) and grammars (as communication protocols equipped with first-order convergence guarantees). Much of the essay is spent discussing examples taken from the literature. The ultimate aim is to develop a graphical language for describing the structure of deep learning algorithms that backgrounds the details of the optimization procedure and foregrounds how the components interact. Inspiration is taken from probabilistic graphical models and factor graphs, which capture the essential structural features of multivariate distributions.
Compatible Value Gradients for Reinforcement Learning of Continuous Deep Policies
Sep 10, 2015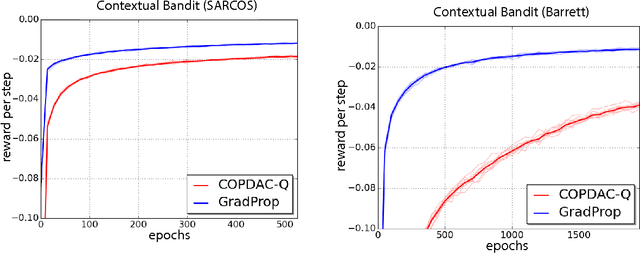
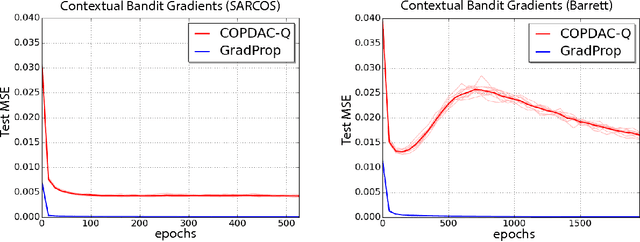
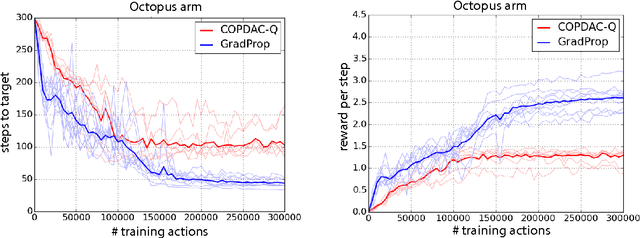
This paper proposes GProp, a deep reinforcement learning algorithm for continuous policies with compatible function approximation. The algorithm is based on two innovations. Firstly, we present a temporal-difference based method for learning the gradient of the value-function. Secondly, we present the deviator-actor-critic (DAC) model, which comprises three neural networks that estimate the value function, its gradient, and determine the actor's policy respectively. We evaluate GProp on two challenging tasks: a contextual bandit problem constructed from nonparametric regression datasets that is designed to probe the ability of reinforcement learning algorithms to accurately estimate gradients; and the octopus arm, a challenging reinforcement learning benchmark. GProp is competitive with fully supervised methods on the bandit task and achieves the best performance to date on the octopus arm.
Domain Generalization for Object Recognition with Multi-task Autoencoders
Aug 31, 2015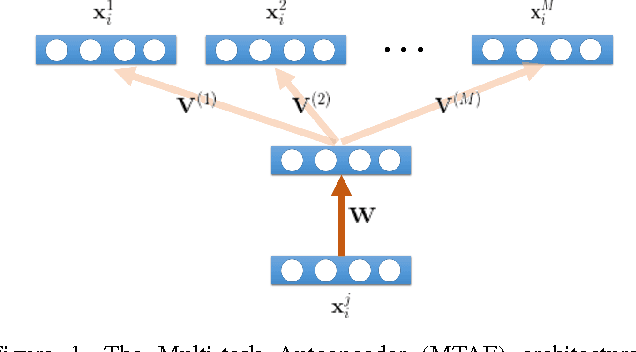
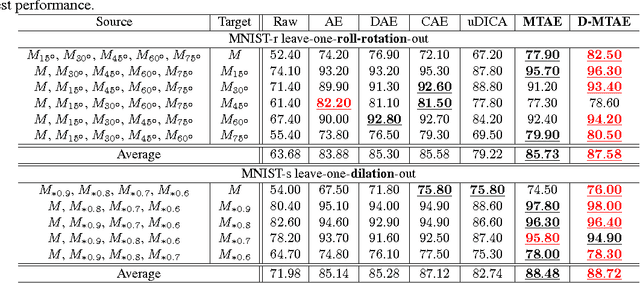

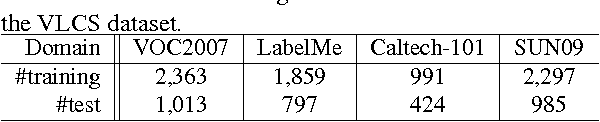
The problem of domain generalization is to take knowledge acquired from a number of related domains where training data is available, and to then successfully apply it to previously unseen domains. We propose a new feature learning algorithm, Multi-Task Autoencoder (MTAE), that provides good generalization performance for cross-domain object recognition. Our algorithm extends the standard denoising autoencoder framework by substituting artificially induced corruption with naturally occurring inter-domain variability in the appearance of objects. Instead of reconstructing images from noisy versions, MTAE learns to transform the original image into analogs in multiple related domains. It thereby learns features that are robust to variations across domains. The learnt features are then used as inputs to a classifier. We evaluated the performance of the algorithm on benchmark image recognition datasets, where the task is to learn features from multiple datasets and to then predict the image label from unseen datasets. We found that (denoising) MTAE outperforms alternative autoencoder-based models as well as the current state-of-the-art algorithms for domain generalization.
Kickback cuts Backprop's red-tape: Biologically plausible credit assignment in neural networks
Nov 23, 2014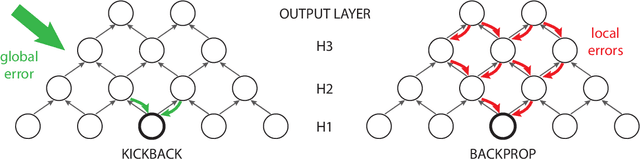
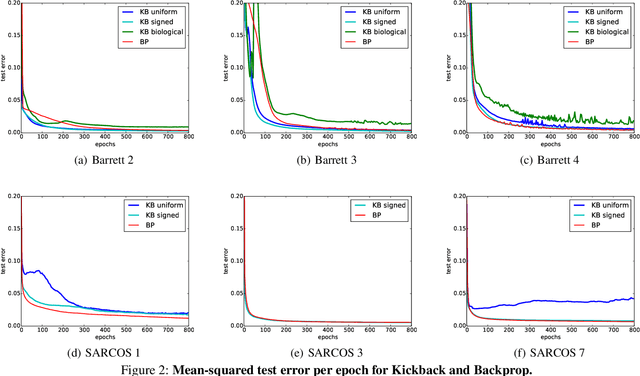
Error backpropagation is an extremely effective algorithm for assigning credit in artificial neural networks. However, weight updates under Backprop depend on lengthy recursive computations and require separate output and error messages -- features not shared by biological neurons, that are perhaps unnecessary. In this paper, we revisit Backprop and the credit assignment problem. We first decompose Backprop into a collection of interacting learning algorithms; provide regret bounds on the performance of these sub-algorithms; and factorize Backprop's error signals. Using these results, we derive a new credit assignment algorithm for nonparametric regression, Kickback, that is significantly simpler than Backprop. Finally, we provide a sufficient condition for Kickback to follow error gradients, and show that Kickback matches Backprop's performance on real-world regression benchmarks.
Falsifiable implies Learnable
Aug 28, 2014The paper demonstrates that falsifiability is fundamental to learning. We prove the following theorem for statistical learning and sequential prediction: If a theory is falsifiable then it is learnable -- i.e. admits a strategy that predicts optimally. An analogous result is shown for universal induction.
Cortical prediction markets
Jan 07, 2014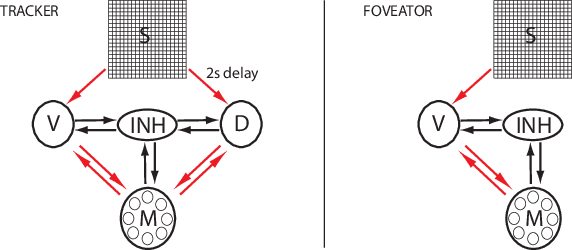
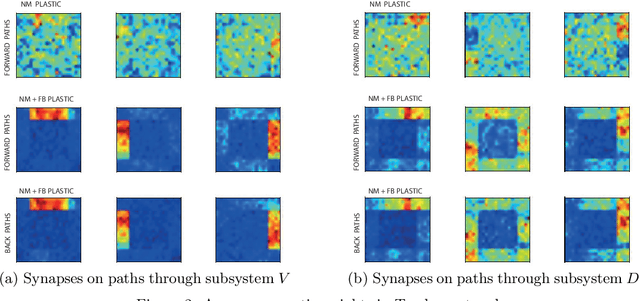
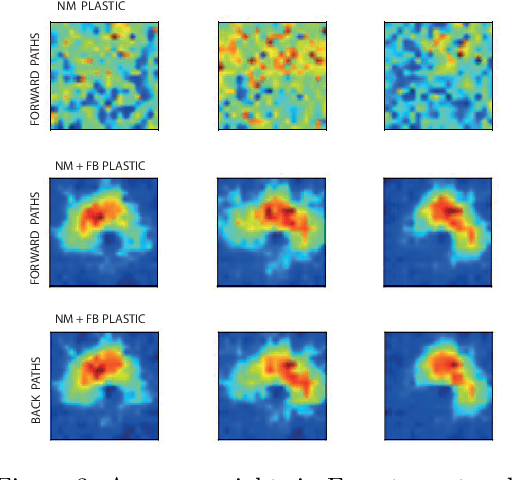
We investigate cortical learning from the perspective of mechanism design. First, we show that discretizing standard models of neurons and synaptic plasticity leads to rational agents maximizing simple scoring rules. Second, our main result is that the scoring rules are proper, implying that neurons faithfully encode expected utilities in their synaptic weights and encode high-scoring outcomes in their spikes. Third, with this foundation in hand, we propose a biologically plausible mechanism whereby neurons backpropagate incentives which allows them to optimize their usefulness to the rest of cortex. Finally, experiments show that networks that backpropagate incentives can learn simple tasks.
Correlated random features for fast semi-supervised learning
Nov 05, 2013
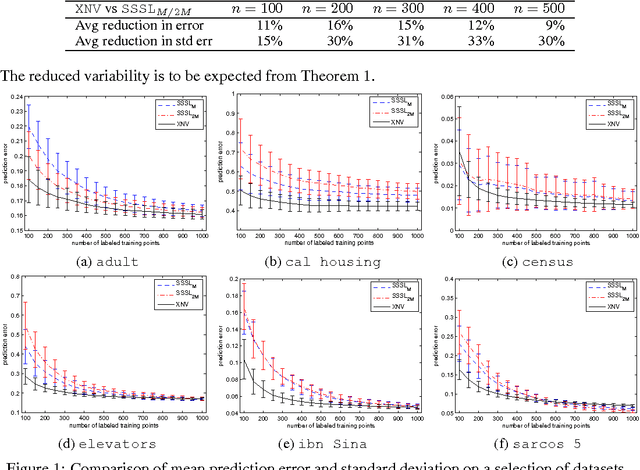
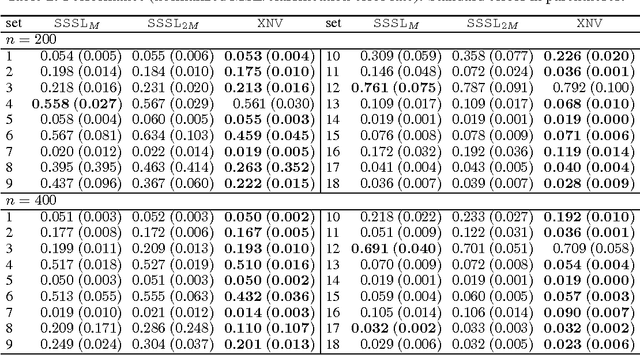
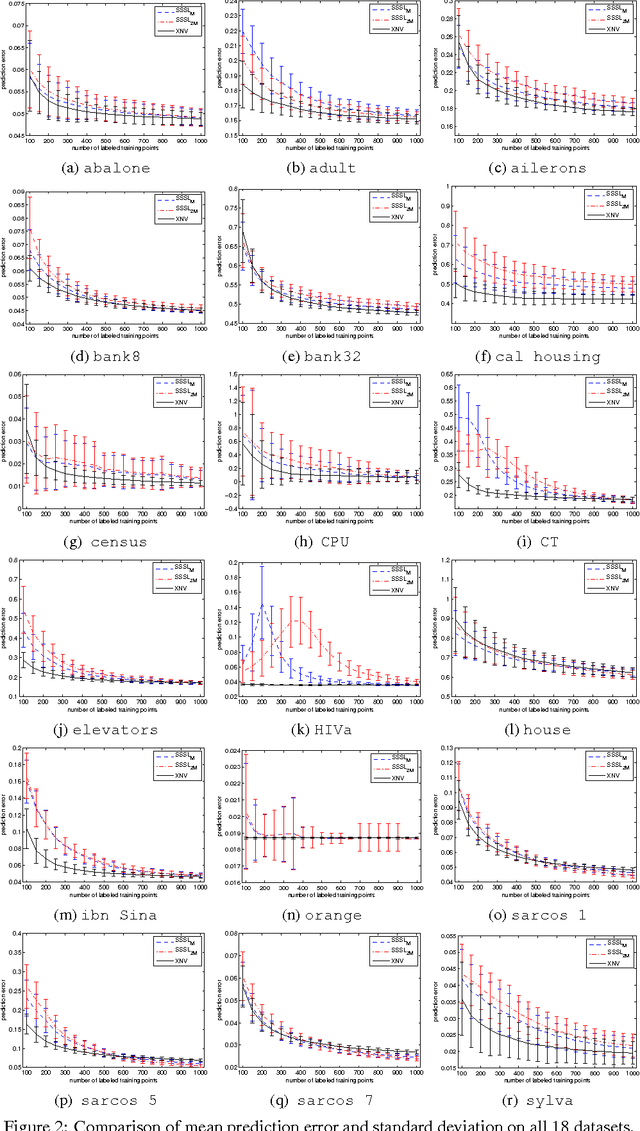
This paper presents Correlated Nystrom Views (XNV), a fast semi-supervised algorithm for regression and classification. The algorithm draws on two main ideas. First, it generates two views consisting of computationally inexpensive random features. Second, XNV applies multiview regression using Canonical Correlation Analysis (CCA) on unlabeled data to bias the regression towards useful features. It has been shown that, if the views contains accurate estimators, CCA regression can substantially reduce variance with a minimal increase in bias. Random views are justified by recent theoretical and empirical work showing that regression with random features closely approximates kernel regression, implying that random views can be expected to contain accurate estimators. We show that XNV consistently outperforms a state-of-the-art algorithm for semi-supervised learning: substantially improving predictive performance and reducing the variability of performance on a wide variety of real-world datasets, whilst also reducing runtime by orders of magnitude.
Randomized co-training: from cortical neurons to machine learning and back again
Oct 24, 2013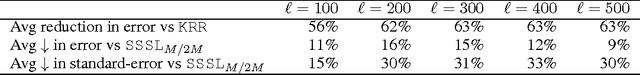
Despite its size and complexity, the human cortex exhibits striking anatomical regularities, suggesting there may simple meta-algorithms underlying cortical learning and computation. We expect such meta-algorithms to be of interest since they need to operate quickly, scalably and effectively with little-to-no specialized assumptions. This note focuses on a specific question: How can neurons use vast quantities of unlabeled data to speed up learning from the comparatively rare labels provided by reward systems? As a partial answer, we propose randomized co-training as a biologically plausible meta-algorithm satisfying the above requirements. As evidence, we describe a biologically-inspired algorithm, Correlated Nystrom Views (XNV) that achieves state-of-the-art performance in semi-supervised learning, and sketch work in progress on a neuronal implementation.
Metabolic cost as an organizing principle for cooperative learning
Feb 09, 2013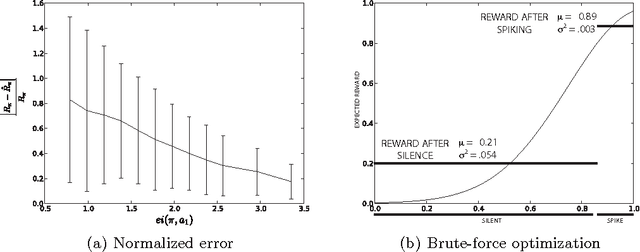
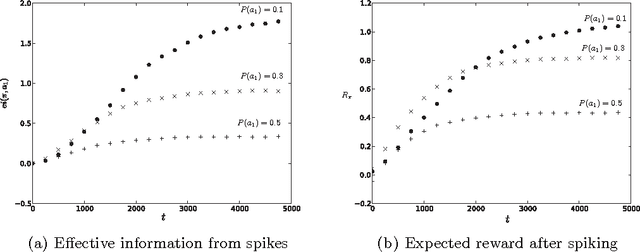
This paper investigates how neurons can use metabolic cost to facilitate learning at a population level. Although decision-making by individual neurons has been extensively studied, questions regarding how neurons should behave to cooperate effectively remain largely unaddressed. Under assumptions that capture a few basic features of cortical neurons, we show that constraining reward maximization by metabolic cost aligns the information content of actions with their expected reward. Thus, metabolic cost provides a mechanism whereby neurons encode expected reward into their outputs. Further, aside from reducing energy expenditures, imposing a tight metabolic constraint also increases the accuracy of empirical estimates of rewards, increasing the robustness of distributed learning. Finally, we present two implementations of metabolically constrained learning that confirm our theoretical finding. These results suggest that metabolic cost may be an organizing principle underlying the neural code, and may also provide a useful guide to the design and analysis of other cooperating populations.