 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional Lie Operator for Sentence Classification
Dec 18, 2025Traditional Convolutional Neural Networks have been successful in capturing local, position-invariant features in text, but their capacity to model complex transformation within language can be further explored. In this work, we explore a novel approach by integrating Lie Convolutions into Convolutional-based sentence classifiers, inspired by the ability of Lie group operations to capture complex, non-Euclidean symmetries. Our proposed models SCLie and DPCLie empirically outperform traditional Convolutional-based sentence classifiers, suggesting that Lie-based models relatively improve the accuracy by capturing transformations not commonly associated with language. Our findings motivate more exploration of new paradigms in language modeling.
Data Augmentation With Back translation for Low Resource languages: A case of English and Luganda
May 05, 2025



In this paper,we explore the application of Back translation (BT) as a semi-supervised technique to enhance Neural Machine Translation(NMT) models for the English-Luganda language pair, specifically addressing the challenges faced by low-resource languages. The purpose of our study is to demonstrate how BT can mitigate the scarcity of bilingual data by generating synthetic data from monolingual corpora. Our methodology involves developing custom NMT models using both publicly available and web-crawled data, and applying Iterative and Incremental Back translation techniques. We strategically select datasets for incremental back translation across multiple small datasets, which is a novel element of our approach. The results of our study show significant improvements, with translation performance for the English-Luganda pair exceeding previous benchmarks by more than 10 BLEU score units across all translation directions. Additionally, our evaluation incorporates comprehensive assessment metrics such as SacreBLEU, ChrF2, and TER, providing a nuanced understanding of translation quality. The conclusion drawn from our research confirms the efficacy of BT when strategically curated datasets are utilized, establishing new performance benchmarks and demonstrating the potential of BT in enhancing NMT models for low-resource languages.
* NLPIR '24: Proceedings of the 2024 8th International Conference on Natural Language Processing and Information Retrieval
Empirical Study of Symmetrical Reasoning in Conversational Chatbots
Jul 08, 2024This work explores the capability of conversational chatbots powered by large language models (LLMs), to understand and characterize predicate symmetry, a cognitive linguistic function traditionally believed to be an inherent human trait. Leveraging in-context learning (ICL), a paradigm shift enabling chatbots to learn new tasks from prompts without re-training, we assess the symmetrical reasoning of five chatbots: ChatGPT 4, Huggingface chat AI, Microsoft's Copilot AI, LLaMA through Perplexity, and Gemini Advanced. Using the Symmetry Inference Sentence (SIS) dataset by Tanchip et al. (2020), we compare chatbot responses against human evaluations to gauge their understanding of predicate symmetry. Experiment results reveal varied performance among chatbots, with some approaching human-like reasoning capabilities. Gemini, for example, reaches a correlation of 0.85 with human scores, while providing a sounding justification for each symmetry evaluation. This study underscores the potential and limitations of LLMs in mirroring complex cognitive processes as symmetrical reasoning.
Enhanced Labeling Technique for Reddit Text and Fine-Tuned Longformer Models for Classifying Depression Severity in English and Luganda
Jan 25, 2024Depression is a global burden and one of the most challenging mental health conditions to control. Experts can detect its severity early using the Beck Depression Inventory (BDI) questionnaire, administer appropriate medication to patients, and impede its progression. Due to the fear of potential stigmatization, many patients turn to social media platforms like Reddit for advice and assistance at various stages of their journey. This research extracts text from Reddit to facilitate the diagnostic process. It employs a proposed labeling approach to categorize the text and subsequently fine-tunes the Longformer model. The model's performance is compared against baseline models, including Naive Bayes, Random Forest, Support Vector Machines, and Gradient Boosting. Our findings reveal that the Longformer model outperforms the baseline models in both English (48%) and Luganda (45%) languages on a custom-made dataset.
Fast Training of NMT Model with Data Sorting
Aug 16, 2023



The Transformer model has revolutionized Natural Language Processing tasks such as Neural Machine Translation, and many efforts have been made to study the Transformer architecture, which increased its efficiency and accuracy. One potential area for improvement is to address the computation of empty tokens that the Transformer computes only to discard them later, leading to an unnecessary computational burden. To tackle this, we propose an algorithm that sorts translation sentence pairs based on their length before batching, minimizing the waste of computing power. Since the amount of sorting could violate the independent and identically distributed (i.i.d) data assumption, we sort the data partially. In experiments, we apply the proposed method to English-Korean and English-Luganda language pairs for machine translation and show that there are gains in computational time while maintaining the performance. Our method is independent of architectures, so that it can be easily integrated into any training process with flexible data lengths.
Building a Parallel Corpus and Training Translation Models Between Luganda and English
Jan 07, 2023Neural machine translation (NMT) has achieved great successes with large datasets, so NMT is more premised on high-resource languages. This continuously underpins the low resource languages such as Luganda due to the lack of high-quality parallel corpora, so even 'Google translate' does not serve Luganda at the time of this writing. In this paper, we build a parallel corpus with 41,070 pairwise sentences for Luganda and English which is based on three different open-sourced corpora. Then, we train NMT models with hyper-parameter search on the dataset. Experiments gave us a BLEU score of 21.28 from Luganda to English and 17.47 from English to Luganda. Some translation examples show high quality of the translation. We believe that our model is the first Luganda-English NMT model. The bilingual dataset we built will be available to the public.
Adversarial Training with Contrastive Learning in NLP
Sep 19, 2021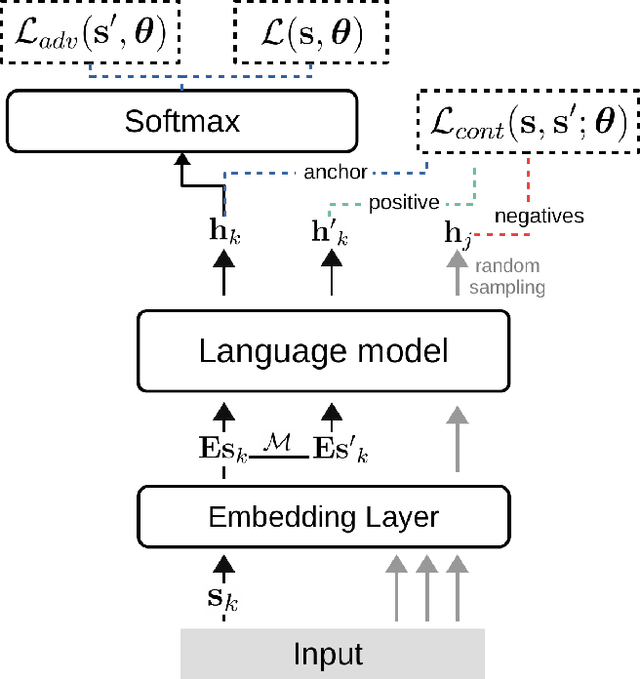

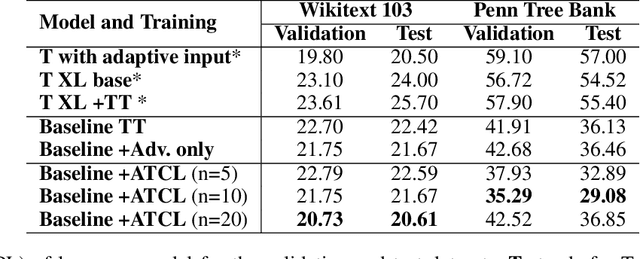
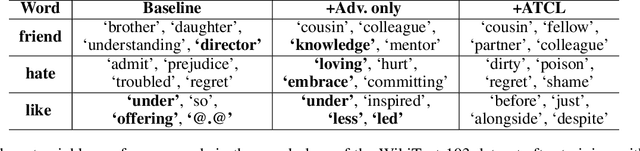
For years, adversarial training has been extensively studied in natural language processing (NLP) settings. The main goal is to make models robust so that similar inputs derive in semantically similar outcomes, which is not a trivial problem since there is no objective measure of semantic similarity in language. Previous works use an external pre-trained NLP model to tackle this challenge, introducing an extra training stage with huge memory consumption during training. However, the recent popular approach of contrastive learning in language processing hints a convenient way of obtaining such similarity restrictions. The main advantage of the contrastive learning approach is that it aims for similar data points to be mapped close to each other and further from different ones in the representation space. In this work, we propose adversarial training with contrastive learning (ATCL) to adversarially train a language processing task using the benefits of contrastive learning. The core idea is to make linear perturbations in the embedding space of the input via fast gradient methods (FGM) and train the model to keep the original and perturbed representations close via contrastive learning. In NLP experiments, we applied ATCL to language modeling and neural machine translation tasks. The results show not only an improvement in the quantitative (perplexity and BLEU) scores when compared to the baselines, but ATCL also achieves good qualitative results in the semantic level for both tasks without using a pre-trained model.
Deep Neural Networks and End-to-End Learning for Audio Compression
May 25, 2021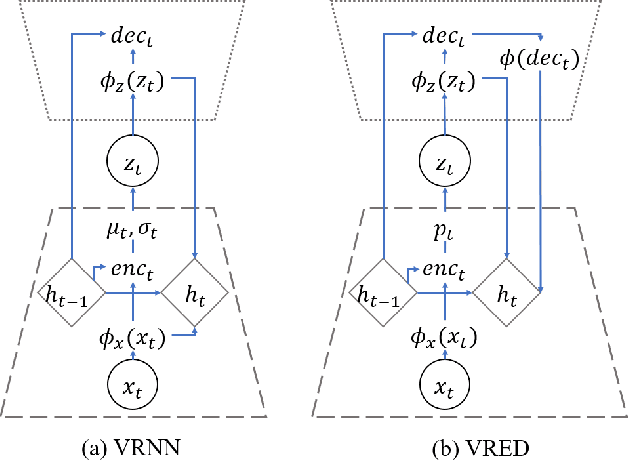
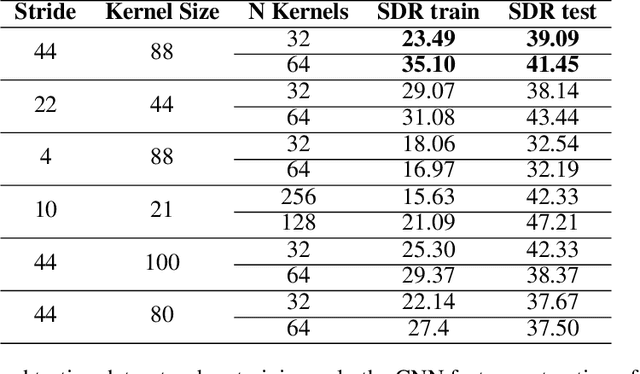
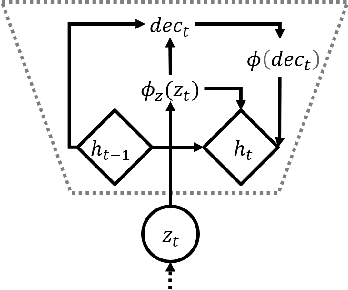
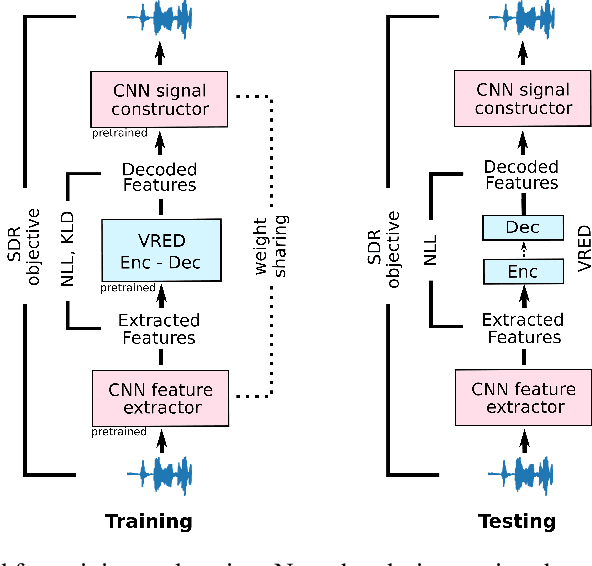
Recent achievements in end-to-end deep learning have encouraged the exploration of tasks dealing with highly structured data with unified deep network models. Having such models for compressing audio signals has been challenging since it requires discrete representations that are not easy to train with end-to-end backpropagation. In this paper, we present an end-to-end deep learning approach that combines recurrent neural networks (RNNs) within the training strategy of variational autoencoders (VAEs) with a binary representation of the latent space. We apply a reparametrization trick for the Bernoulli distribution for the discrete representations, which allows smooth backpropagation. In addition, our approach allows the separation of the encoder and decoder, which is necessary for compression tasks. To our best knowledge, this is the first end-to-end learning for a single audio compression model with RNNs, and our model achieves a Signal to Distortion Ratio (SDR) of 20.54.