 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteraction Networks for Learning about Objects, Relations and Physics
Dec 01, 2016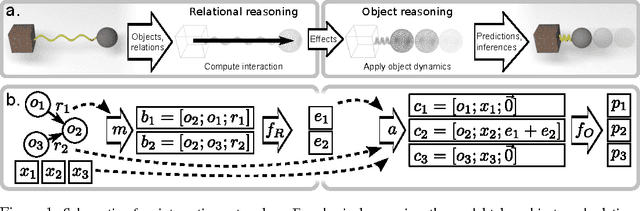


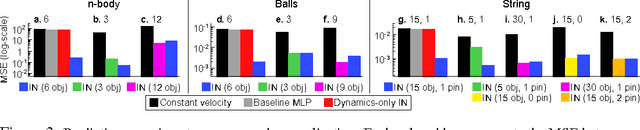
Reasoning about objects, relations, and physics is central to human intelligence, and a key goal of artificial intelligence. Here we introduce the interaction network, a model which can reason about how objects in complex systems interact, supporting dynamical predictions, as well as inferences about the abstract properties of the system. Our model takes graphs as input, performs object- and relation-centric reasoning in a way that is analogous to a simulation, and is implemented using deep neural networks. We evaluate its ability to reason about several challenging physical domains: n-body problems, rigid-body collision, and non-rigid dynamics. Our results show it can be trained to accurately simulate the physical trajectories of dozens of objects over thousands of time steps, estimate abstract quantities such as energy, and generalize automatically to systems with different numbers and configurations of objects and relations. Our interaction network implementation is the first general-purpose, learnable physics engine, and a powerful general framework for reasoning about object and relations in a wide variety of complex real-world domains.
Normalizing Flows on Riemannian Manifolds
Nov 09, 2016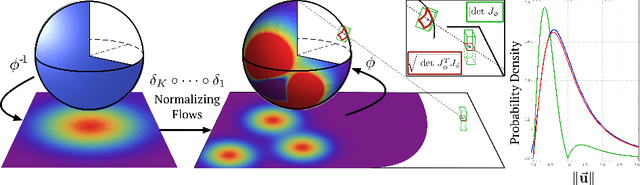
We consider the problem of density estimation on Riemannian manifolds. Density estimation on manifolds has many applications in fluid-mechanics, optics and plasma physics and it appears often when dealing with angular variables (such as used in protein folding, robot limbs, gene-expression) and in general directional statistics. In spite of the multitude of algorithms available for density estimation in the Euclidean spaces $\mathbf{R}^n$ that scale to large n (e.g. normalizing flows, kernel methods and variational approximations), most of these methods are not immediately suitable for density estimation in more general Riemannian manifolds. We revisit techniques related to homeomorphisms from differential geometry for projecting densities to sub-manifolds and use it to generalize the idea of normalizing flows to more general Riemannian manifolds. The resulting algorithm is scalable, simple to implement and suitable for use with automatic differentiation. We demonstrate concrete examples of this method on the n-sphere $\mathbf{S}^n$.
Towards Principled Unsupervised Learning
Dec 03, 2015
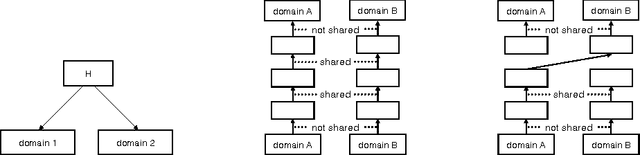

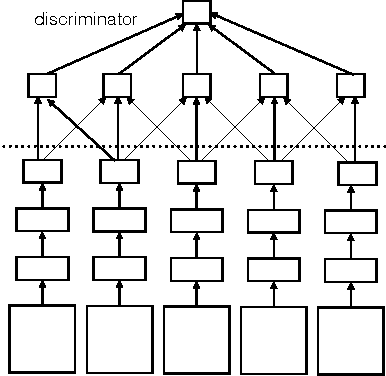
General unsupervised learning is a long-standing conceptual problem in machine learning. Supervised learning is successful because it can be solved by the minimization of the training error cost function. Unsupervised learning is not as successful, because the unsupervised objective may be unrelated to the supervised task of interest. For an example, density modelling and reconstruction have often been used for unsupervised learning, but they did not produced the sought-after performance gains, because they have no knowledge of the supervised tasks. In this paper, we present an unsupervised cost function which we name the Output Distribution Matching (ODM) cost, which measures a divergence between the distribution of predictions and distributions of labels. The ODM cost is appealing because it is consistent with the supervised cost in the following sense: a perfect supervised classifier is also perfect according to the ODM cost. Therefore, by aggressively optimizing the ODM cost, we are almost guaranteed to improve our supervised performance whenever the space of possible predictions is exponentially large. We demonstrate that the ODM cost works well on number of small and semi-artificial datasets using no (or almost no) labelled training cases. Finally, we show that the ODM cost can be used for one-shot domain adaptation, which allows the model to classify inputs that differ from the input distribution in significant ways without the need for prior exposure to the new domain.