 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine learning for structural design models of continuous beam systems via influence zones
Mar 14, 2024This work develops a machine learned structural design model for continuous beam systems from the inverse problem perspective. After demarcating between forward, optimisation and inverse machine learned operators, the investigation proposes a novel methodology based on the recently developed influence zone concept which represents a fundamental shift in approach compared to traditional structural design methods. The aim of this approach is to conceptualise a non-iterative structural design model that predicts cross-section requirements for continuous beam systems of arbitrary system size. After generating a dataset of known solutions, an appropriate neural network architecture is identified, trained, and tested against unseen data. The results show a mean absolute percentage testing error of 1.6% for cross-section property predictions, along with a good ability of the neural network to generalise well to structural systems of variable size. The CBeamXP dataset generated in this work and an associated python-based neural network training script are available at an open-source data repository to allow for the reproducibility of results and to encourage further investigations.
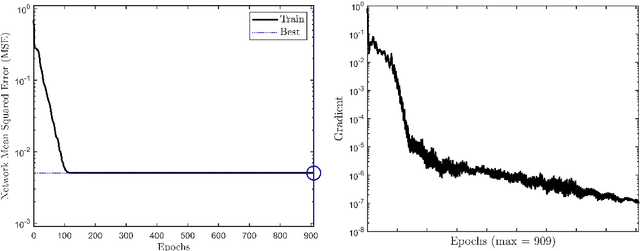
An efficient Quasi-Newton method for nonlinear inverse problems via learned singular values
Dec 14, 2020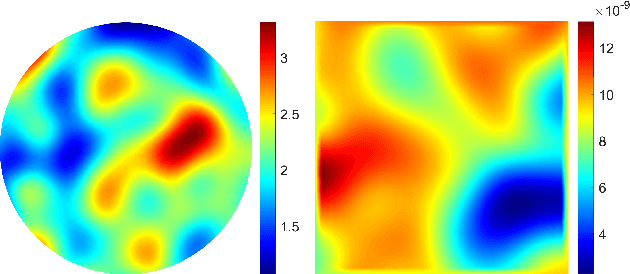
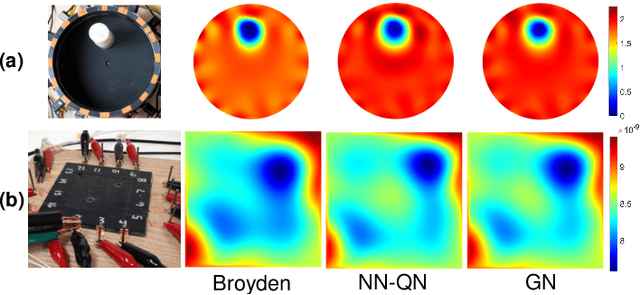

Solving complex optimization problems in engineering and the physical sciences requires repetitive computation of multi-dimensional function derivatives. Commonly, this requires computationally-demanding numerical differentiation such as perturbation techniques, which ultimately limits the use for time-sensitive applications. In particular, in nonlinear inverse problems Gauss-Newton methods are used that require iterative updates to be computed from the Jacobian. Computationally more efficient alternatives are Quasi-Newton methods, where the repeated computation of the Jacobian is replaced by an approximate update. Here we present a highly efficient data-driven Quasi-Newton method applicable to nonlinear inverse problems. We achieve this, by using the singular value decomposition and learning a mapping from model outputs to the singular values to compute the updated Jacobian. This enables a speed-up expected of Quasi-Newton methods without accumulating roundoff errors, enabling time-critical applications and allowing for flexible incorporation of prior knowledge necessary to solve ill-posed problems. We present results for the highly non-linear inverse problem of electrical impedance tomography with experimental data.
Optimizing electrode positions for 2D Electrical Impedance Tomography sensors using deep learning
Oct 21, 2019
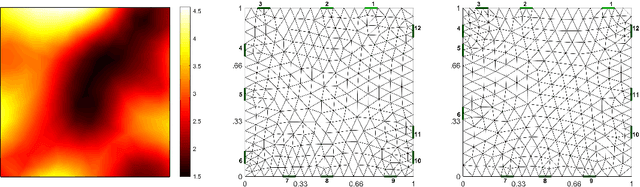
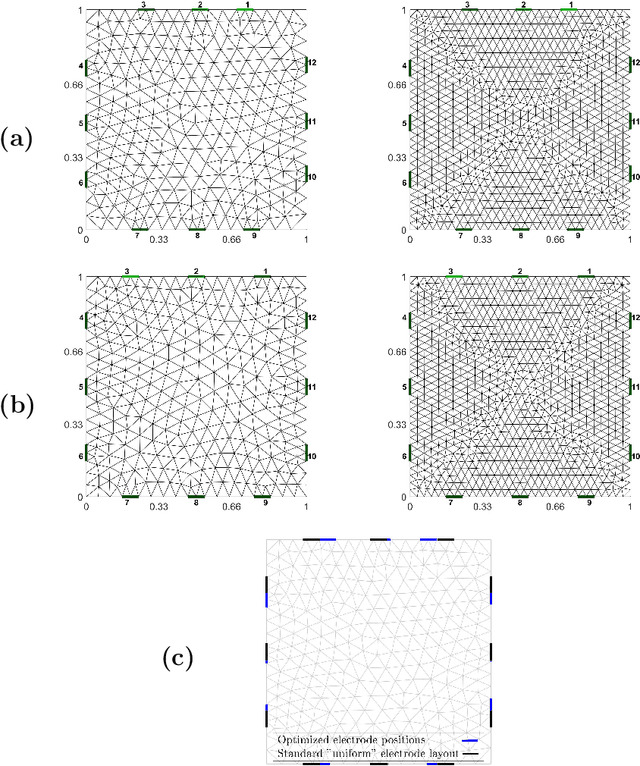
Electrical Impedance Tomography (EIT) is a powerful tool for non-destructive evaluation, state estimation, process tomography, and much more. For these applications, and in order to reliably reconstruct images of a given process using EIT, we must obtain high-quality voltage measurements from the EIT sensor (or structure) of interest. Inasmuch, it is no surprise that the locations of electrodes used for measuring plays a key role in this task. Yet, to date, methods for optimally placing electrodes either require knowledge on the EIT target (which is, in practice, never fully known), are computationally difficult to implement numerically, or require electrode segmentation. In this paper, we circumvent these challenges and present a straightforward deep learning based approach for optimizing electrodes positions. It is found that the optimized electrode positions outperformed "standard" uniformly-distributed electrode layouts in all test cases using a metric independent from the optimization parameters.