 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTechnical Case Study of Privacy-Enhancing Technologies (PETs) for Public Health
Mar 13, 2026We present a technical case study on the Privacy-Enhancing Technologies (PETs) for Public Health Challenge, a collaborative effort to safely leverage sensitive private sector data for social impact, specifically pandemic management. The project utilized Differential Privacy (DP) to create realistic, privacy-preserved synthetic financial transaction data, which was then combined with public health and mobility datasets. This approach successfully addressed the critical hurdle of sharing sensitive financial information for research and policy. The analysis demonstrated that this synthetic, DP-protected data possesses significant spatial-temporal and predictive power for public health. Key outcomes include the development of six reusable tools and frameworks supporting diagnostic nowcasting (e.g., Hotspot Detection, Pandemic Adherence Monitoring) and predictive forecasting (e.g., Mobility Analysis, Contact Matrix Estimation) for epidemiological decision-making. The study provides best practices for advancing data sharing in a privacy-compliant manner.
Deep forecasting of translational impact in medical research
Oct 17, 2021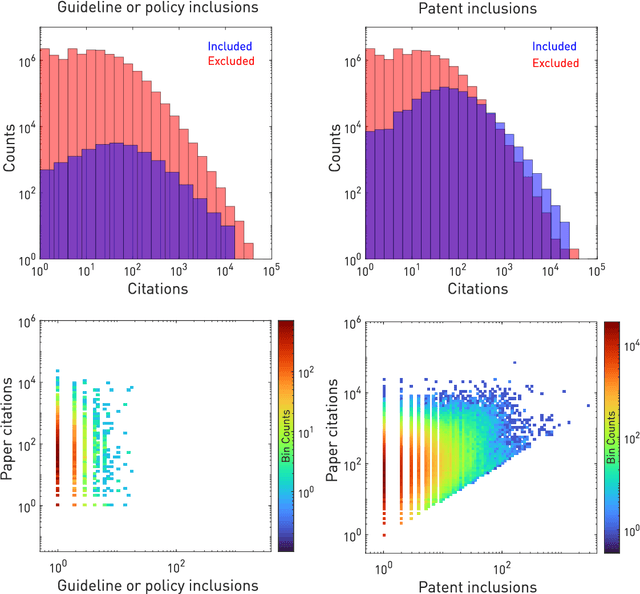
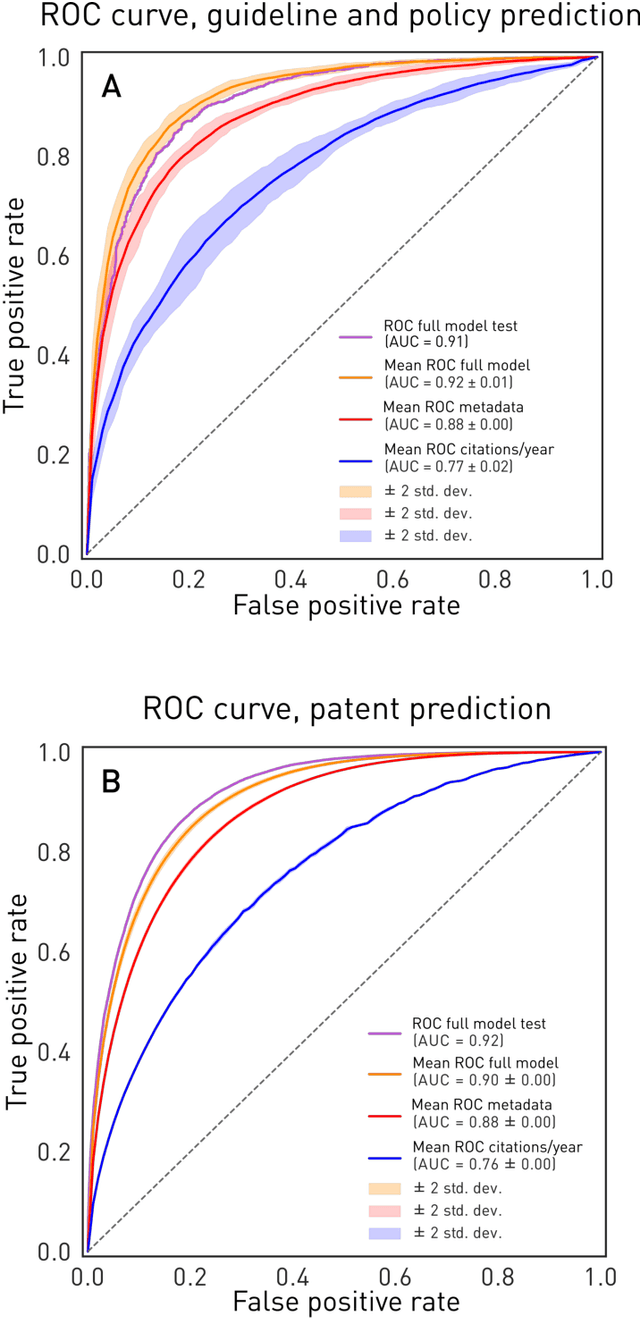
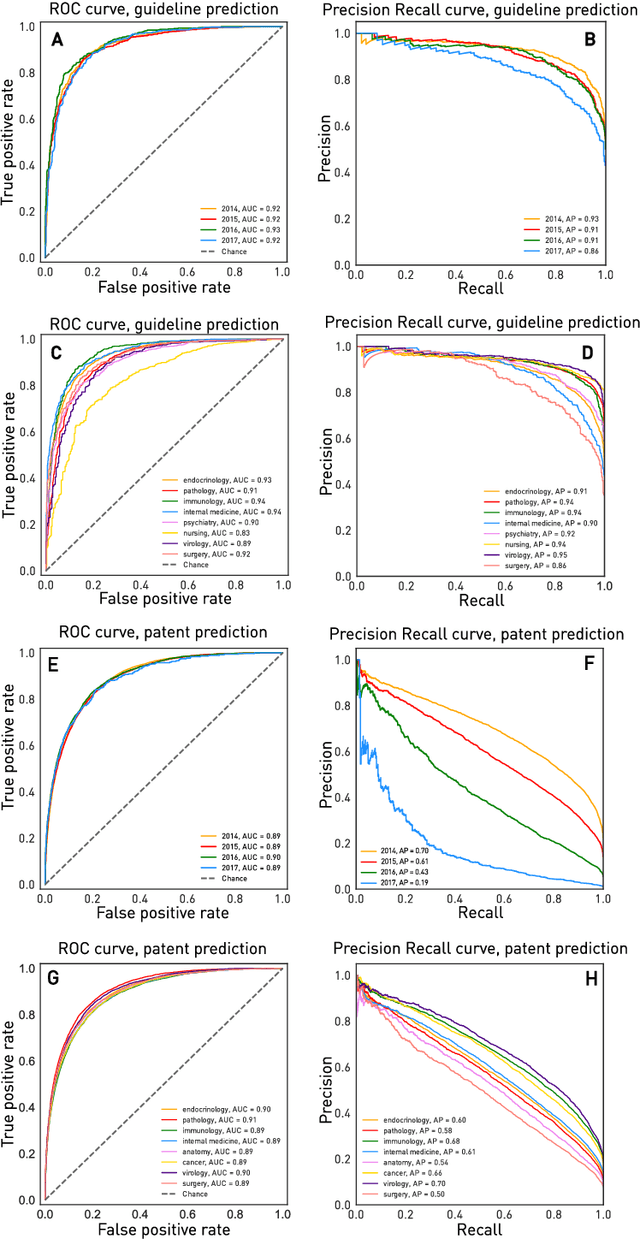
The value of biomedical research--a $1.7 trillion annual investment--is ultimately determined by its downstream, real-world impact. Current objective predictors of impact rest on proxy, reductive metrics of dissemination, such as paper citation rates, whose relation to real-world translation remains unquantified. Here we sought to determine the comparative predictability of future real-world translation--as indexed by inclusion in patents, guidelines or policy documents--from complex models of the abstract-level content of biomedical publications versus citations and publication meta-data alone. We develop a suite of representational and discriminative mathematical models of multi-scale publication data, quantifying predictive performance out-of-sample, ahead-of-time, across major biomedical domains, using the entire corpus of biomedical research captured by Microsoft Academic Graph from 1990 to 2019, encompassing 43.3 million papers across all domains. We show that citations are only moderately predictive of translational impact as judged by inclusion in patents, guidelines, or policy documents. By contrast, high-dimensional models of publication titles, abstracts and metadata exhibit high fidelity (AUROC > 0.9), generalise across time and thematic domain, and transfer to the task of recognising papers of Nobel Laureates. The translational impact of a paper indexed by inclusion in patents, guidelines, or policy documents can be predicted--out-of-sample and ahead-of-time--with substantially higher fidelity from complex models of its abstract-level content than from models of publication meta-data or citation metrics. We argue that content-based models of impact are superior in performance to conventional, citation-based measures, and sustain a stronger evidence-based claim to the objective measurement of translational potential.