 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXPhoneBERT: A Pre-trained Multilingual Model for Phoneme Representations for Text-to-Speech
May 31, 2023We present XPhoneBERT, the first multilingual model pre-trained to learn phoneme representations for the downstream text-to-speech (TTS) task. Our XPhoneBERT has the same model architecture as BERT-base, trained using the RoBERTa pre-training approach on 330M phoneme-level sentences from nearly 100 languages and locales. Experimental results show that employing XPhoneBERT as an input phoneme encoder significantly boosts the performance of a strong neural TTS model in terms of naturalness and prosody and also helps produce fairly high-quality speech with limited training data. We publicly release our pre-trained XPhoneBERT with the hope that it would facilitate future research and downstream TTS applications for multiple languages. Our XPhoneBERT model is available at https://github.com/VinAIResearch/XPhoneBERT
Joint Multilingual Knowledge Graph Completion and Alignment
Oct 18, 2022
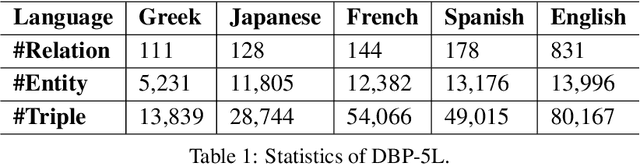
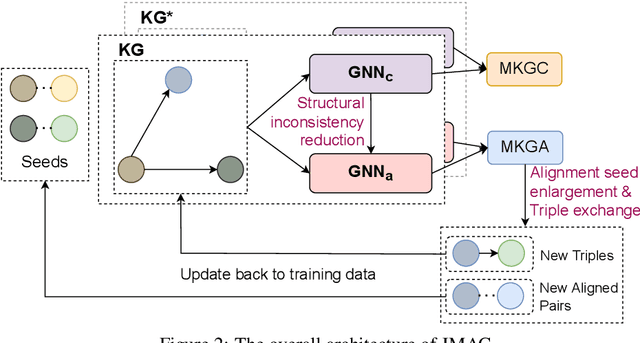
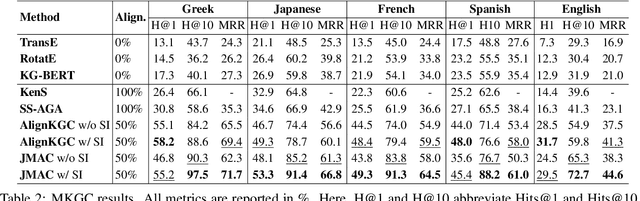
Knowledge graph (KG) alignment and completion are usually treated as two independent tasks. While recent work has leveraged entity and relation alignments from multiple KGs, such as alignments between multilingual KGs with common entities and relations, a deeper understanding of the ways in which multilingual KG completion (MKGC) can aid the creation of multilingual KG alignments (MKGA) is still limited. Motivated by the observation that structural inconsistencies -- the main challenge for MKGA models -- can be mitigated through KG completion methods, we propose a novel model for jointly completing and aligning knowledge graphs. The proposed model combines two components that jointly accomplish KG completion and alignment. These two components employ relation-aware graph neural networks that we propose to encode multi-hop neighborhood structures into entity and relation representations. Moreover, we also propose (i) a structural inconsistency reduction mechanism to incorporate information from the completion into the alignment component, and (ii) an alignment seed enlargement and triple transferring mechanism to enlarge alignment seeds and transfer triples during KGs alignment. Extensive experiments on a public multilingual benchmark show that our proposed model outperforms existing competitive baselines, obtaining new state-of-the-art results on both MKGC and MKGA tasks. We publicly release the implementation of our model at https://github.com/vinhsuhi/JMAC
From Disfluency Detection to Intent Detection and Slot Filling
Sep 17, 2022
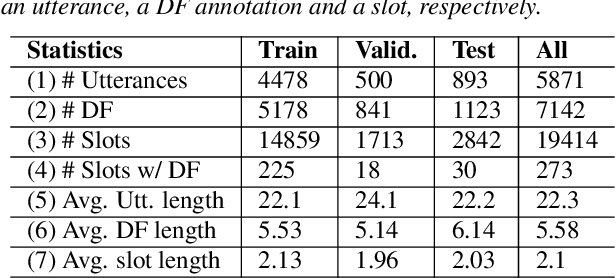
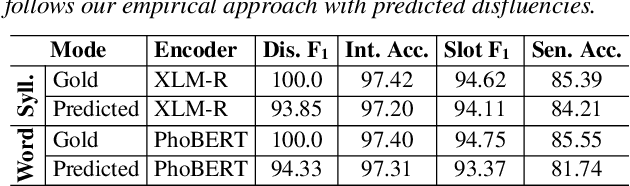

We present the first empirical study investigating the influence of disfluency detection on downstream tasks of intent detection and slot filling. We perform this study for Vietnamese -- a low-resource language that has no previous study as well as no public dataset available for disfluency detection. First, we extend the fluent Vietnamese intent detection and slot filling dataset PhoATIS by manually adding contextual disfluencies and annotating them. Then, we conduct experiments using strong baselines for disfluency detection and joint intent detection and slot filling, which are based on pre-trained language models. We find that: (i) disfluencies produce negative effects on the performances of the downstream intent detection and slot filling tasks, and (ii) in the disfluency context, the pre-trained multilingual language model XLM-R helps produce better intent detection and slot filling performances than the pre-trained monolingual language model PhoBERT, and this is opposite to what generally found in the fluency context.
A High-Quality and Large-Scale Dataset for English-Vietnamese Speech Translation
Aug 08, 2022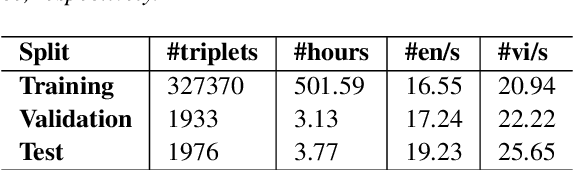


In this paper, we introduce a high-quality and large-scale benchmark dataset for English-Vietnamese speech translation with 508 audio hours, consisting of 331K triplets of (sentence-lengthed audio, English source transcript sentence, Vietnamese target subtitle sentence). We also conduct empirical experiments using strong baselines and find that the traditional "Cascaded" approach still outperforms the modern "End-to-End" approach. To the best of our knowledge, this is the first large-scale English-Vietnamese speech translation study. We hope both our publicly available dataset and study can serve as a starting point for future research and applications on English-Vietnamese speech translation. Our dataset is available at https://github.com/VinAIResearch/PhoST
Two-view Graph Neural Networks for Knowledge Graph Completion
Dec 16, 2021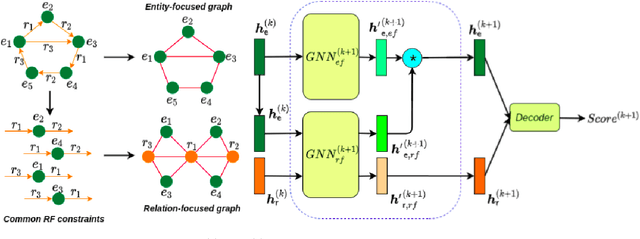
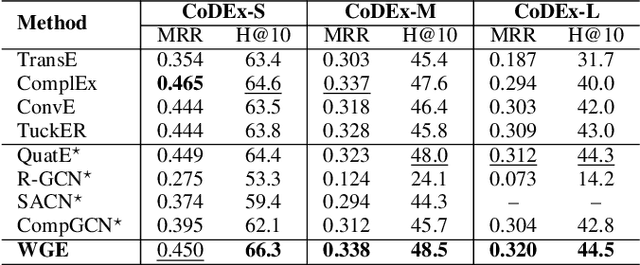
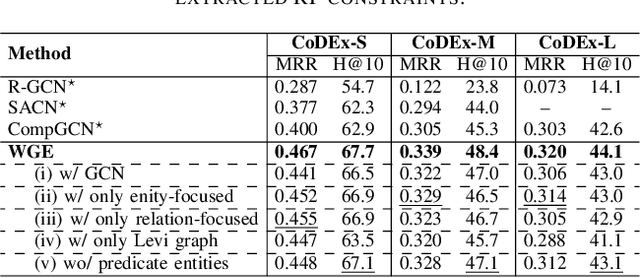
In this paper, we introduce a novel GNN-based knowledge graph embedding model, named WGE, to capture entity-focused graph structure and relation-focused graph structure. In particular, given the knowledge graph, WGE builds a single undirected entity-focused graph that views entities as nodes. In addition, WGE also constructs another single undirected graph from relation-focused constraints, which views entities and relations as nodes. WGE then proposes a new architecture of utilizing two vanilla GNNs directly on these two single graphs to better update vector representations of entities and relations, followed by a weighted score function to return the triple scores. Experimental results show that WGE obtains state-of-the-art performances on three new and challenging benchmark datasets CoDEx for knowledge graph completion.
PhoMT: A High-Quality and Large-Scale Benchmark Dataset for Vietnamese-English Machine Translation
Oct 23, 2021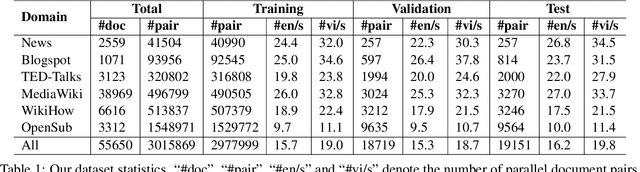
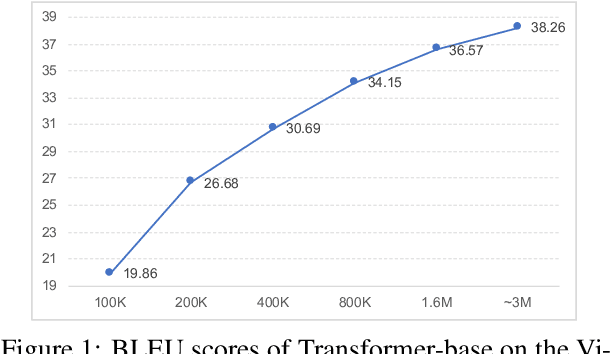
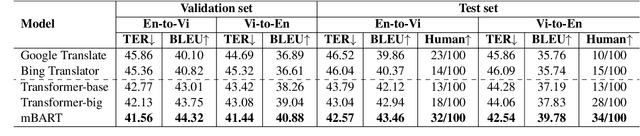
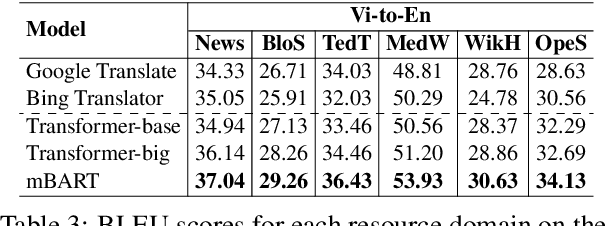
We introduce a high-quality and large-scale Vietnamese-English parallel dataset of 3.02M sentence pairs, which is 2.9M pairs larger than the benchmark Vietnamese-English machine translation corpus IWSLT15. We conduct experiments comparing strong neural baselines and well-known automatic translation engines on our dataset and find that in both automatic and human evaluations: the best performance is obtained by fine-tuning the pre-trained sequence-to-sequence denoising auto-encoder mBART. To our best knowledge, this is the first large-scale Vietnamese-English machine translation study. We hope our publicly available dataset and study can serve as a starting point for future research and applications on Vietnamese-English machine translation.
BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese
Sep 20, 2021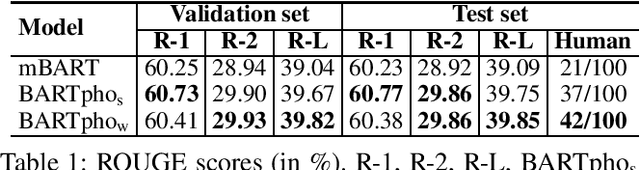
We present BARTpho with two versions -- BARTpho_word and BARTpho_syllable -- the first public large-scale monolingual sequence-to-sequence models pre-trained for Vietnamese. Our BARTpho uses the "large" architecture and pre-training scheme of the sequence-to-sequence denoising model BART, thus especially suitable for generative NLP tasks. Experiments on a downstream task of Vietnamese text summarization show that in both automatic and human evaluations, our BARTpho outperforms the strong baseline mBART and improves the state-of-the-art. We release BARTpho to facilitate future research and applications of generative Vietnamese NLP tasks. Our BARTpho models are available at: https://github.com/VinAIResearch/BARTpho
Node Co-occurrence based Graph Neural Networks for Knowledge Graph Link Prediction
Apr 15, 2021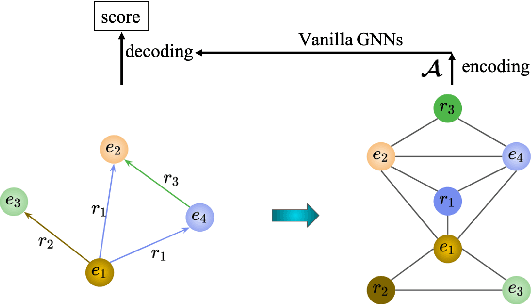
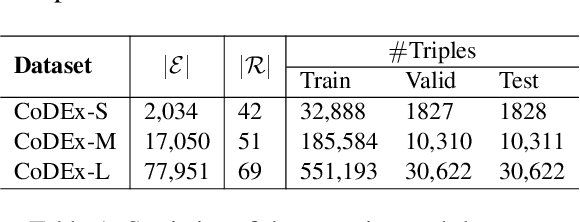
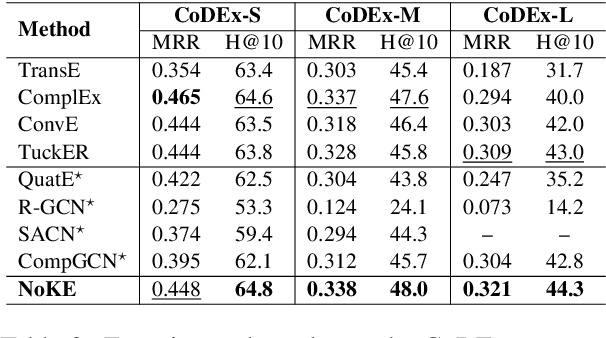
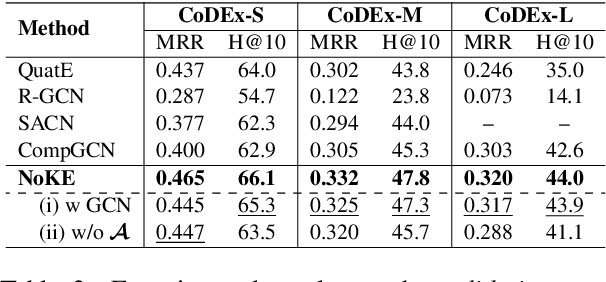
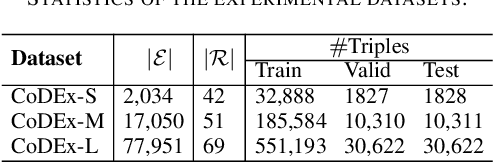
We introduce a novel embedding model, named NoKE, which aims to integrate co-occurrence among entities and relations into graph neural networks to improve knowledge graph completion (i.e., link prediction). Given a knowledge graph, NoKE constructs a single graph considering entities and relations as individual nodes. NoKE then computes weights for edges among nodes based on the co-occurrence of entities and relations. Next, NoKE utilizes vanilla GNNs to update vector representations for entity and relation nodes and then adopts a score function to produce the triple scores. Comprehensive experimental results show that our NoKE obtains state-of-the-art results on three new, challenging, and difficult benchmark datasets CoDEx for knowledge graph completion, demonstrating the power of its simplicity and effectiveness.
COVID-19 Named Entity Recognition for Vietnamese
Apr 08, 2021
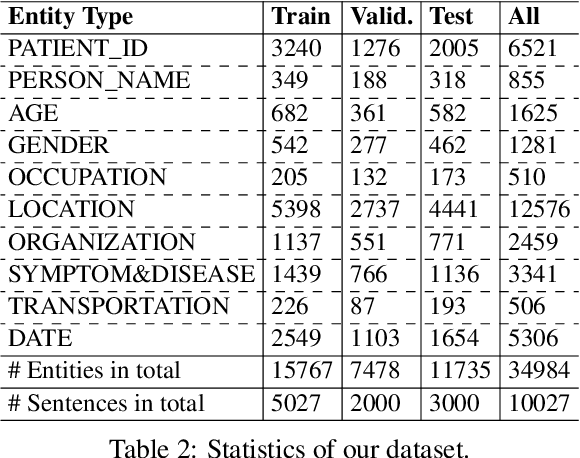
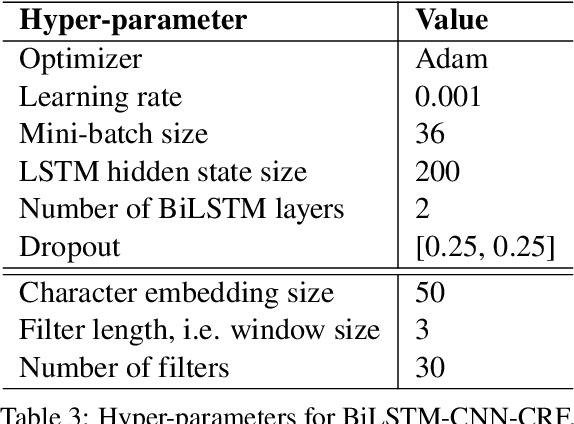
The current COVID-19 pandemic has lead to the creation of many corpora that facilitate NLP research and downstream applications to help fight the pandemic. However, most of these corpora are exclusively for English. As the pandemic is a global problem, it is worth creating COVID-19 related datasets for languages other than English. In this paper, we present the first manually-annotated COVID-19 domain-specific dataset for Vietnamese. Particularly, our dataset is annotated for the named entity recognition (NER) task with newly-defined entity types that can be used in other future epidemics. Our dataset also contains the largest number of entities compared to existing Vietnamese NER datasets. We empirically conduct experiments using strong baselines on our dataset, and find that: automatic Vietnamese word segmentation helps improve the NER results and the highest performances are obtained by fine-tuning pre-trained language models where the monolingual model PhoBERT for Vietnamese (Nguyen and Nguyen, 2020) produces higher results than the multilingual model XLM-R (Conneau et al., 2020). We publicly release our dataset at: https://github.com/VinAIResearch/PhoNER_COVID19
Intent detection and slot filling for Vietnamese
Apr 05, 2021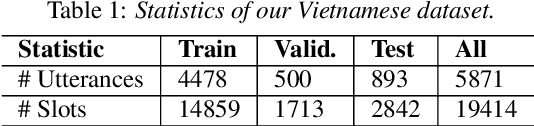
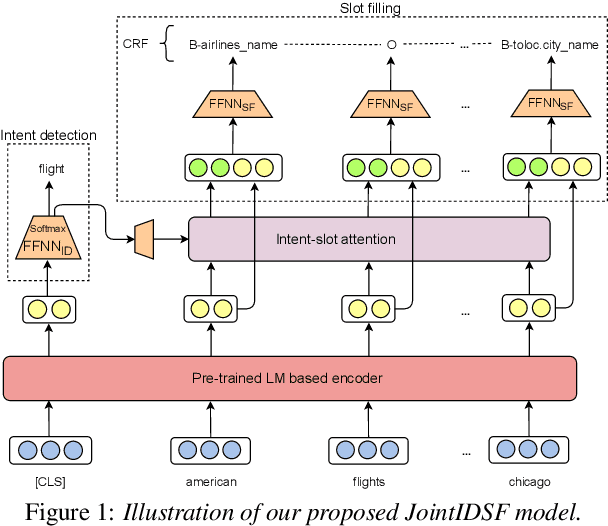


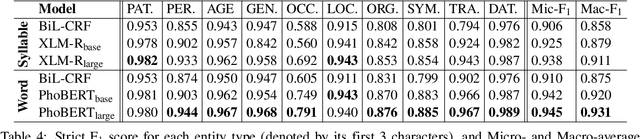
Intent detection and slot filling are important tasks in spoken and natural language understanding. However, Vietnamese is a low-resource language in these research topics. In this paper, we present the first public intent detection and slot filling dataset for Vietnamese. In addition, we also propose a joint model for intent detection and slot filling, that extends the recent state-of-the-art JointBERT+CRF model with an intent-slot attention layer in order to explicitly incorporate intent context information into slot filling via "soft" intent label embedding. Experimental results on our Vietnamese dataset show that our proposed model significantly outperforms JointBERT+CRF. We publicly release our dataset and the implementation of our model at: https://github.com/VinAIResearch/JointIDSF