 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmerging Human-like Strategies for Semantic Memory Foraging in Large Language Models
Mar 02, 2026Both humans and Large Language Models (LLMs) store a vast repository of semantic memories. In humans, efficient and strategic access to this memory store is a critical foundation for a variety of cognitive functions. Such access has long been a focus of psychology and the computational mechanisms behind it are now well characterized. Much of this understanding has been gleaned from a widely-used neuropsychological and cognitive science assessment called the Semantic Fluency Task (SFT), which requires the generation of as many semantically constrained concepts as possible. Our goal is to apply mechanistic interpretability techniques to bring greater rigor to the study of semantic memory foraging in LLMs. To this end, we present preliminary results examining SFT as a case study. A central focus is on convergent and divergent patterns of generative memory search, which in humans play complementary strategic roles in efficient memory foraging. We show that these same behavioral signatures, critical to human performance on the SFT, also emerge as identifiable patterns in LLMs across distinct layers. Potentially, this analysis provides new insights into how LLMs may be adapted into closer cognitive alignment with humans, or alternatively, guided toward productive cognitive \emph{disalignment} to enhance complementary strengths in human-AI interaction.
Sparse Attention as Compact Kernel Regression
Jan 30, 2026Recent work has revealed a link between self-attention mechanisms in transformers and test-time kernel regression via the Nadaraya-Watson estimator, with standard softmax attention corresponding to a Gaussian kernel. However, a kernel-theoretic understanding of sparse attention mechanisms is currently missing. In this paper, we establish a formal correspondence between sparse attention and compact (bounded support) kernels. We show that normalized ReLU and sparsemax attention arise from Epanechnikov kernel regression under fixed and adaptive normalizations, respectively. More generally, we demonstrate that widely used kernels in nonparametric density estimation -- including Epanechnikov, biweight, and triweight -- correspond to $α$-entmax attention with $α= 1 + \frac{1}{n}$ for $n \in \mathbb{N}$, while the softmax/Gaussian relationship emerges in the limit $n \to \infty$. This unified perspective explains how sparsity naturally emerges from kernel design and provides principled alternatives to heuristic top-$k$ attention and other associative memory mechanisms. Experiments with a kernel-regression-based variant of transformers -- Memory Mosaics -- show that kernel-based sparse attention achieves competitive performance on language modeling, in-context learning, and length generalization tasks, offering a principled framework for designing attention mechanisms.
$\infty$-Video: A Training-Free Approach to Long Video Understanding via Continuous-Time Memory Consolidation
Jan 31, 2025



Current video-language models struggle with long-video understanding due to limited context lengths and reliance on sparse frame subsampling, often leading to information loss. This paper introduces $\infty$-Video, which can process arbitrarily long videos through a continuous-time long-term memory (LTM) consolidation mechanism. Our framework augments video Q-formers by allowing them to process unbounded video contexts efficiently and without requiring additional training. Through continuous attention, our approach dynamically allocates higher granularity to the most relevant video segments, forming "sticky" memories that evolve over time. Experiments with Video-LLaMA and VideoChat2 demonstrate improved performance in video question-answering tasks, showcasing the potential of continuous-time LTM mechanisms to enable scalable and training-free comprehension of long videos.
Transfer learning with causal counterfactual reasoning in Decision Transformers
Oct 27, 2021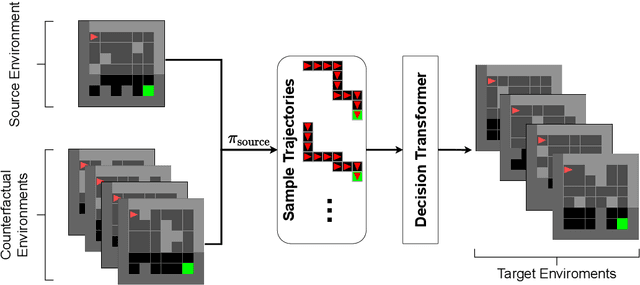

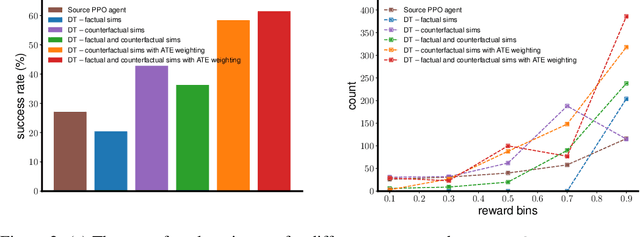

The ability to adapt to changes in environmental contingencies is an important challenge in reinforcement learning. Indeed, transferring previously acquired knowledge to environments with unseen structural properties can greatly enhance the flexibility and efficiency by which novel optimal policies may be constructed. In this work, we study the problem of transfer learning under changes in the environment dynamics. In this study, we apply causal reasoning in the offline reinforcement learning setting to transfer a learned policy to new environments. Specifically, we use the Decision Transformer (DT) architecture to distill a new policy on the new environment. The DT is trained on data collected by performing policy rollouts on factual and counterfactual simulations from the source environment. We show that this mechanism can bootstrap a successful policy on the target environment while retaining most of the reward.