 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Metrics: Measuring Research Impact Through Large Language Model Memory
May 21, 2026Citation counts remain the dominant metric for assessing research impact, yet they suffer from well-documented limitations: temporal lag, disciplinary bias, and Matthew effects. Here we propose LLM-Metrics, a research-impact assessment metric derived from the parametric memory of large language models (LLMs). The central hypothesis is that high-impact papers receive greater exposure in the academic community, that this exposure enters LLM training data in textual form, and that models consequently form stronger parametric memory of these papers. We designed four types of multiple-choice probes, covering title recognition, author recognition, method recognition, and venue recognition, and evaluated 549 computer science papers published in 2023-2024 across 17 LLMs spanning 0.5B to 72B parameters from six vendors. Of the 17 models, 15 produced positive predictions, 9 of which were significant at p less than 0.05, with an overall Spearman correlation of rho = 0.1495 and p = 0.0004 against citation counts. Three additional findings support the proposed mechanism. First, the predictive signal was stronger for 2024 papers, rho = 0.1880, whose citation counts were near zero at model-training time, reducing the plausibility of a simple reverse-causality explanation. Second, author-recognition probes showed the strongest discriminative power, consistent with an exposure-driven memory mechanism. Third, model scale and predictive power were non-monotonic: a 3B-parameter model, Llama-3.2-3B-Instruct, with rho = 0.1829, outperformed most larger models, supporting a selective-memory hypothesis in which the limited capacity of smaller models can serve as an effective information filter. LLM-Metrics offers a real-time, cross-disciplinary, citation-independent paradigm for research assessment.
RevOrder: A Novel Method for Enhanced Arithmetic in Language Models
Feb 06, 2024This paper presents RevOrder, a novel technique aimed at improving arithmetic operations in large language models (LLMs) by reversing the output digits in addition, subtraction, and n-digit by 1-digit (nD by 1D) multiplication tasks. Our method significantly reduces the Count of Sequential Intermediate Digits (CSID) to $\mathcal{O}(1)$, a new metric we introduce to assess equation complexity. Through comprehensive testing, RevOrder not only achieves perfect accuracy in basic arithmetic operations but also substantially boosts LLM performance in division tasks, particularly with large numbers where traditional models struggle. Implementation of RevOrder is cost-effective for both training and inference phases. Moreover, applying RevOrder to fine-tune the LLaMA2-7B model on the GSM8K math task results in a considerable improvement, reducing equation calculation errors by 46% and increasing overall scores from 41.6 to 44.4.
Pre-train and Learn: Preserve Global Information for Graph Neural Networks
Oct 27, 2019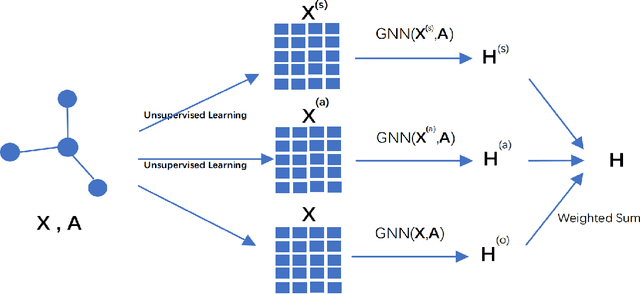
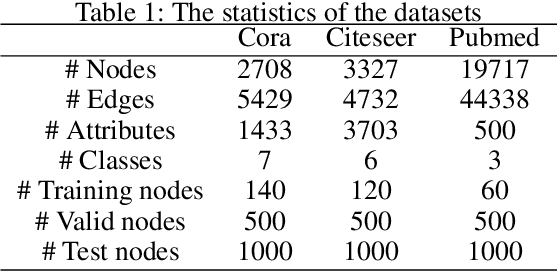
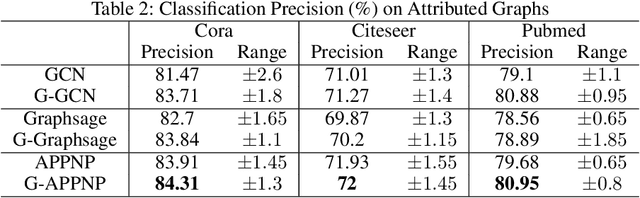
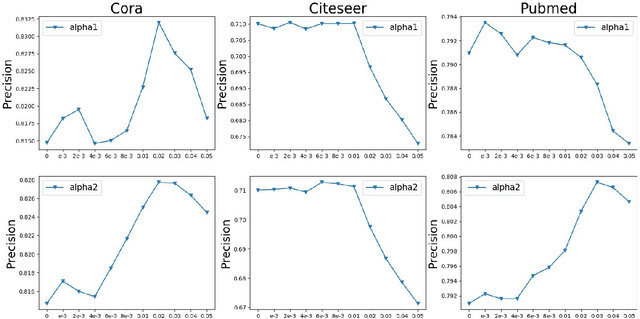
Graph neural networks (GNNs) have shown great power in learning on attributed graphs. However, it is still a challenge for GNNs to utilize information faraway from the source node. Moreover, general GNNs require graph attributes as input, so they cannot be appled to plain graphs. In the paper, we propose new models named G-GNNs (Global information for GNNs) to address the above limitations. First, the global structure and attribute features for each node are obtained via unsupervised pre-training, which preserve the global information associated to the node. Then, using the global features and the raw network attributes, we propose a parallel framework of GNNs to learn different aspects from these features. The proposed learning methods can be applied to both plain graphs and attributed graphs. Extensive experiments have shown that G-GNNs can outperform other state-of-the-art models on three standard evaluation graphs. Specially, our methods establish new benchmark records on Cora (84.31\%) and Pubmed (80.95\%) when learning on attributed graphs.
Going Wider: Recurrent Neural Network With Parallel Cells
May 03, 2017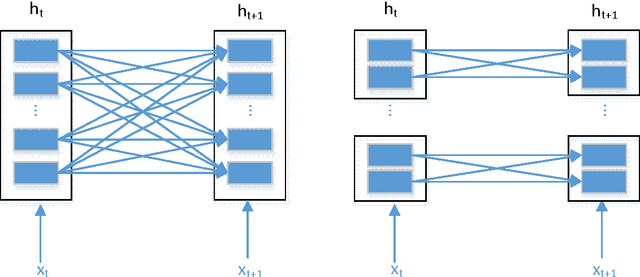
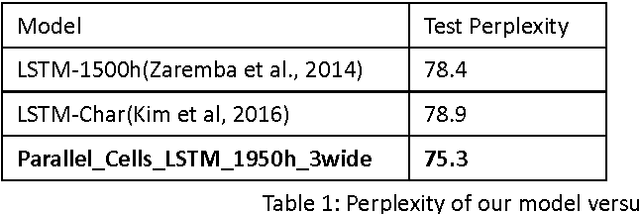
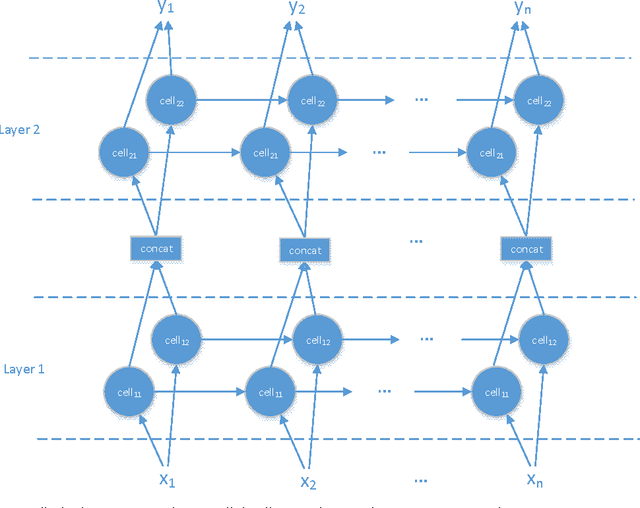
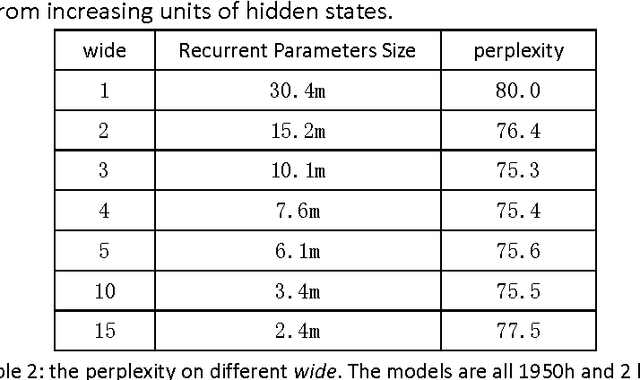
Recurrent Neural Network (RNN) has been widely applied for sequence modeling. In RNN, the hidden states at current step are full connected to those at previous step, thus the influence from less related features at previous step may potentially decrease model's learning ability. We propose a simple technique called parallel cells (PCs) to enhance the learning ability of Recurrent Neural Network (RNN). In each layer, we run multiple small RNN cells rather than one single large cell. In this paper, we evaluate PCs on 2 tasks. On language modeling task on PTB (Penn Tree Bank), our model outperforms state of art models by decreasing perplexity from 78.6 to 75.3. On Chinese-English translation task, our model increases BLEU score for 0.39 points than baseline model.