 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Detection of Mixture Distributions with applications to the Most Biased Coin Problem
Mar 25, 2016
This paper studies the trade-off between two different kinds of pure exploration: breadth versus depth. The most biased coin problem asks how many total coin flips are required to identify a "heavy" coin from an infinite bag containing both "heavy" coins with mean $\theta_1 \in (0,1)$, and "light" coins with mean $\theta_0 \in (0,\theta_1)$, where heavy coins are drawn from the bag with probability $\alpha \in (0,1/2)$. The key difficulty of this problem lies in distinguishing whether the two kinds of coins have very similar means, or whether heavy coins are just extremely rare. This problem has applications in crowdsourcing, anomaly detection, and radio spectrum search. Chandrasekaran et. al. (2014) recently introduced a solution to this problem but it required perfect knowledge of $\theta_0,\theta_1,\alpha$. In contrast, we derive algorithms that are adaptive to partial or absent knowledge of the problem parameters. Moreover, our techniques generalize beyond coins to more general instances of infinitely many armed bandit problems. We also prove lower bounds that show our algorithm's upper bounds are tight up to $\log$ factors, and on the way characterize the sample complexity of differentiating between a single parametric distribution and a mixture of two such distributions. As a result, these bounds have surprising implications both for solutions to the most biased coin problem and for anomaly detection when only partial information about the parameters is known.
Detecting People in Cubist Art
Sep 22, 2014
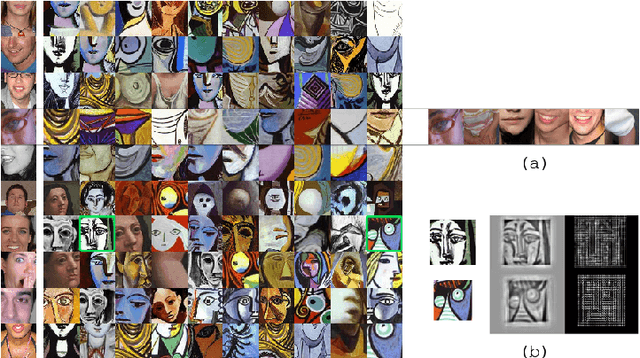
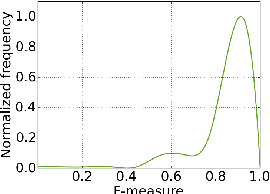

Although the human visual system is surprisingly robust to extreme distortion when recognizing objects, most evaluations of computer object detection methods focus only on robustness to natural form deformations such as people's pose changes. To determine whether algorithms truly mirror the flexibility of human vision, they must be compared against human vision at its limits. For example, in Cubist abstract art, painted objects are distorted by object fragmentation and part-reorganization, to the point that human vision often fails to recognize them. In this paper, we evaluate existing object detection methods on these abstract renditions of objects, comparing human annotators to four state-of-the-art object detectors on a corpus of Picasso paintings. Our results demonstrate that while human perception significantly outperforms current methods, human perception and part-based models exhibit a similarly graceful degradation in object detection performance as the objects become increasingly abstract and fragmented, corroborating the theory of part-based object representation in the brain.