 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Complexity of Decentralized Control of Markov Decision Processes
Jan 16, 2013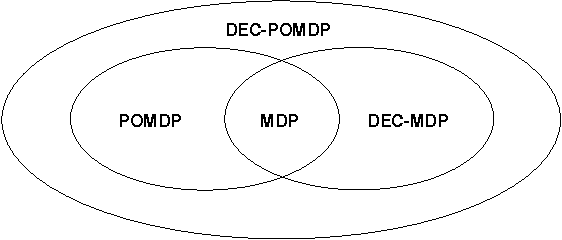
Planning for distributed agents with partial state information is considered from a decision- theoretic perspective. We describe generalizations of both the MDP and POMDP models that allow for decentralized control. For even a small number of agents, the finite-horizon problems corresponding to both of our models are complete for nondeterministic exponential time. These complexity results illustrate a fundamental difference between centralized and decentralized control of Markov processes. In contrast to the MDP and POMDP problems, the problems we consider provably do not admit polynomial-time algorithms and most likely require doubly exponential time to solve in the worst case. We have thus provided mathematical evidence corresponding to the intuition that decentralized planning problems cannot easily be reduced to centralized problems and solved exactly using established techniques.
Optimizing Memory-Bounded Controllers for Decentralized POMDPs
Jun 20, 2012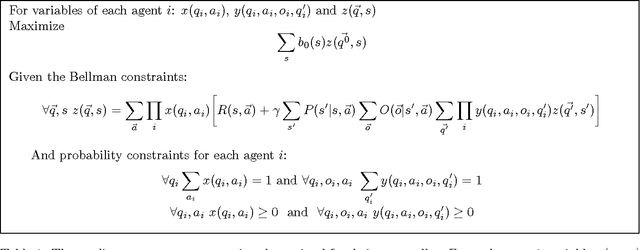
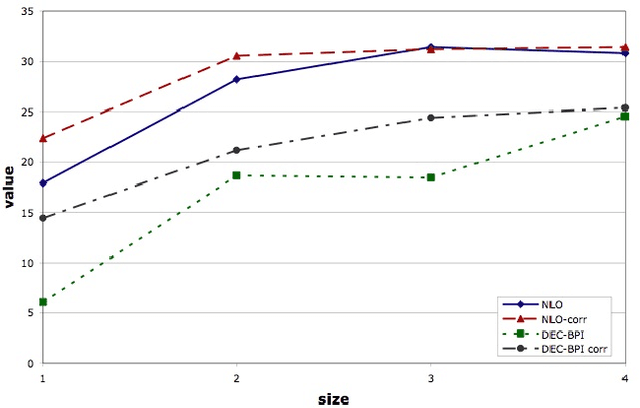
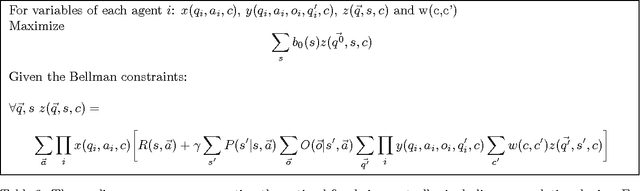
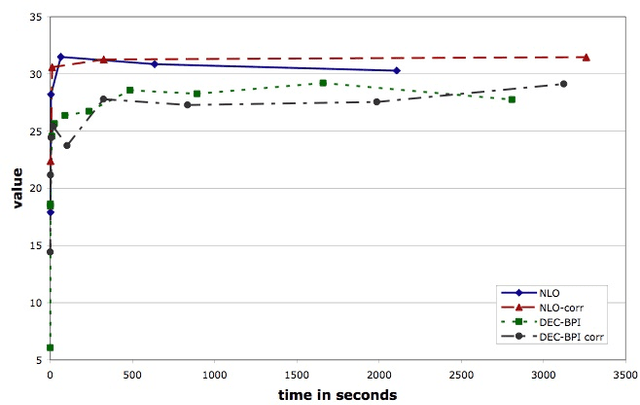
We present a memory-bounded optimization approach for solving infinite-horizon decentralized POMDPs. Policies for each agent are represented by stochastic finite state controllers. We formulate the problem of optimizing these policies as a nonlinear program, leveraging powerful existing nonlinear optimization techniques for solving the problem. While existing solvers only guarantee locally optimal solutions, we show that our formulation produces higher quality controllers than the state-of-the-art approach. We also incorporate a shared source of randomness in the form of a correlation device to further increase solution quality with only a limited increase in space and time. Our experimental results show that nonlinear optimization can be used to provide high quality, concise solutions to decentralized decision problems under uncertainty.