 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLex-BERT: Enhancing BERT based NER with lexicons
Jan 02, 2021
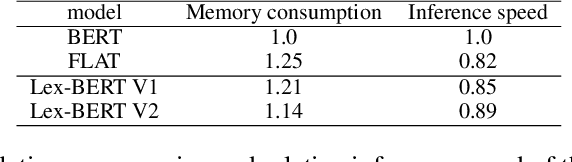
In this work, we represent Lex-BERT, which incorporates the lexicon information into Chinese BERT for named entity recognition (NER) tasks in a natural manner. Instead of using word embeddings and a newly designed transformer layer as in FLAT, we identify the boundary of words in the sentences using special tokens, and the modified sentence will be encoded directly by BERT. Our model does not introduce any new parameters and are more efficient than FLAT. In addition, we do not require any word embeddings accompanying the lexicon collection. Experiments on Ontonotes and ZhCrossNER show that our model outperforms FLAT and other baselines.
CMV-BERT: Contrastive multi-vocab pretraining of BERT
Dec 29, 2020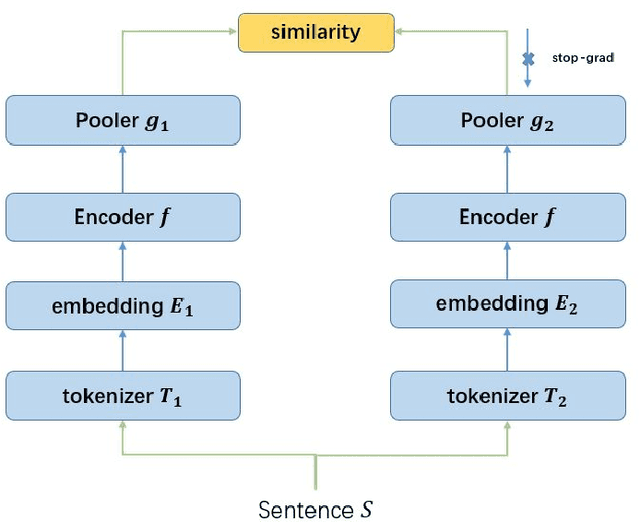
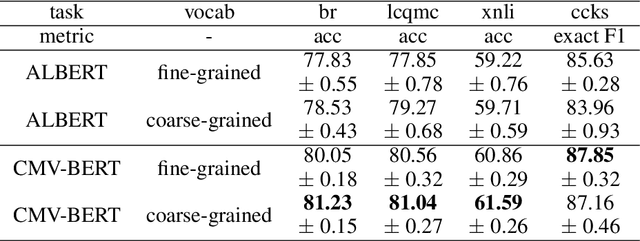
In this work, we represent CMV-BERT, which improves the pretraining of a language model via two ingredients: (a) contrastive learning, which is well studied in the area of computer vision; (b) multiple vocabularies, one of which is fine-grained and the other is coarse-grained. The two methods both provide different views of an original sentence, and both are shown to be beneficial. Downstream tasks demonstrate our proposed CMV-BERT are effective in improving the pretrained language models.