 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOASIC: Occlusion-Agnostic and Severity-Informed Classification
Apr 05, 2026Severe occlusions of objects pose a major challenge for computer vision. We show that two root causes are (1) the loss of visible information and (2) the distracting patterns caused by the occluders. Our approach addresses both causes at the same time. First, the distracting patterns are removed at test-time, via masking of the occluding patterns. This masking is independent of the type of occlusion, by handling the occlusion through the lens of visual anomalies w.r.t. the object of interest. Second, to deal with less visual details, we follow standard practice by masking random parts of the object during training, for various degrees of occlusions. We discover that (a) it is possible to estimate the degree of the occlusion (i.e. severity) at test-time, and (b) that a model optimized for a specific degree of occlusion also performs best on a similar degree during test-time. Combining these two insights brings us to a severity-informed classification model called OASIC: Occlusion Agnostic Severity Informed Classification. We estimate the severity of occlusion for a test image, mask the occluder, and select the model that is optimized for the degree of occlusion. This strategy performs better than any single model optimized for any smaller or broader range of occlusion severities. Experiments show that combining gray masking with adaptive model selection improves $\text{AUC}_\text{occ}$ by +18.5 over standard training on occluded images and +23.7 over finetuning on unoccluded images.
Region of Interest Segmentation and Morphological Analysis for Membranes in Cryo-Electron Tomography
Feb 24, 2026Cryo-electron tomography (cryo-ET) enables high resolution, three-dimensional reconstruction of biological structures, including membranes and membrane proteins. Identification of regions of interest (ROIs) is central to scientific imaging, as it enables isolation and quantitative analysis of specific structural features within complex datasets. In practice, however, ROIs are typically derived indirectly through full structure segmentation followed by post hoc analysis. This limitation is especially apparent for continuous and geometrically complex structures such as membranes, which are segmented as single entities. Here, we developed TomoROIS-SurfORA, a two step framework for direct, shape-agnostic ROI segmentation and morphological surface analysis. TomoROIS performs deep learning-based ROI segmentation and can be trained from scratch using small annotated datasets, enabling practical application across diverse imaging data. SurfORA processes segmented structures as point clouds and surface meshes to extract quantitative morphological features, including inter-membrane distances, curvature, and surface roughness. It supports both closed and open surfaces, with specific considerations for open surfaces, which are common in cryo-ET due to the missing wedge effect. We demonstrate both tools using in vitro reconstituted membrane systems containing deformable vesicles with complex geometries, enabling automatic quantitative analysis of membrane contact sites and remodeling events such as invagination. While demonstrated here on cryo-ET membrane data, the combined approach is applicable to ROI detection and surface analysis in broader scientific imaging contexts.
Equivariant Eikonal Neural Networks: Grid-Free, Scalable Travel-Time Prediction on Homogeneous Spaces
May 21, 2025We introduce Equivariant Neural Eikonal Solvers, a novel framework that integrates Equivariant Neural Fields (ENFs) with Neural Eikonal Solvers. Our approach employs a single neural field where a unified shared backbone is conditioned on signal-specific latent variables - represented as point clouds in a Lie group - to model diverse Eikonal solutions. The ENF integration ensures equivariant mapping from these latent representations to the solution field, delivering three key benefits: enhanced representation efficiency through weight-sharing, robust geometric grounding, and solution steerability. This steerability allows transformations applied to the latent point cloud to induce predictable, geometrically meaningful modifications in the resulting Eikonal solution. By coupling these steerable representations with Physics-Informed Neural Networks (PINNs), our framework accurately models Eikonal travel-time solutions while generalizing to arbitrary Riemannian manifolds with regular group actions. This includes homogeneous spaces such as Euclidean, position-orientation, spherical, and hyperbolic manifolds. We validate our approach through applications in seismic travel-time modeling of 2D and 3D benchmark datasets. Experimental results demonstrate superior performance, scalability, adaptability, and user controllability compared to existing Neural Operator-based Eikonal solver methods.
A tomographic workflow to enable deep learning for X-ray based foreign object detection
Jan 28, 2022

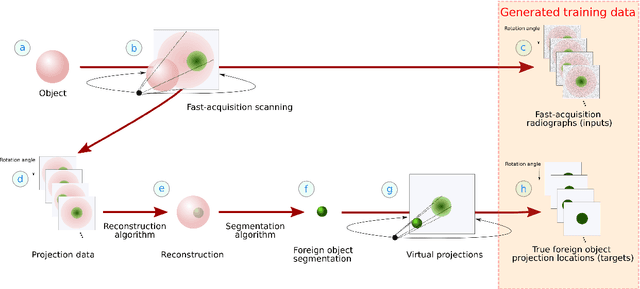

Detection of unwanted (`foreign') objects within products is a common procedure in many branches of industry for maintaining production quality. X-ray imaging is a fast, non-invasive and widely applicable method for foreign object detection. Deep learning has recently emerged as a powerful approach for recognizing patterns in radiographs (i.e., X-ray images), enabling automated X-ray based foreign object detection. However, these methods require a large number of training examples and manual annotation of these examples is a subjective and laborious task. In this work, we propose a Computed Tomography (CT) based method for producing training data for supervised learning of foreign object detection, with minimal labour requirements. In our approach, a few representative objects are CT scanned and reconstructed in 3D. The radiographs that have been acquired as part of the CT-scan data serve as input for the machine learning method. High-quality ground truth locations of the foreign objects are obtained through accurate 3D reconstructions and segmentations. Using these segmented volumes, corresponding 2D segmentations are obtained by creating virtual projections. We outline the benefits of objectively and reproducibly generating training data in this way compared to conventional radiograph annotation. In addition, we show how the accuracy depends on the number of objects used for the CT reconstructions. The results show that in this workflow generally only a relatively small number of representative objects (i.e., fewer than 10) are needed to achieve adequate detection performance in an industrial setting. Moreover, for real experimental data we show that the workflow leads to higher foreign object detection accuracies than with standard radiograph annotation.
Improving reproducibility in synchrotron tomography using implementation-adapted filters
Mar 15, 2021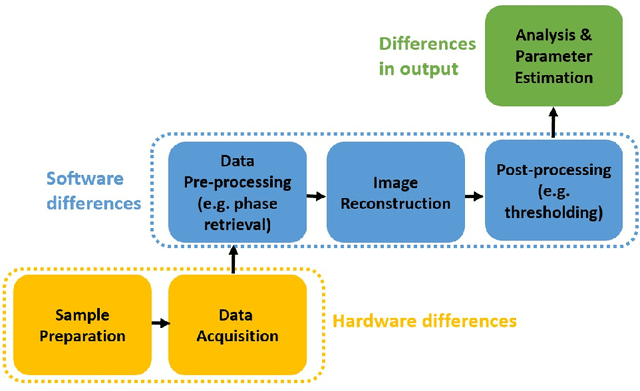
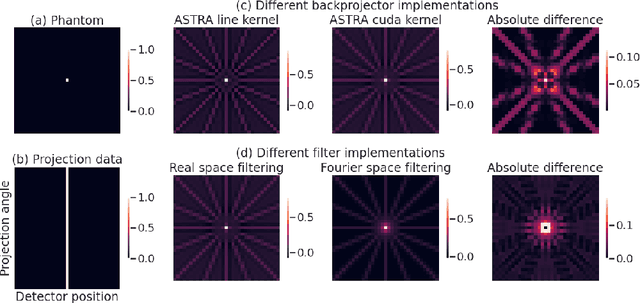
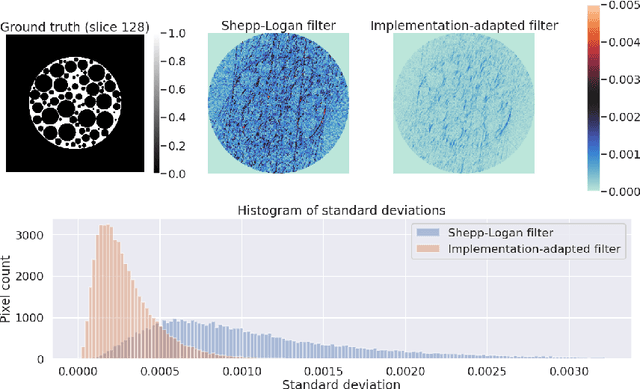
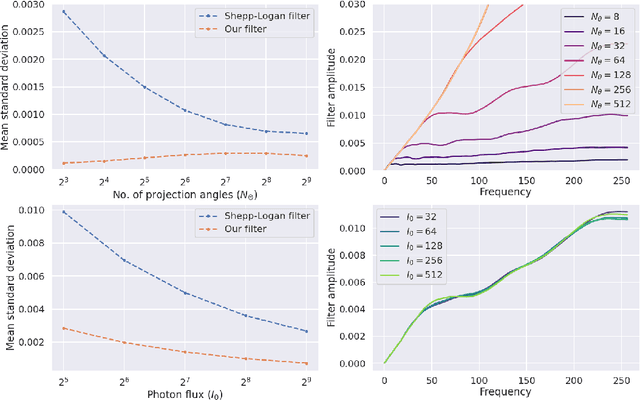
For reconstructing large tomographic datasets fast, filtered backprojection-type or Fourier-based algorithms are still the method of choice, as they have been for decades. These robust and computationally efficient algorithms have been integrated in a broad range of software packages. Despite the fact that the underlying mathematical formulas used for image reconstruction are unambiguous, variations in discretisation and interpolation result in quantitative differences between reconstructed images obtained from different software. This hinders reproducibility of experimental results. In this paper, we propose a way to reduce such differences by optimising the filter used in analytical algorithms. These filters can be computed using a wrapper routine around a black-box implementation of a reconstruction algorithm, and lead to quantitatively similar reconstructions. We demonstrate use cases for our approach by computing implementation-adapted filters for several open-source implementations and applying it to simulated phantoms and real-world data acquired at the synchrotron. Our contribution to a reproducible reconstruction step forms a building block towards a fully reproducible synchrotron tomography data processing pipeline.
LEAN: graph-based pruning for convolutional neural networks by extracting longest chains
Nov 13, 2020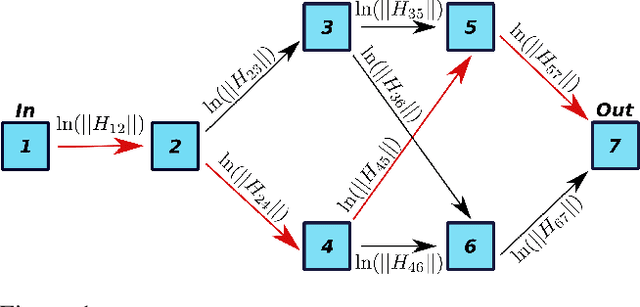
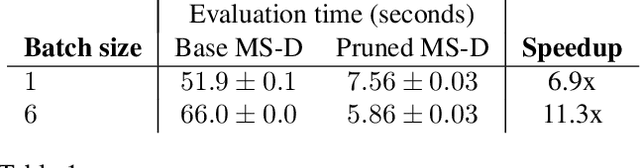
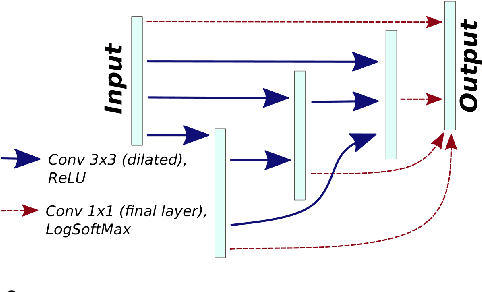
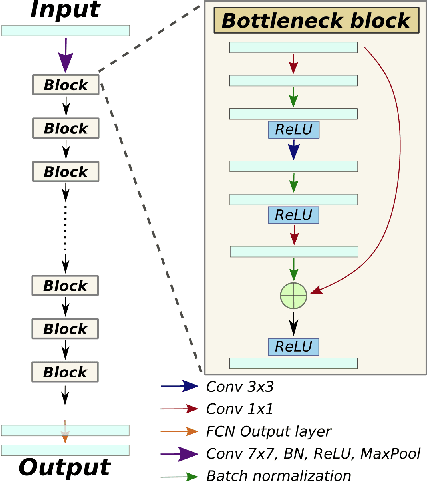
Convolutional neural networks (CNNs) have proven to be highly successful at a range of image-to-image tasks. CNNs can be computationally expensive, which can limit their applicability in practice. Model pruning can improve computational efficiency by sparsifying trained networks. Common methods for pruning CNNs determine what convolutional filters to remove by ranking filters on an individual basis. However, filters are not independent, as CNNs consist of chains of convolutions, which can result in sub-optimal filter selection. We propose a novel pruning method, LongEst-chAiN (LEAN) pruning, which takes the interdependency between the convolution operations into account. We propose to prune CNNs by using graph-based algorithms to select relevant chains of convolutions. A CNN is interpreted as a graph, with the operator norm of each convolution as distance metric for the edges. LEAN pruning iteratively extracts the highest value path from the graph to keep. In our experiments, we test LEAN pruning for several image-to-image tasks, including the well-known CamVid dataset. LEAN pruning enables us to keep just 0.5%-2% of the convolutions without significant loss of accuracy. When pruning CNNs with LEAN, we achieve a higher accuracy than pruning filters individually, and different pruned substructures emerge.